
(FPT2025)Fusion SoC Workshop
The Front-End Tools
引言
在异构计算领域,传统的编译器流程(如 GCC/Clang)主要负责将高级语言转换为线性的机器指令流。
然而,对于 CGRA 这种空间架构而言,编译器面临着完全不同的挑战:它不仅需要生成指令,更需要从源码中提取数据流图(DFG)或控制数据流图(CDFG),以便映射到二维的处理单元(PE)阵列上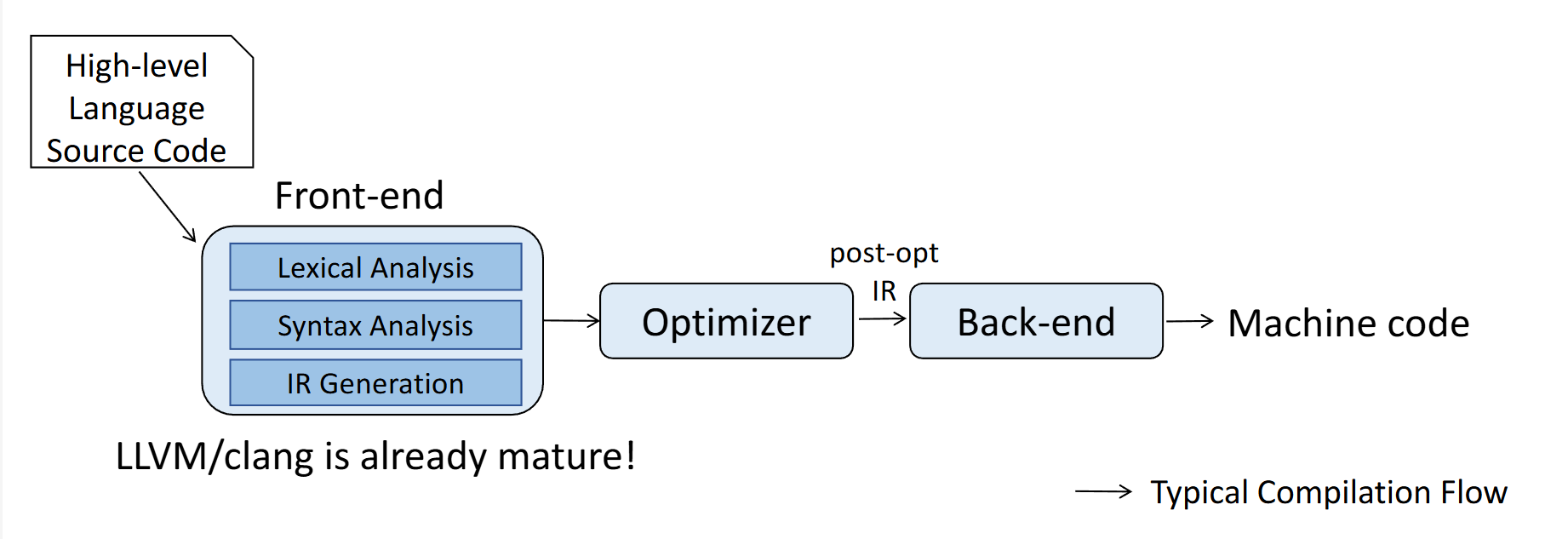

传统编译流程与 CGRA 编译流程的对比,后者需要生成 DFG/CDFG 并进行空间映射
Fusion CGRA SoC 是一个典型的异构系统,包含 RISC-V 主控核、DMA 控制器、多库 Scratchpad Memory (SPM) 以及核心的 CGRA 阵列。为了充分利用这一硬件的性能,需要解决三大问题:
- 控制流的复杂性:如何将高级语言中的嵌套循环和条件分支高效映射到硬件?
- 算子的专用性:如何自动提取并利用硬件提供的特殊功能单元(如自动地址生成、累加器)?
- 优化的全局性:如何从单纯的内核加速扩展到整个 SoC 的系统级流水线优化?
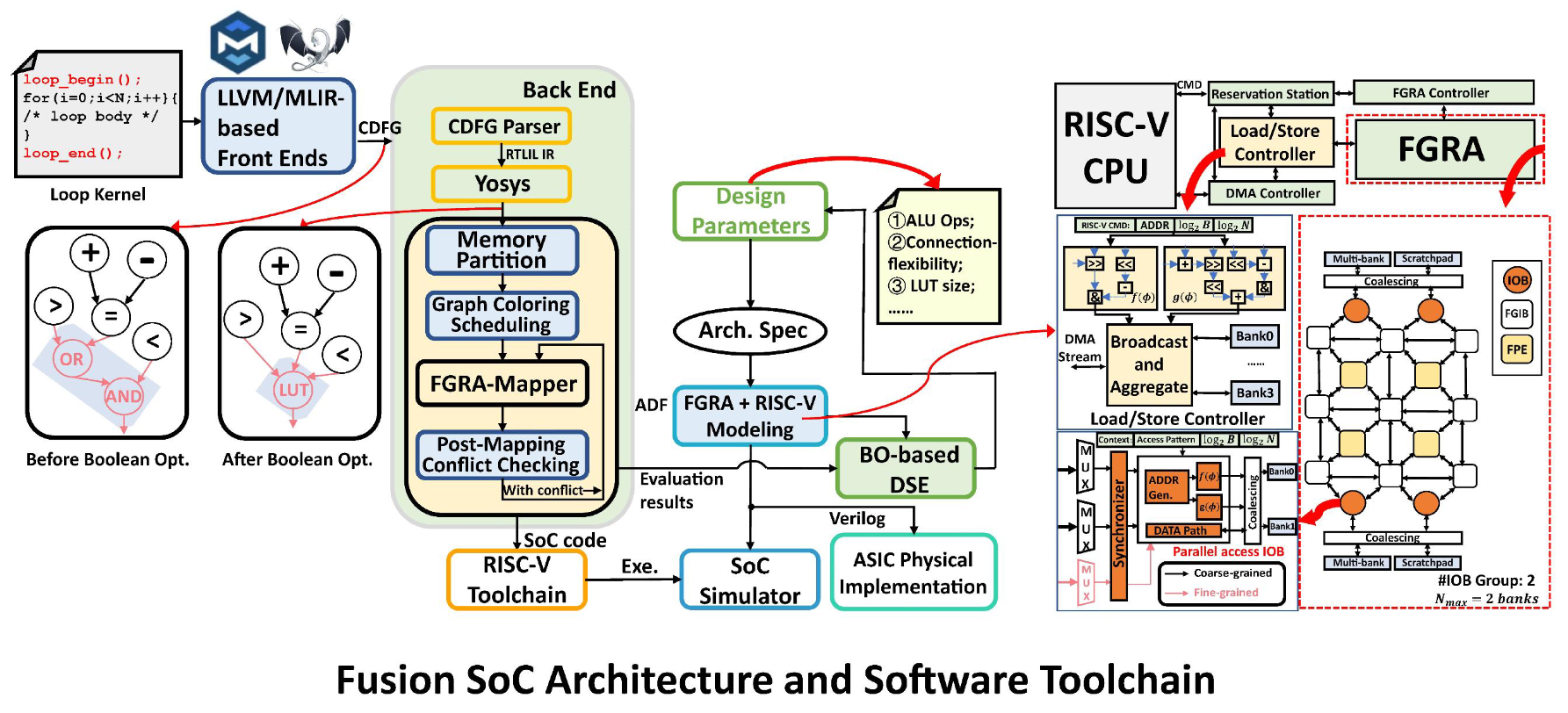
Fusion SoC 的硬件架构概览,展示了 RISC-V Host 与 CGRA Array 的交互关系
第一阶段:CO-Compiler —— 基于 LLVM 的通用性突破
CO-Compiler (ASP-DAC 2024) 选择构建在成熟的 LLVM 生态之上。LLVM 的中间表示(IR)虽然通过静态单赋值(SSA)形式很好地表达了数据依赖,但其控制流表示(如 Phi 节点)并不直接兼容 CGRA 的空间映射。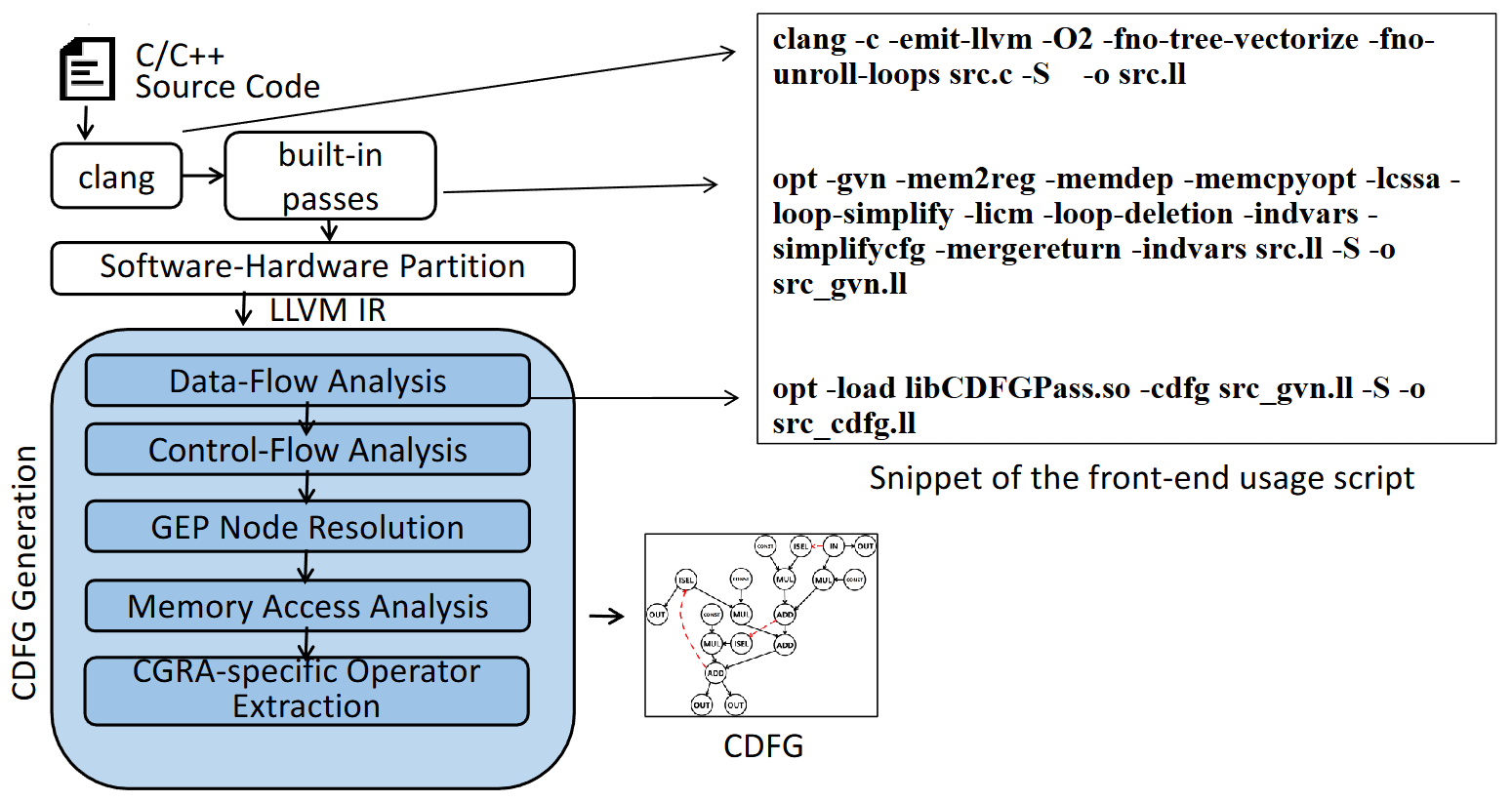
从 LLVM IR 到 CDFG:控制流的硬件化重构
LLVM IR 使用 br(分支跳转)和 Phi 指令来管理控制流,这在冯·诺依曼架构上是最高效的。但在 CGRA 上,我们需要将这些控制流转换为数据通路上的选择逻辑。
CO-Compiler 引入了一套基于支配树(Dominator Tree)的分析算法。编译器遍历基本块(Basic Block),分析数据在不同路径下的汇聚情况,将软件层面的 Phi 指令转换为硬件可执行的 SELECT(多路选择器)节点。
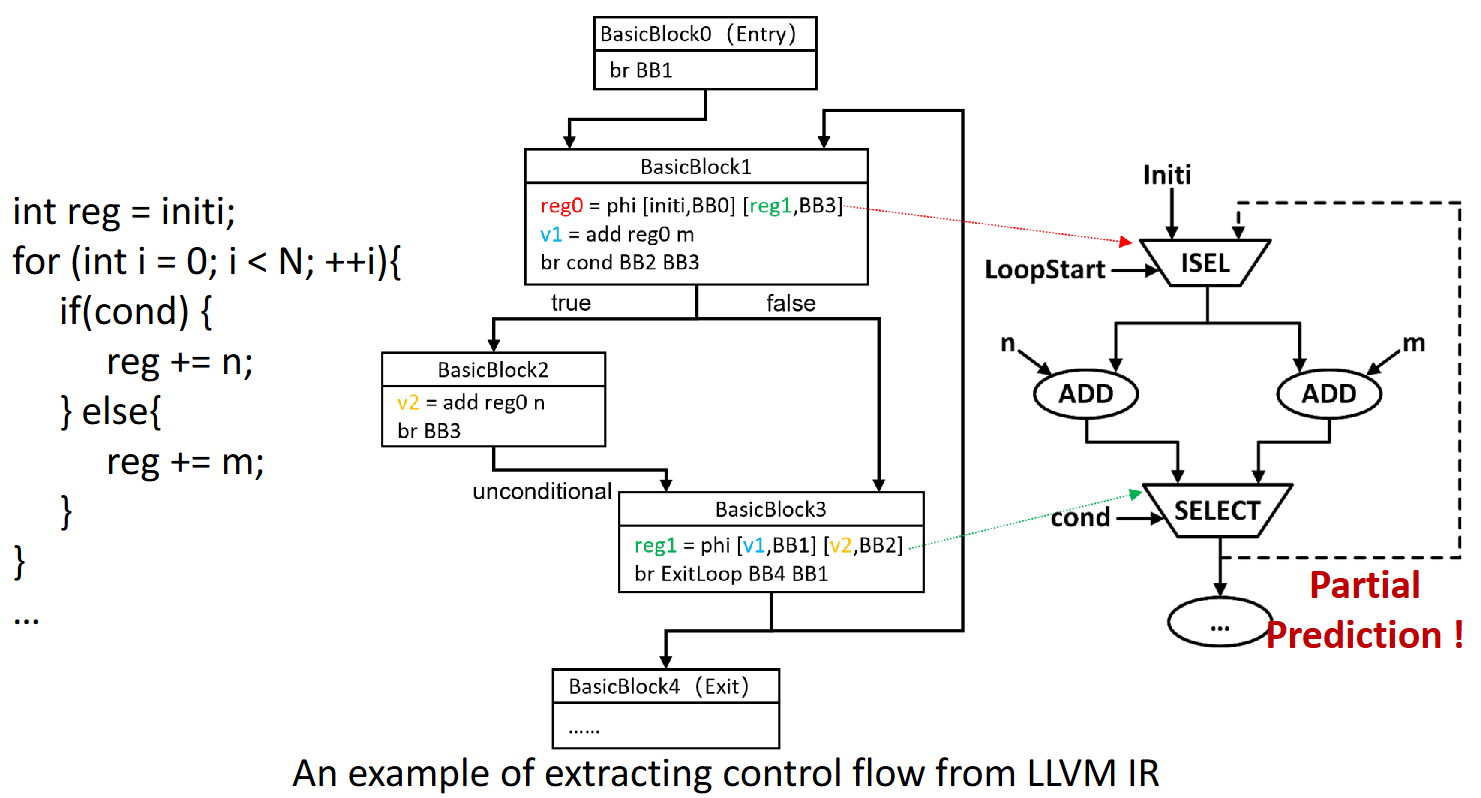
该图展示如何从 LLVM 的 Basic Blocks 和 Phi 节点推导出带有 SELECT 节点的 CDFG
更进一步,为了处理循环中的状态更新,将 Phi 节点细分为两类:
- General Phi:用于普通的
if-else条件选择,映射为由条件信号控制的 MUX。 - Cumulative Phi:用于循环迭代中变量的自我更新(如
i++或sum += a[i])。这类Phi节点依赖于回边(Back-edge),在硬件上被转换为由LoopStart信号控制的初始值选择逻辑,从而支持任意层级的嵌套循环
GEP 节点解析与线性访存模式提取
1. 基于 LLVM IR 的 GEP 指令解析
在 LLVM IR 中,数组访问通常通过 GetElementPtr (GEP) 指令完成。如果直接将 GEP 指令映射为 PE 上的加法和乘法运算,将会消耗大量的计算资源。GEP 指令通过基地址(Base Pointer)和一系列索引(Indices)来计算目标元素的内存地址。
CO-Compiler 的前端分析 Pass 首先扫描循环体内的所有 GEP 指令,解析其操作数结构。根据 C/C++ 的多维数组内存布局,一个典型的地址计算公式可以表示为
其中,N 为数组维度,DimScale_i 为第 i 维的跨度(由数组类型决定),Index_i 为该维度的下标。
CO-Compiler 实现了一套线性访存分析(Linear Memory Access Analysis)机制。它检查 GEP 指令是否满足关于循环归纳变量的仿射变换关系。
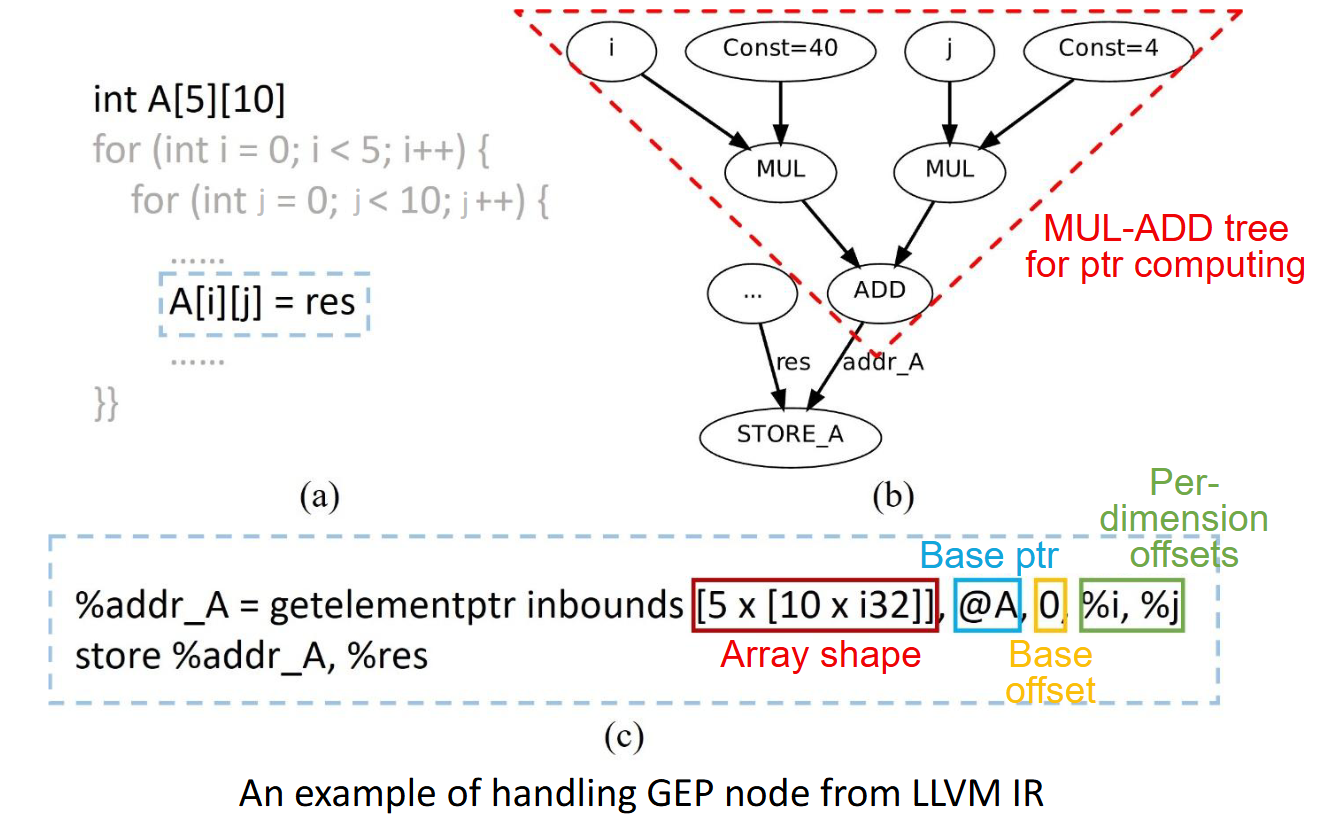
该图展示编译器对 LLVM IR 中的 getelementptr 指令进行解析,识别基地址、数组维度形状(Array Shape)以及各维度的偏移量。
2. 仿射变换与线性性验证
为了确定该访存操作是否能被硬件专用的地址生成单元(AGU)支持,编译器需要验证地址表达式是否关于循环归纳变量(Induction Variable)构成仿射变换(Affine Transformation)。
判定为“线性访存”需满足以下三个严格条件:
- 计算封闭性:地址表达式完全由常数、循环不变量(Loop-invariant)和循环归纳变量构成。
- 线性步进:循环归纳变量在迭代过程中呈线性变化(如
i++或i += c)。 - 仿射映射:从归纳变量到最终内存地址的映射关系是线性的。
当满足上述条件时,复杂的地址计算逻辑可以被简化为一个线性方程: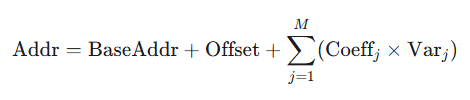
其中 $M$ 是循环嵌套层级,$Coeff_j$ 是第 $j$ 层循环变量 $Var_j$ 对应的线性系数
该图展示多层嵌套循环中,循环变量与最终物理地址之间的数学映射关系
3. 硬件参数提取与 AGU 配置
一旦确认为线性访存模式,CO-Compiler 将不再生成用于计算地址的计算节点(Add/Mul Nodes),而是直接提取描述该访存模式的三组关键参数,用于配置 CGRA 的输入/输出单元(IO Unit)或地址生成单元:
- 起始地址(Start Address):由基地址和归纳变量的初始值确定的首个访问地址。
- 步长(Stride):对应每一层循环迭代时,物理地址的跳变值。对于多层嵌套循环,编译器会提取出一组 Stride 值(如 Stride1, Stride2…),分别对应内层和外层循环。
- 计数值(Count):对应每一层循环的迭代次数。

4. 资源优化的收益与回退机制
通过上述转换,原本需要由多个 PE 级联完成的乘加树(Mul-Add Tree)运算,被转化为静态的配置参数。
- 资源释放:实验表明,这一优化显著减少了 PE 的占用率,使得更多 PE 可用于核心的数据处理(如卷积、矩阵乘法),从而提升了算力的有效利用率。
- 回退机制:对于无法通过线性分析的不规则访存(Irregular Memory Access),例如间接寻址
A[B[i]]或非线性下标A[i*i],编译器会自动回退到保守策略,生成完整的乘加运算数据流图,并映射到 PE 阵列执行,以确保程序的正确性。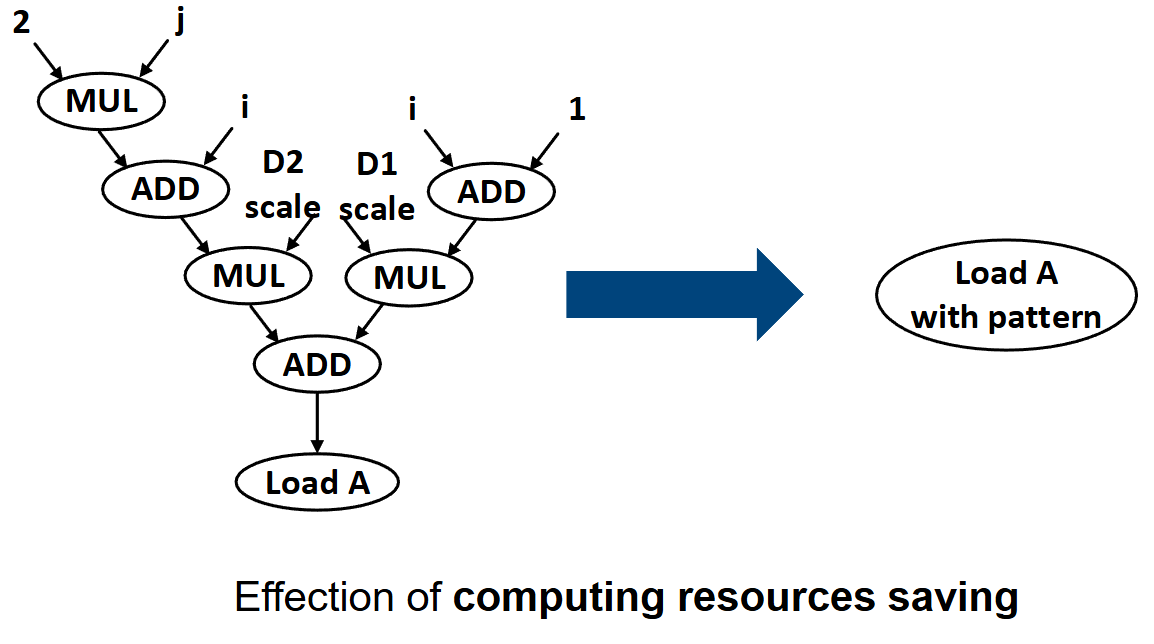
对比图,左侧是未优化前占用大量 PE 的地址计算树,右侧是优化后仅需配置参数的 Load 节点
专用算子提取
为了进一步降低 Initiation Interval (II),CO-Compiler 能够自动识别高级语言中的特定模式并映射到专用硬件算子:
- 累加器序列(Accumulation Series):识别带有反馈路径的加法链,映射为硬件累加器。如图所示将通用的加法循环逻辑转换为专用 Accumulator 硬件算子的过程。

- 条件访存(Conditional Memory Access):将受控的 Load/Store 转换为 CLOAD/CSTORE,利用 Predicate 信号直接控制内存读写使能,避免了复杂的控制流分歧。如图展示如何将 if-else 控制下的内存访问转换为带使能端的 CStore/CLoad 操作。

第二阶段:Adora Compiler —— 基于 MLIR 的端到端全栈优化
随着 AI 和张量计算需求的增加,LLVM 底层 IR 在进行高层循环变换(如 Tiling, Fusion)时显得力不从心。为此,开发了 Adora Compiler (DAC 2025),利用 MLIR 的多层抽象能力,实现了从算子级到系统级的全栈优化。这是MLIR 工具链流程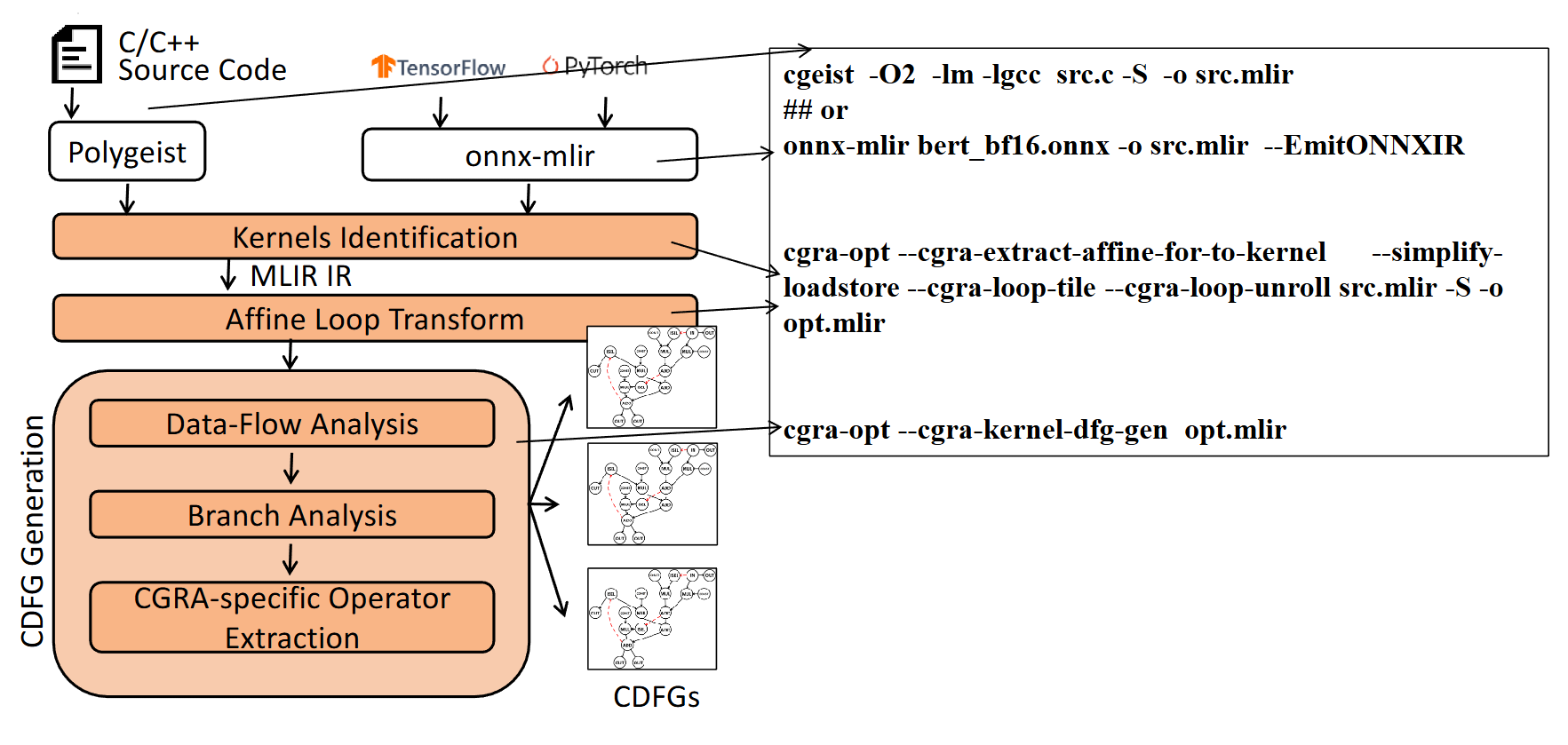 该图对比 LLVM 与 MLIR 在抽象层级、可扩展性及优化能力上的差异。
该图对比 LLVM 与 MLIR 在抽象层级、可扩展性及优化能力上的差异。
基于多面体模型的数据流层级优化
Adora 充分利用 MLIR 的 Affine Dialect,在多面体模型(Polyhedral Model)的理论框架下进行激进的循环变换。
- 智能循环分块(Loop Tiling):针对 CGRA 有限的 SPM 容量,Adora 自动计算最优分块大小,确保数据局部性,大幅减少 DRAM 访问。
- 展开与压缩(Unroll-and-Jam):为了提升并行度,Adora 对循环进行展开。更重要的是,它通过依赖多面体分析(Dependency Polyhedron)检测潜在的存储体冲突(Bank Conflict),智能选择展开策略。
- 循环重排(Loop Reordering):自动搜索最优的循环嵌套顺序,最大化数据复用。
该图展示经过 MLIR 优化后生成的复杂 CDFG 实例(以 MatMul 为例)。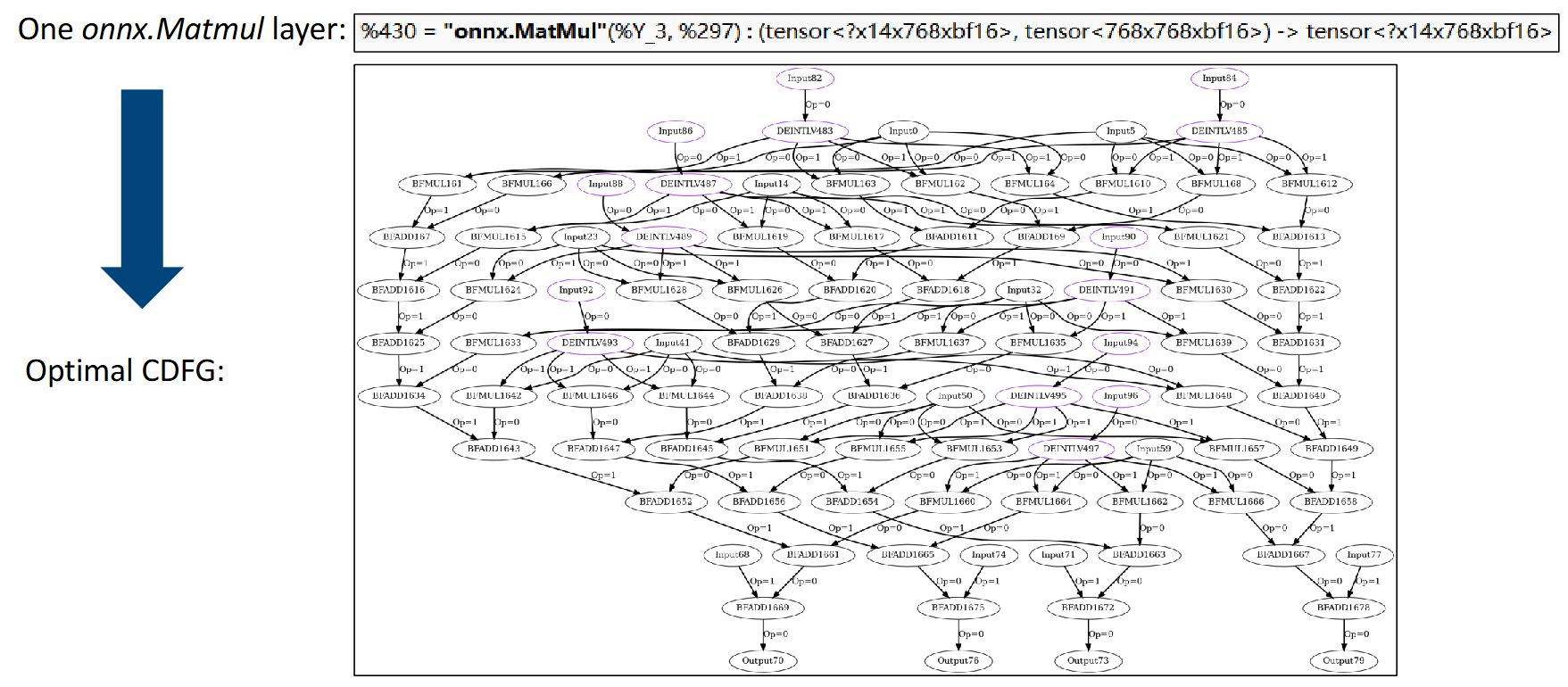
任务流层级优化:超越内核
Adora 还通过任务流优化(Task-Flow Optimization)来提升整个 SoC 的运行效率。
- 软件流水线与乒乓缓存(Ping-Pong Buffering):编译器生成双缓冲机制,利用 SoC 的乱序执行能力,在计算当前数据块的同时,通过 DMA 预取下一块数据。这种细粒度的流水线设计有效掩盖了数据传输延迟。
- 指令去重:通过分析任务间的依赖关系,Adora 能够剔除冗余的配置指令和数据搬运请求。
AI 部署流程与自动化探索
Adora 提供了从 PyTorch/ONNX 到 CGRA 的完整自动化路径。对于循环变换带来的巨大设计空间(分块大小 x 展开因子 x 重排顺序),Adora 摒弃了传统的遗传算法,设计了一套基于帕累托最优(Pareto-optimal)的快速搜索算法,以资源利用率和通信量为双重指标,实现了 6 倍以上的搜索速度提升。
该图展示 ResNet18 的层级拆解、计算核提取以及在 CGRA 上的流水线执行过程。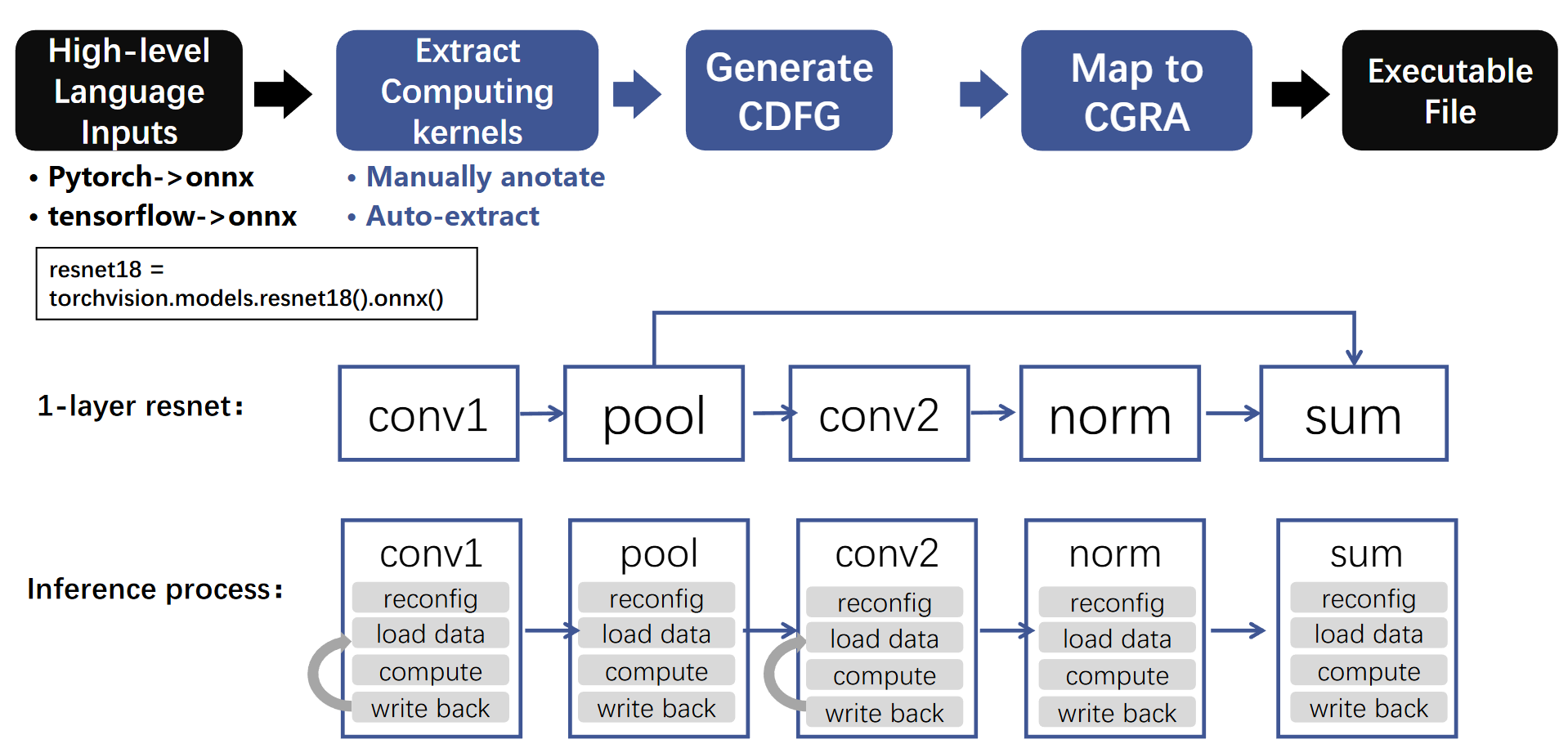
总结
- LLVM 工具链证明了 CGRA 可以像通用处理器一样,处理复杂的 C/C++ 嵌套循环与不规则控制流,为通用计算卸载提供了可能。
- MLIR 工具链则展示了在 AI 与张量计算领域,通过高层语义分析与系统级流水线编排,软硬件协同设计可以达到媲美甚至超越 FPGA 的能效比。
该图详细对比总结两个工具链的优势、共同点与适用场景
Architecture and Software Optimizations
CGRA 的核心痛点
传统的 CGRA 主要由许多的粗粒度的 PE (处理单元)组成,每个 PE 里有一个 ALU(算数逻辑单元)做加减乘除。它们比较适合做规整的矩阵运算。
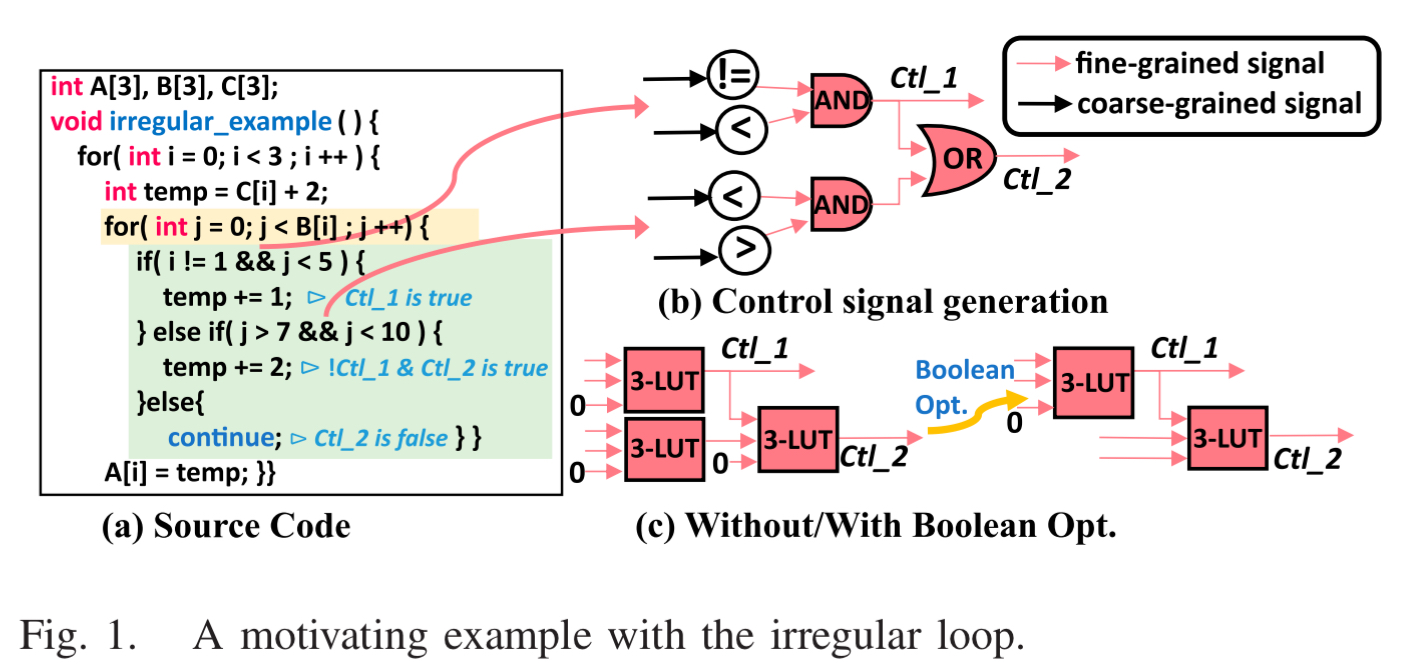
但是在实际的程序中,很多循环是不规则的,包含:
- 动态边界循环:循环次数编译时不知道 (例如
while(i<N),N 时变量)
- 动态边界循环:循环次数编译时不知道 (例如
if-then-else(ITE):循环体中有复杂的条件分支
- 复杂的内存依赖:比如
A[B[i]]这种间接寻址
COFFA 解决方案:软硬兼施
COFFA 提出了“Fused-Grained”(融合粒度)的概念
硬件架构:FGRA
COFFA 设计了一种特殊的加速器,集成在 RISC-V SoC 中
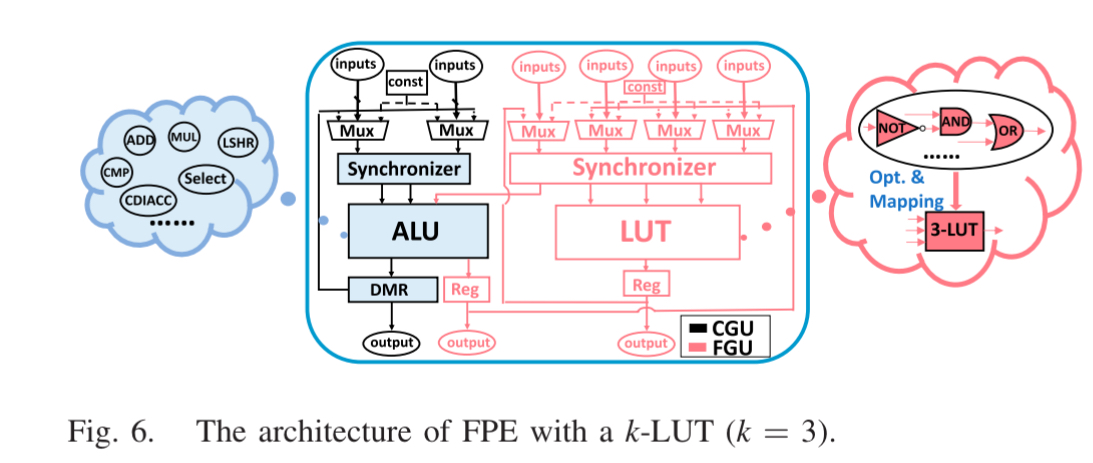
- FPE (Fused-Grained PE):
- 传统部分:包含一个 ALU (做加法、乘法)
- 创新部分:嵌入了一个 LUT
- 融合设计:ALU 和 LUT 之间有本地直连线。LUT 专门处理负责
if-else的条件判断和控制逻辑,ALU 负责真正的数据计算,这样既不浪费 ALU ,又能快速处理控制流
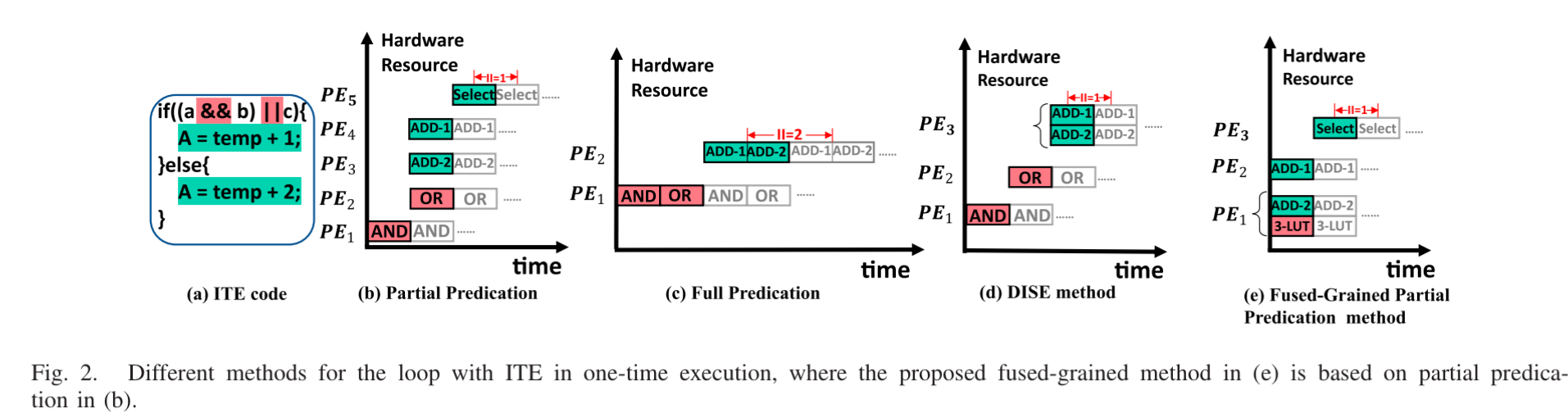
图中展示了处理 if-else 的四种传统方式(a-d)和 COFFA 方法 (e),虽然 Partial Predication 并行度高,但是需要额外的选择节点 (Select Node),而 COFFA 把“计算条件”的逻辑 (LUT)和“选择结果”的逻辑 (Mux/ALU)融合到一个 PE 里了,只需要一个周期就能出结果,并不需要其他方法那样等。
- FGIB:互联网络也能同时传输粗粒度数据和细粒度控制信号
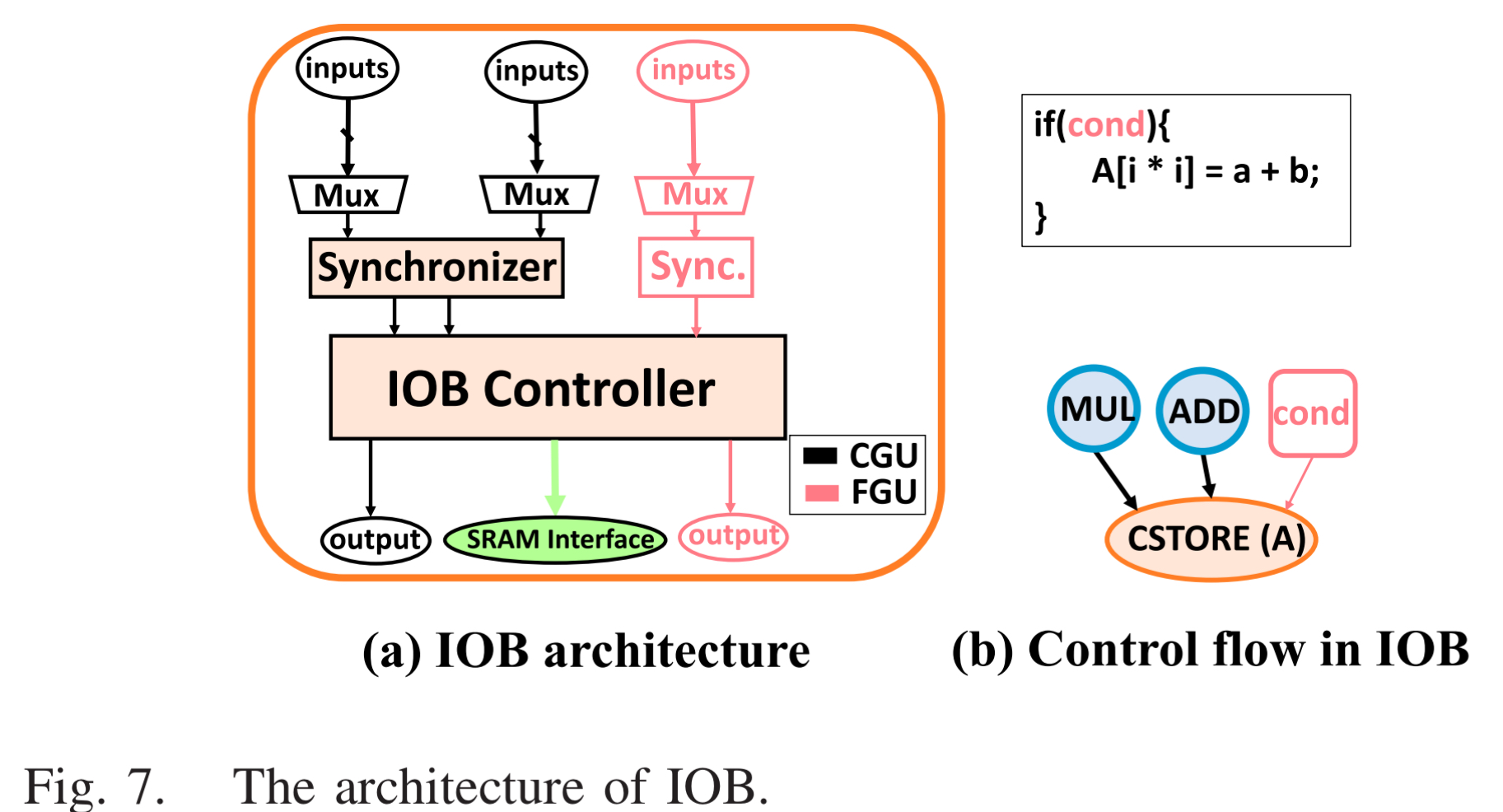
- IOB: 智能的存储控制器,支持简单的线性访问模式,也支持由 LUT 控制的复杂访问模式
软件编译器:业界首个引入布尔代数优化的 CGRA 编译器
这是 COFFA 的优点,以前的编译器只管把运算映射到 PE 上,不管逻辑优化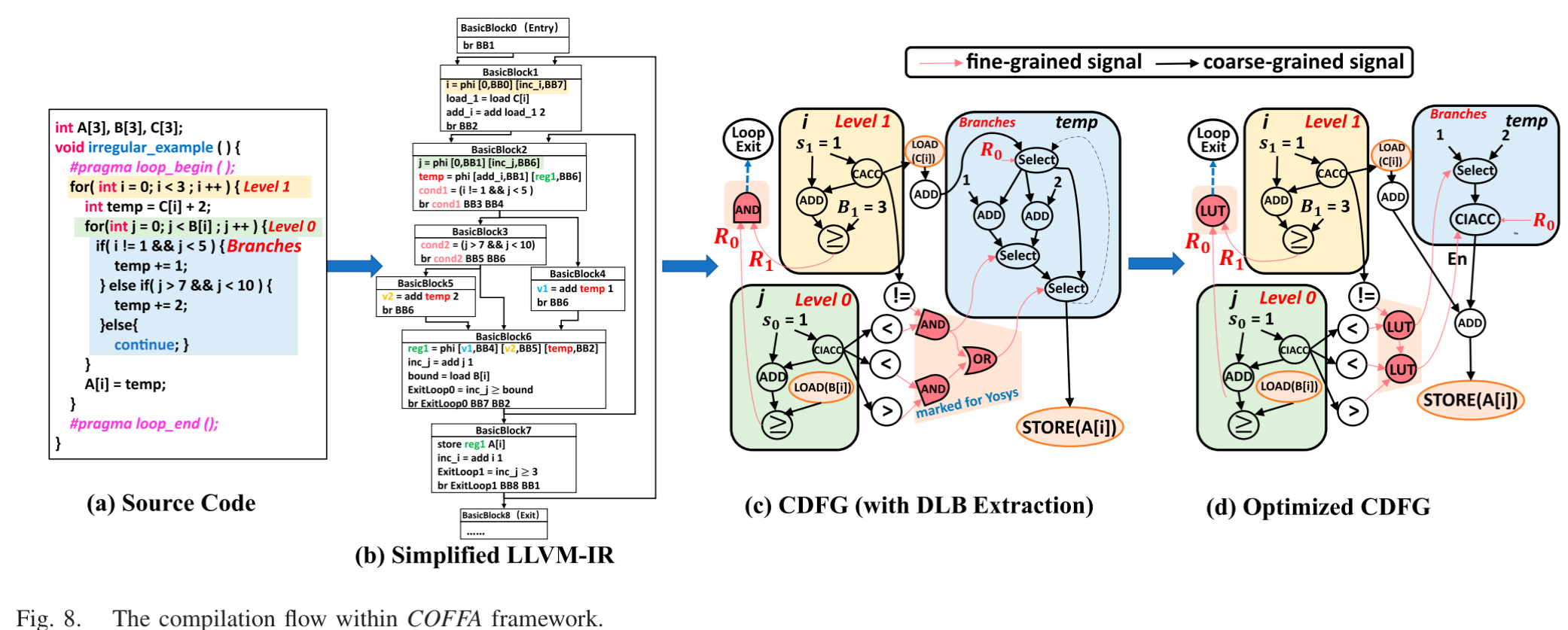
- 前端(LLVM-based):
- 把
if-else分支转换成数据选择操作 (partial predication) - 识别出哪些是控制流逻辑,(比如
condition = (a > b) && (c < d))
- 把
- 后端优化
- 引入 Yosys: COFFA 把提取出来的控制逻辑喂给 yosys
- 布尔优化:yosys 会自动化简逻辑门(比如把多层逻辑合并),然后映射到 FPE 里的 LUT 上。这大大减少了需要的 PE 数量和连线长度
- 映射 (Mapping): 使用模拟退火算法,将优化后的计算图(CDFG)映射到硬件阵列上
- 传统分层:算法->高级语言->编译器->指令集->微架构->电路
这应该算是这种优化算法的实例,这部分可以做的还有很多
代码阅读
硬件实现
- FPE 代码逻辑:
- 在代码中的 FPE 类。实例化了 ALU 和 LUT 模块
- ALU 的输入不仅可以来自邻居 PE,还可以直接来自内部的 LUT 输出(用于控制信号)。ALU 的比较结果 (如
GreatThan)也也可以直接喂给 LUT。这种“内部短路”设计大大减少了全局布线压力
- SoC 集成:
- 代码利用
Chipyard框架,将 FGRA 挂载到 RISC-V (Rocket Core)总线上(TileLink)。这在代码称为LazyModule的配置,使得 CPU 可以通过简单的指令配置 FGRA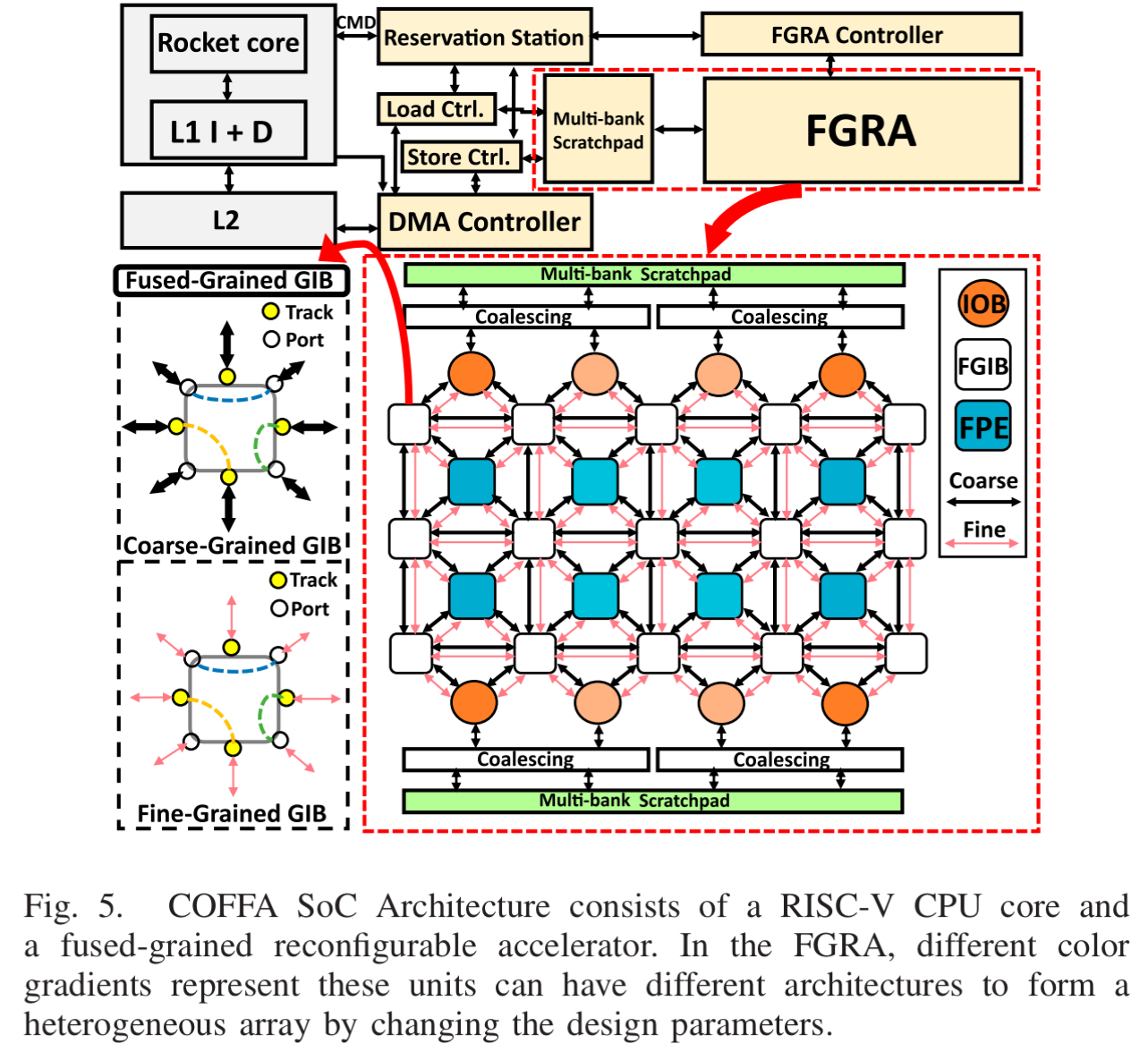
- 代码利用
编译器实现
- 前端 Pass
- 代码会遍历 LLVM IR。当遇到
Phi节点(LLVM 中表示分支汇合的节点)时,编译器会将起转换为Select节点 - 动态边界处理:这是一个难点。代中会有专门的 Pass 去分析循环索引 (Induction Variables)。如果是动态边界,它会插入预计算指令(Pre-generation logic),提前算出下一层循环是否结束,从而避免流水线停顿
- 代码会遍历 LLVM IR。当遇到
- 后端映射与 Yosys 接口
- 代码中会有一个步骤将提取出的子图 (Subgraph)转换为 verilog 或 BLIF 格式
- 调用 yosys 库进行逻辑化简
- Mapper: 这是一个图匹配算法,使用模拟退火来寻找将 CDFG 节点放置到 6 x 6 或 8 x 8 阵列上最优解。代码会尽量把 LUT 节点和依赖它的 ALU 节点放在同一个 FPE 或相邻 FPE 中
Fusion DSE flow
为什么 Fusion 需要 DSE?
Fusion SoC 架构(如下图所示)包含 Rocket Core、FGRA 阵列、多库 Scratchpad 存储器等多个组件。
为了适应不同的应用场景,设计者需要调整大量的硬件参数,例如:
- 架构层级: CGRA 的行/列数、数据位宽。
- 存储层级: Scratchpad 的深度、Buffer 大小。
- 互连层级: 输入/输出端口数量、路由连接方式。
这些参数组合构成了一个极其庞大且复杂的设计空间。每一个参数组合(Input)都需要经过耗时的综合与仿真(Expensive Experiment)才能得到面积和吞吐量等指标(Objective Function)。
核心痛点:
- 穷举法(Exhaustive Search): 不可能完成,空间太大。
- 试错法(Trial and Error): 效率太低,极其依赖人工经验。
因此,我们需要一种智能算法,用最少的实验次数,找到性能最好的配置。
贝叶斯优化(Bayesian Optimization)
解决昂贵黑盒函数优化问题的最佳工具之一是 贝叶斯优化(BO)。
贝叶斯优化不直接去跑昂贵的仿真,而是建立一个“代理模型”(Surrogate Model)来模拟硬件评估过程。它的工作流程包含三个关键要素:
- 统计模型(Statistical Model): 通常使用高斯过程(Gaussian Process, GP)。它不仅预测某个配置的性能(均值),还能告诉我们要这一预测的“不确定性”(方差)。
- 采集函数(Acquisition Function): 用来决定“下一步测哪个点”。它需要在探索(Exploration,去不确定的地方看看)和利用(Exploitation,去已知表现好的地方深挖)之间通过 UCB 或 EI 等策略寻找平衡。
- 优化器: 在代理模型上寻找采集函数的最大值。
通过这种“预测-采样-更新”的循环,BO 能够快速收敛到全局最优解
进阶方案:MoDAF 框架
虽然传统的 BO 很强大,但在面对 Fusion 这种非凸、多模态的高维设计空间时,仍显吃力。于是提出了一种名为 MoDAF 的多目标分治参数调优框架。
MoDAF 的创新点
1. 动态空间划分(Divide-and-Conquer Strategy)
这是该框架的杀手锏。它不再在整个庞大的空间里盲目搜索,而是采用“分而治之”的策略:
- SVM 划分: 使用支持向量机(SVM)将设计空间切割为“好”的子空间和“坏”的子空间。
- MCTS 搜索: 利用蒙特卡洛树搜索(MCTS)算法,基于 UCT 指标评估每个子空间的潜力,优先在最有希望的区域(高超体积 Hypervolume)进行采样。
2. 混合代理模型(Hybrid Surrogate Modeling)
单一的高斯过程模型在处理复杂数据时可能受限。MoDAF 结合了多种模型(如随机森林、深度集成模型等),以提高预测的准确性。
3. 双重采样策略(Dual-Sampling)
同时利用 qEHVI(期望超体积改进)和 qUCB 策略,平衡全局搜索与局部挖掘,加速帕累托前沿(Pareto Frontier)的发现。
实验成果
在与 NSGA-II、MOTPE 等经典算法的对比实验中,MoDAF 展现了显著的优势:
- 收敛速度更快: 在相同的迭代次数下,MoDAF 能更快地提升超体积(Hypervolume)指标。
- 解的质量更高: 能够找到面积更小、吞吐量更高的 Pareto 最优解组合。
参考资料
*PPT 以及图示来自 Fusion SoC Workshop:Fusion SoC: A Fused-Grained Reconfigurable Architecture for Efficient Edge Computing Acceleration
*开源仓库:GitHub - Dai-dirk/COFFA: COFFA:融合粒度可重构架构的共设计框架