
(FPT2025)LL-ViT
Dec 10, 2025
背景与动机
视觉变换器(ViTs)在计算机视觉任务中表现出色,但计算量大、内存占用高,难以在资源受限的边缘设备(如 FPGA)上部署。传统的优化方法(如量化、片外权重加载)通常在延迟、能耗或精度上存在严重的权衡。在典型的 ViT 模型中,通道混合器(即 MLP 层)占据了超过 60% 的模型权重和 50-70% 的乘累加(MAC)操作。
- 作者提出使用基于查找表(LUT)的神经元来替代传统的 MLP 层。与传统的“无乘法网络”不同,LL-ViT 不是简单地将乘法替换为查找,而是采用了一种可以原生学习 LUT 函数的神经架构。(神经网络叠神经网络)
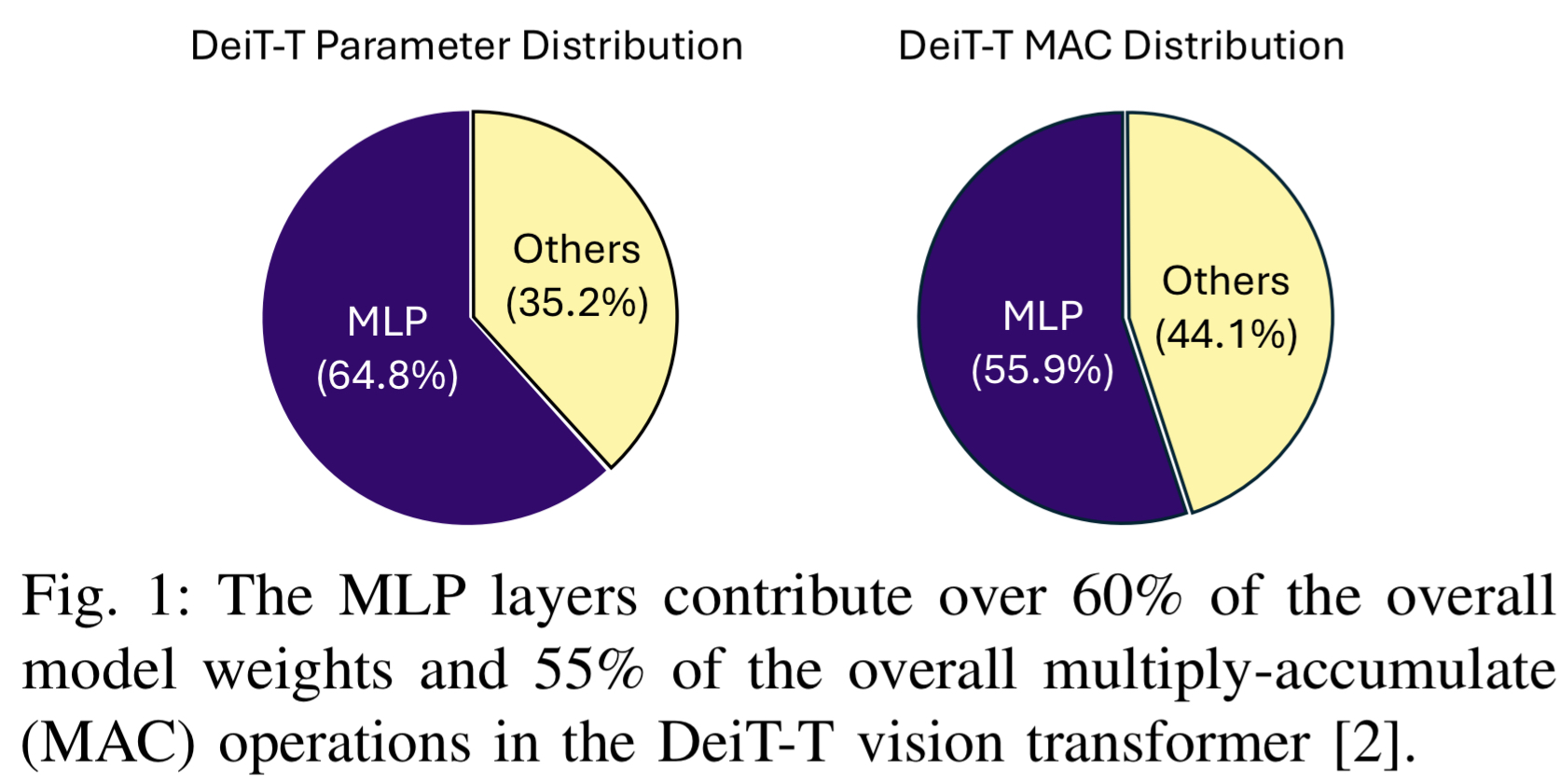
算法与架构设计
LL-ViT 设计了一种全新的基于 LUT 的通道混合器 (LUT-based Channel Mixer),并将其集成到标准的 Transformer 编码器中。
整体架构
LL-ViT 保持了标准 ViT 的宏观结构,由一系列编码器块组成。
- 令牌混合器 (Token Mixer): 保留了多头自注意力(MHA)机制,用于捕获令牌间的空间关系。
- 通道混合器 (Channel Mixer): 将传统的 MLP(由矩阵乘法和非线性激活组成)替换为基于 LUT 的无乘法模块。
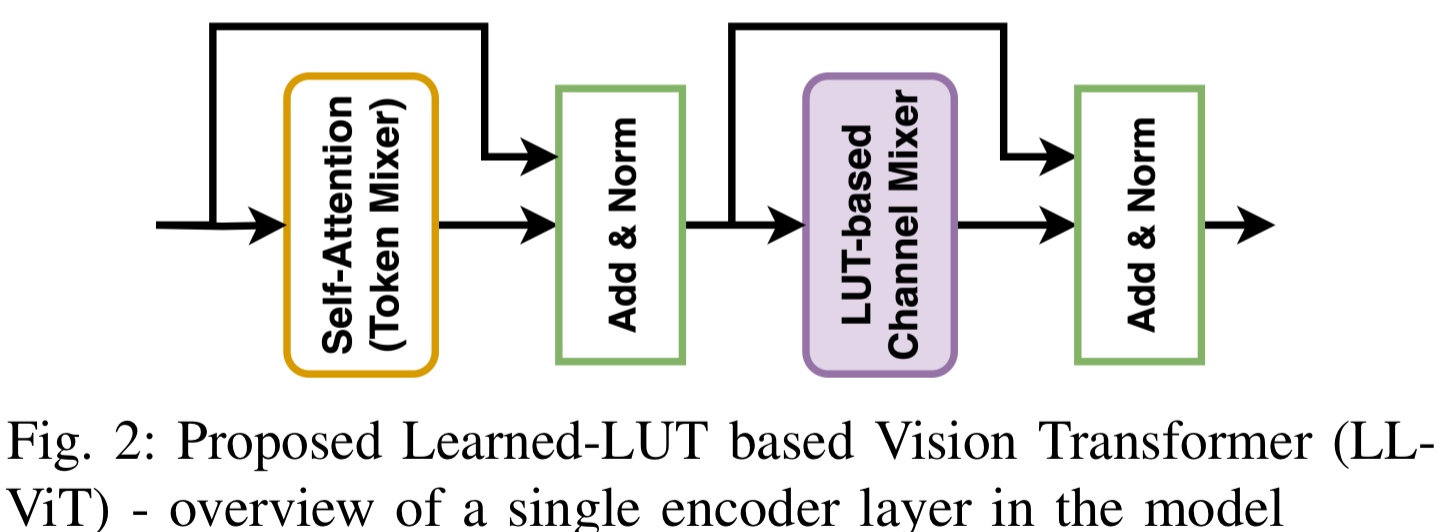
基于 LUT 的通道混合器算法细节
其处理流程如下: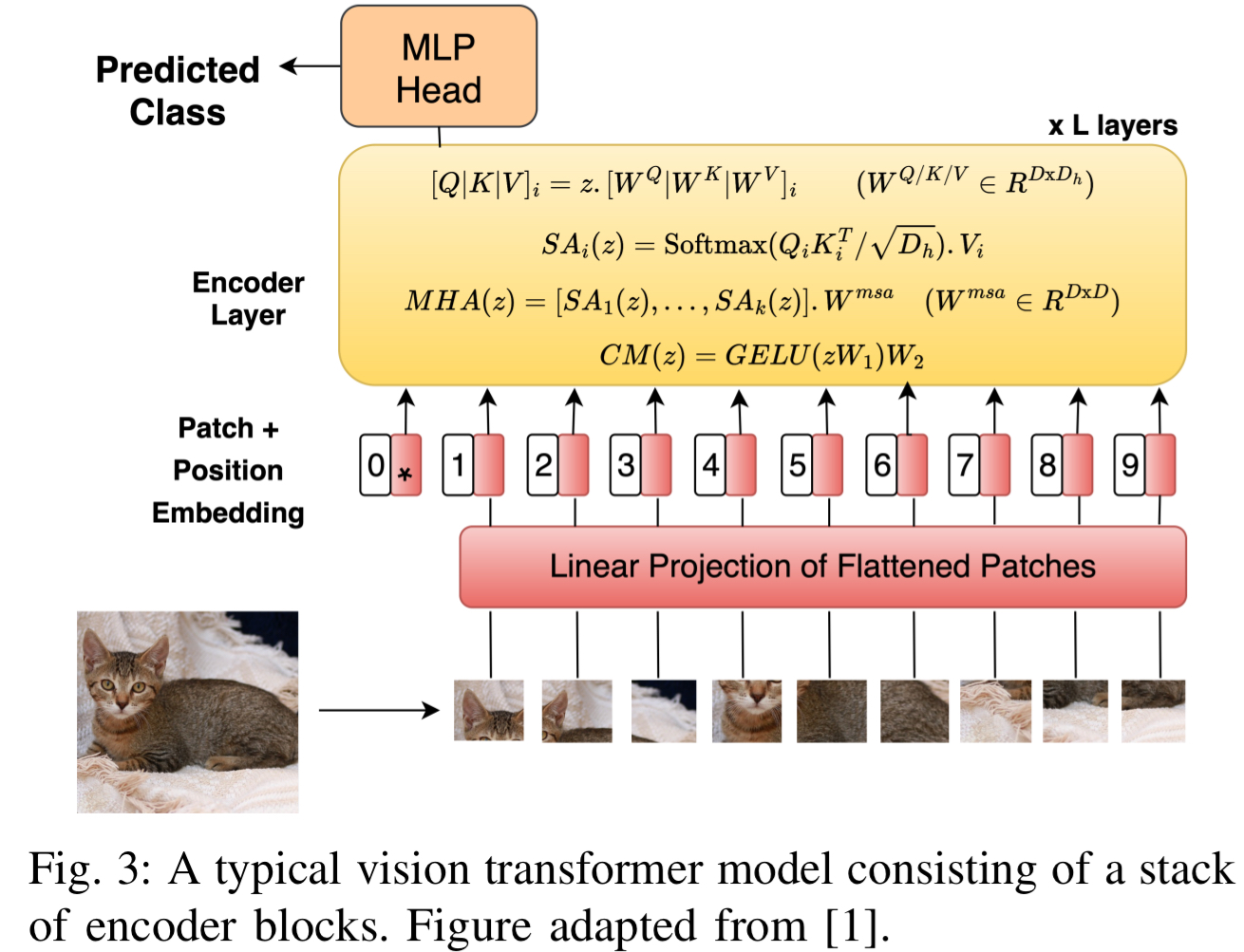
- 输入处理与展开:
由于通道混合器独立处理每个令牌,输入激活矩阵首先被展平,逐行通过后续层。 - 温度计编码 (Thermometer Encoding):
将连续的浮点特征值转换为二进制位序列,以便作为 LUT 的输入地址。类似于二值神经网络(BNN),通过比较器将数值转化为位串。训练过程中使用直通估计器 (Straight-Through Estimator, STE) 来计算梯度,解决离散化导致的不可微问题。
输入的是浮点数,查找表看不懂,所以用温度计编码处理输入(就像是温度计的水银柱)数值越大,亮起的“1”就越多。这样就将复杂的连续数值变成了计算机最喜欢 0 和 1 比特流。
- 可学习的 LUT 神经元层 (Learned LUT Neurons):
- 这些神经元不进行乘加运算$$y=\omega x+b$$,而是直接执行查找操作。前一层的输出位被组合成地址,在 LUT 中查找输出。
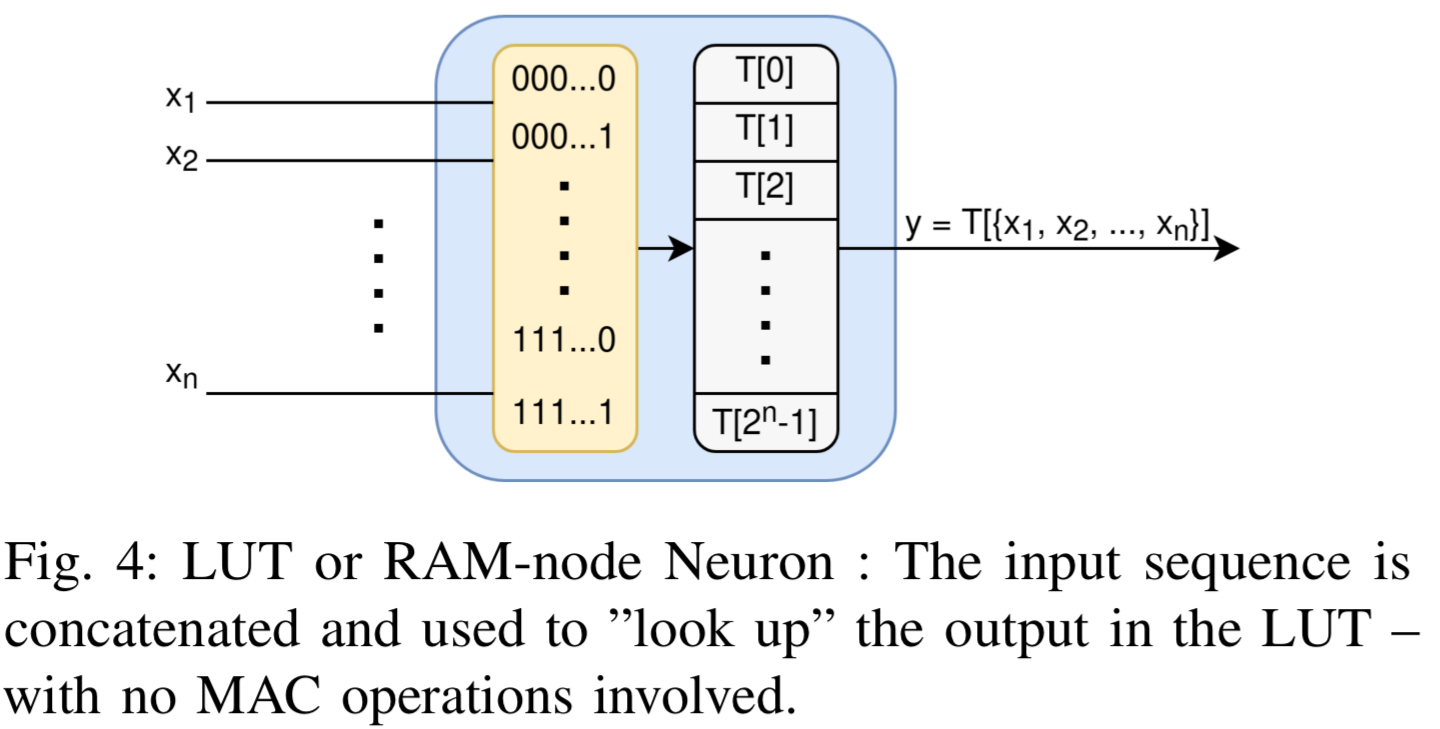
- 训练方法: 采用了 DWN (Differentiable Weightless Networks) 中的技术,利用**扩展有限差分 (EFD)**来定义 LUT 条目的梯度,使得可以通过反向传播直接训练 LUT 的内容及其连接方式。
- 论文发现两层 LUT 结构(分别为 768 和 192 个 LUT)配合 8 位温度计编码效果最佳。
- 这些神经元不进行乘加运算$$y=\omega x+b$$,而是直接执行查找操作。前一层的输出位被组合成地址,在 LUT 中查找输出。
将上一步生成的比特流(0 和 1)直接用作为地址索引,比如输入的是 `110` 就去找查找表中第 110 号位置存的是什么(输出通常是 0 或 1)
- 条件求和层 (Conditional Summation Layer) —— 关键设计:
- 传统的 LUT 网络通常用于分类(输出类别概率),但作为 Transformer 的中间层,它必须输出实值特征向量以保持精度并支持残差连接。
- 该论文引入了一组可学习的编码值(权重 Wij)。
- 这是一个无乘法的操作,仅根据 LUT 的输出决定是否累加某个值(相当于条件加法)表现为矩阵乘法,完全可微,允许使用 FP 32 进行高精度训练。训练后,这些编码值被量化为 INT 4,进一步压缩模型。
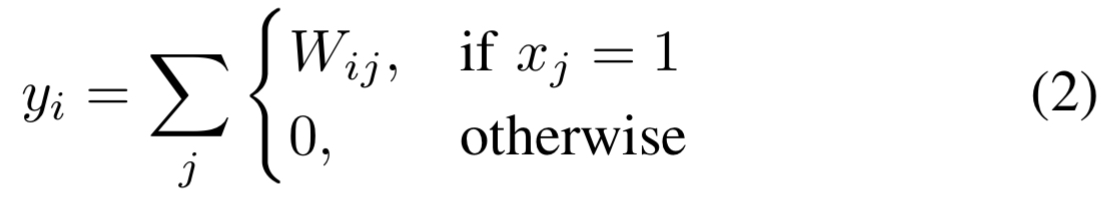
其中 x_j 是最后一层 LUT 的输出(0或1)。
查找表找出来的只是一堆 0 和 1,图像分类任务需要精确的数值(比如概率),所以给每个查找表分配一个“权重”,如果查表结果是 1,则加上这个权重值,如果是 0 则忽略。则输出的结果就是 $$Output=\sum (权重 \times 查表结果)$$(这里面其实也没有乘法,只有加法)
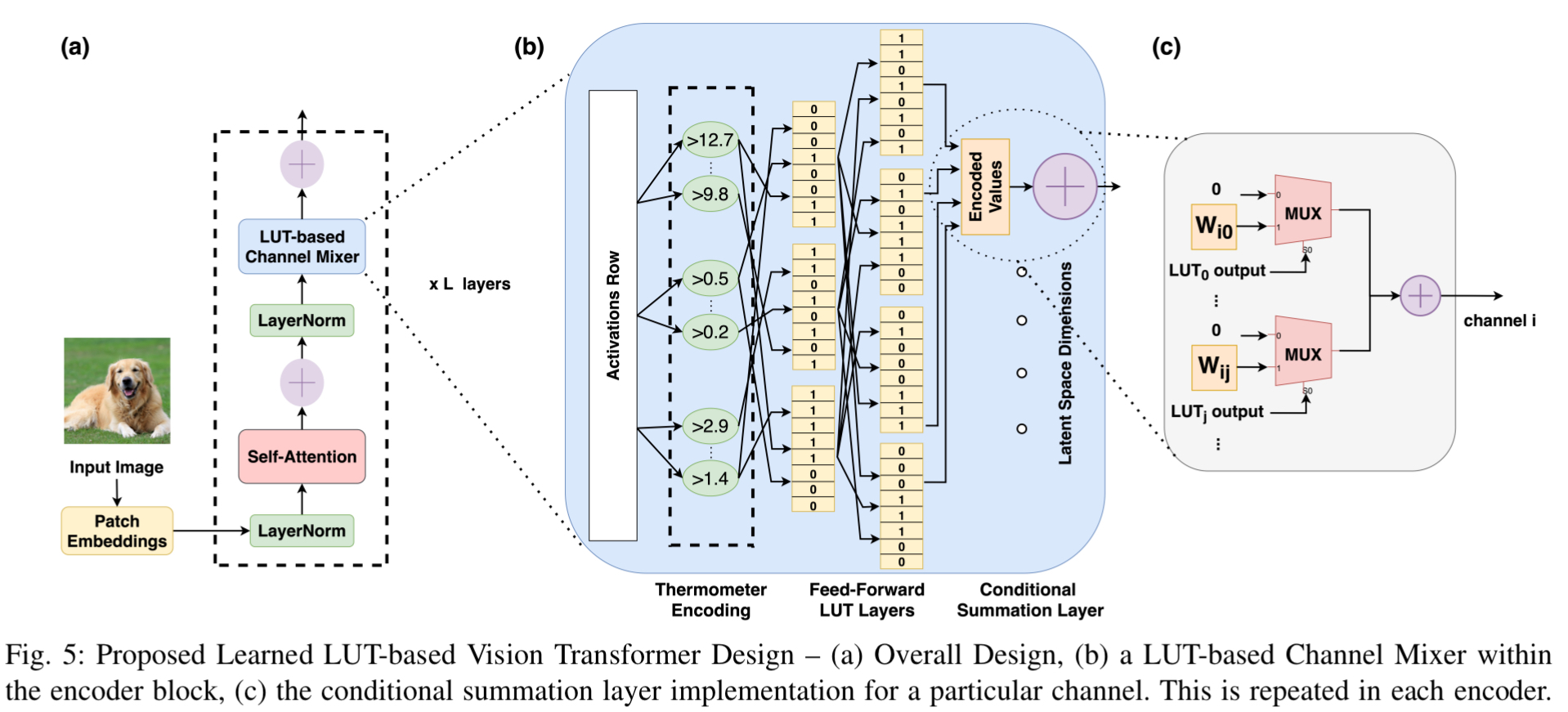
硬件加速器
LUT 神经元直接映射到 FPGA 的硬件 LUT 资源上,无需消耗 BRAM 来存储权重。设计了乒乓缓冲区(Ping-Pong Buffer)和专用处理单元(PE),实现了通道维度的并行处理和行级流水线。由于模型极度压缩,权重可完全驻留在 FPGA 片上内存中,消除了高能耗的片外内存访问。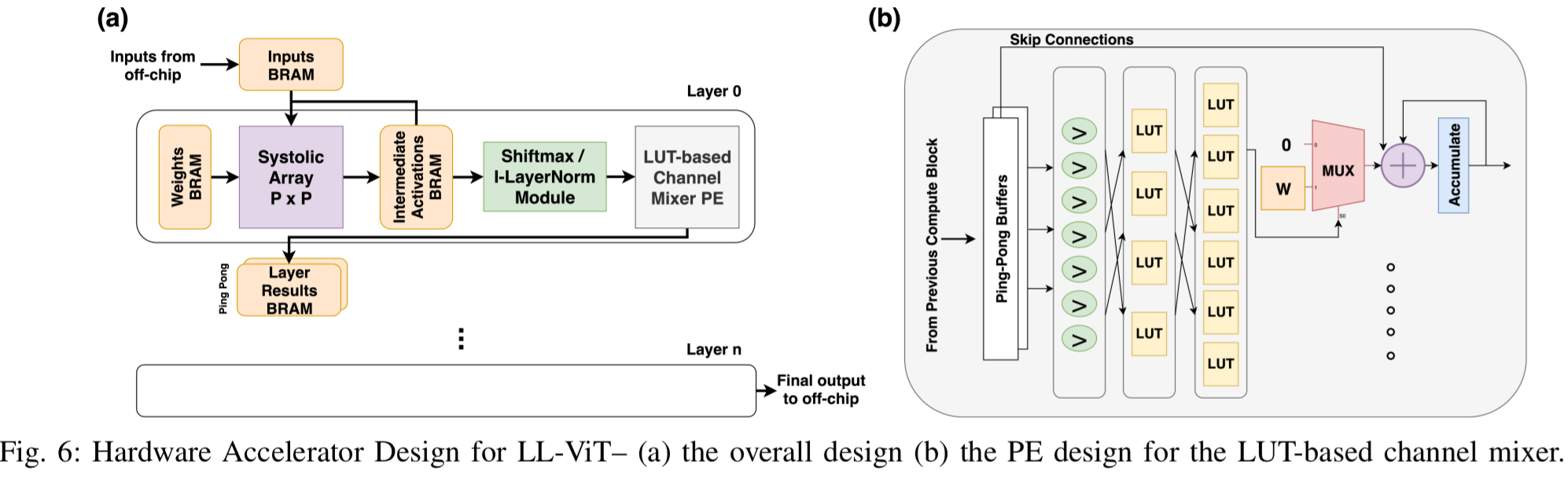
3. 实验评估与结果
论文以 I-ViT-T(INT8 量化模型)作为基线,在 CIFAR-10、CIFAR-100 和 Tiny-ImageNet 等数据集上进行了评估
模型精度:
- CIFAR-10: 95.5% (基线为 95.4%)
- CIFAR-100: 78.8%
- Tiny-ImageNet: 60.9%
LL-ViT 在大幅削减计算量的同时,保持了与基线相当甚至略优的精度,这解决了以前基于 LUT 的网络无法处理复杂视觉任务的问题。
资源与效率 (在 Virtex FPGA 上):
- 模型压缩: 权重减少超过 60%。
- 计算减少: 乘法操作减少 50%。
- 能效提升: 相比全量化的 ViT 加速器,能效提升 1.9倍。
- 延迟降低: 延迟降低 1.3倍。
- 吞吐量: 在 10.9W 的功耗下达到了 1083 FPS。
对比分析:
- 与其他无乘法网络(如 LUT-NN)相比,LL-ViT 通过原生学习 LUT,在减少查找和加法操作数量的同时实现了更高的性能。
- 相比激进量化(如 3-bit)的方案(如 HG-PIPE),LL-ViT 在功耗上低得多(约 1/4),更适合边缘场景。
4. 总结
LL-ViT 成功证明了将可学习的 LUT 神经元集成到 Vision Transformer 的可行性。通过替换最耗资源的 MLP 层,LL-ViT 实现了算法与硬件的协同设计,在不牺牲精度的前提下,显著降低了模型的内存占用、计算需求和能耗.