
(FPT2025)OpenDRAM
背景与动机
现状:大多数内存控制器 (MC) 的研究依赖于高级语言模拟器(如 C++),缺乏开源的 RTL 实现。FPGA 厂商提供的 IP(如 AMD MIG)是闭源的,难以修改和扩展
挑战:现代 DRAM 的运行频率远高于 FPGA 运行频率(通常是 4:1的比例)。为了利用 DRAM 的全带宽,FPGA 端的控制器必须在一个时钟周期内发出 4 个 DRAM 命令。这导致了极高的时序收敛难度。
该论文提供了一个完全开源、高性能、支持 JEDEC 标准、且能通过 RTL 验证和真机测试的 DDR 4 控制器
DRAM 控制原理
图 1 描绘了 DRAM 设备的组织,其中多个芯片独立运行,同时共同保存相同数据的不同段。单个芯片包含一组称为存储体的数据阵列。每个数据阵列由一组行和列(或页)组成。每个存储体还包含一个行缓冲区,可以缓存相应数据阵列的一行。
在 DDR 4 中,引入了存储体组的概念,将多个存储体组织在一起,以实现更高的并行性和改进数据的吞吐量。
当 MC 接收到读或写请求时,它首先执行地址转换,根据其地址将请求映射到对应的存储体、行和列。如果请求的行在行缓冲区可用(行命中),则 MC 发出 CAS 命令(写操作为 WR, 读操作为 RD),设备直接在行缓冲区中的请求列进行数据读写;这称为开放请求。否则(行未命中),控制器需要先发出 PRE 命令将行缓冲区内容写回数据阵列,然后发出 ACT 命令将请求的行传输到缓冲区,最后发出 CAS; 这称为关闭请求。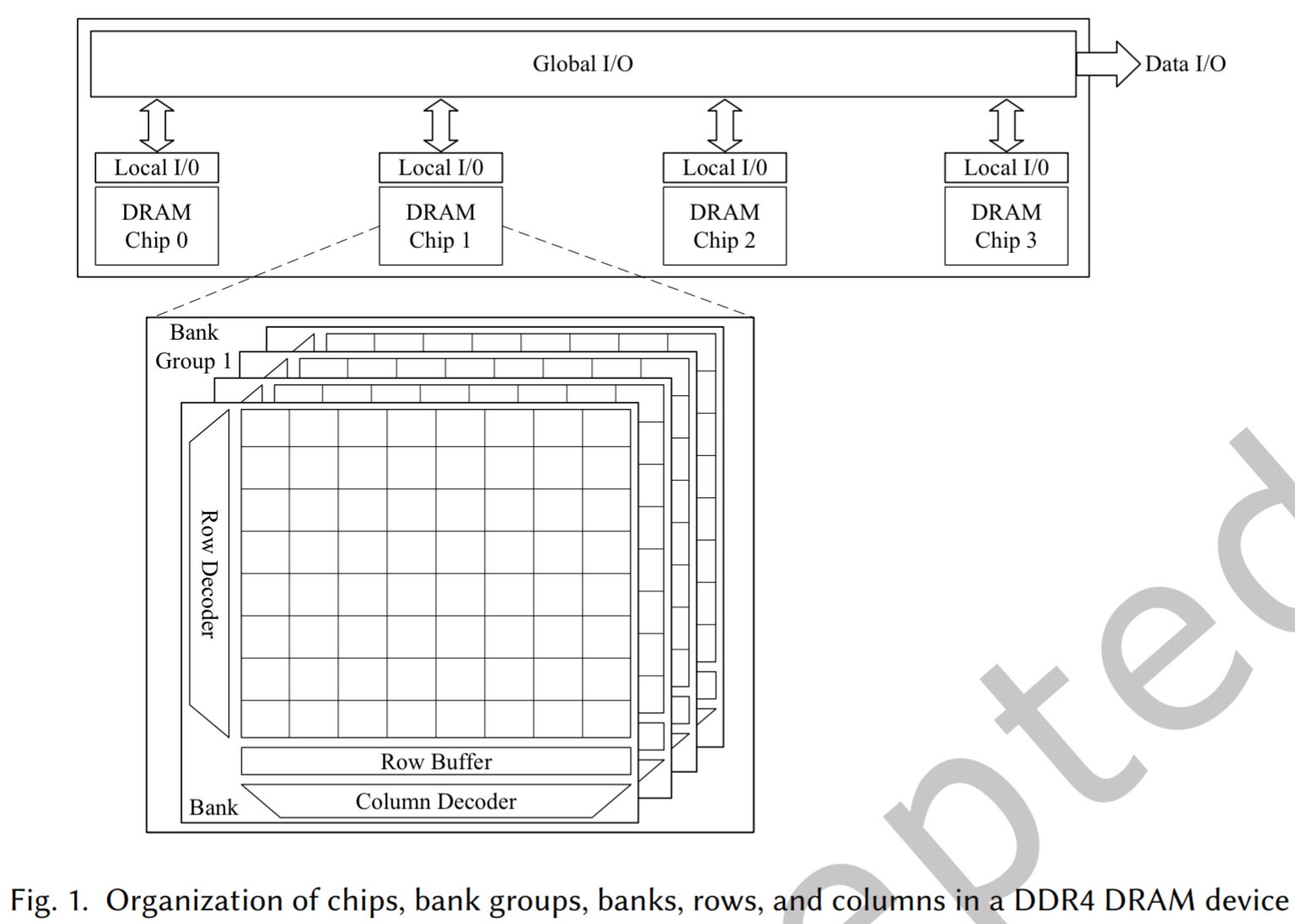
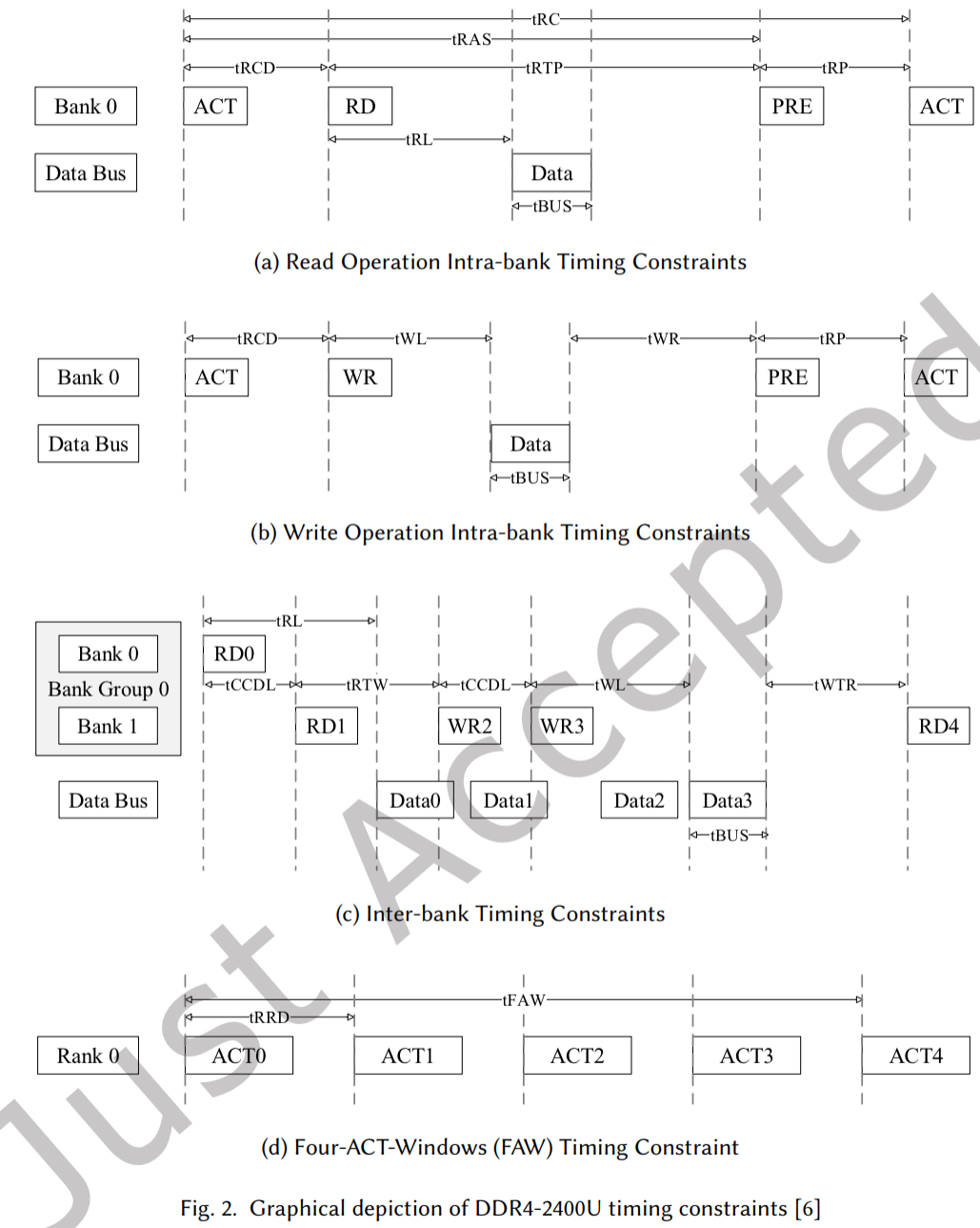
图 2 描绘了单个存储体内读操作的序列和时序。
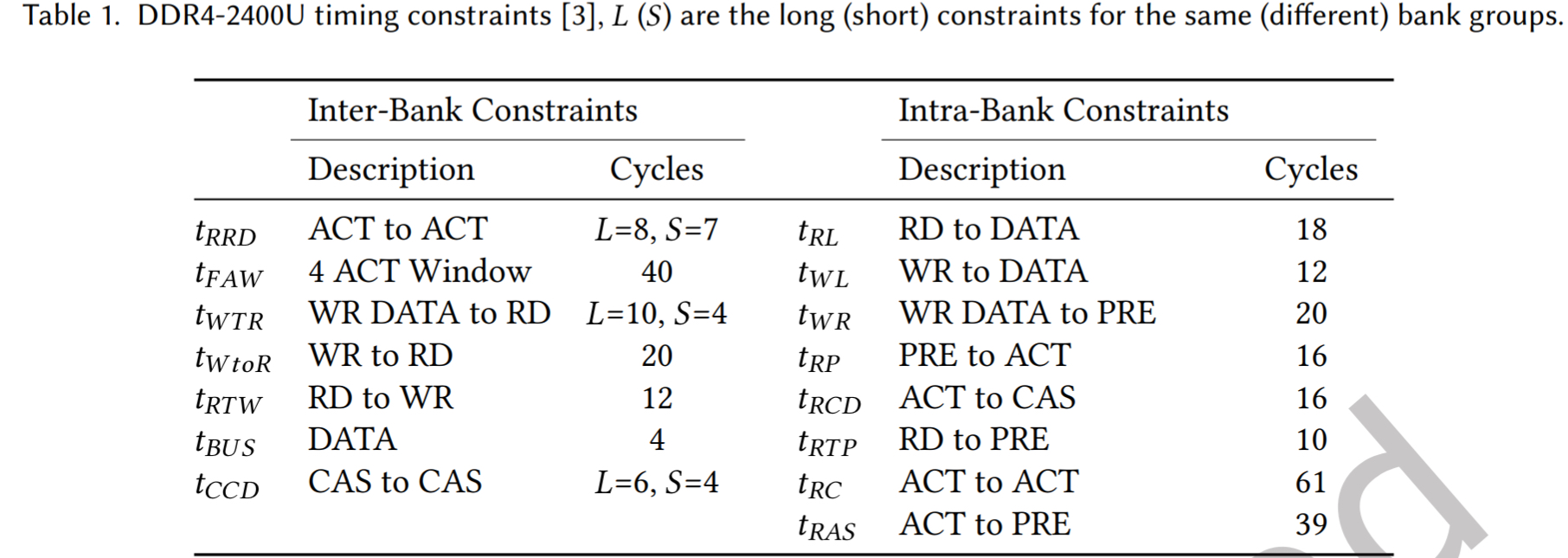
- 发送到同一存储体的两个 ACT 命令之间最小时间约束称为行周期时间 (tRC),等于行激活时间(tTAS)与行预充电时间 (tRP)之和。这些约束通过防止操作重叠并确保在向同一存储体发送第二个 ACT 命令之间有足够的时间关闭来保证数据的完整性。
- 发送 ACT 命令后,MC 必须等待满足 DRAM 将行数据从 DRAM 核心传输到行缓冲区所需的最短时间,然后才能发送 RD 或 WR 命令。此约束称为行列延迟 (tRCD)。虽然读和写操作都必须满足 (tRCD),但它们随后的时序约束不同
- 读取延迟 (tRL)表示 RD 命令发出后数据被放置到数据总线上的时间,而写入延迟 (tWL)约束定义为发出 WR 命令与 MC 将数据放置在总线上之间的延迟,如图 2(b)所示。
- 在发送 PRE 命令之前,MC 必须分别遵守读和写操作的 RD 到 PRE(tRTP)或写数据到 PRE (tWR) 时序约束
- 图 2 (c)说明了 MC 在后续读或写命令之间必须满足的时序约束。CAS 到 CAS (tCCD)约束是相同类型的后续 CAS 命令之间必须经过的最小时钟周期数。
- 由于总线转换时间,在 RD 命令之后发送 WR 命令或相反之前,必须满足读-写 (tRTW)或写-读 (tWTR)时序约束。所有约束都是在两个命令之间,除了四激活窗口 (tFAW),它定义了一个滚动窗口,在此期间最多可以向单个 rank 发出四个 j 激活命令,如图 2 (d)所示。
- 在 tFAW 施加读时间窗口内,MC 还必须遵守行到行延迟(tRRD)时序约束,该约束定义为必须经过的两个发送到不同存储体的 ACT 命令之间的周期数
内存接口生成器
AMD 的 MIG IP 生成 DDR 内存接口,包括用户接口、MC、校准和 PHY 模块(图 3)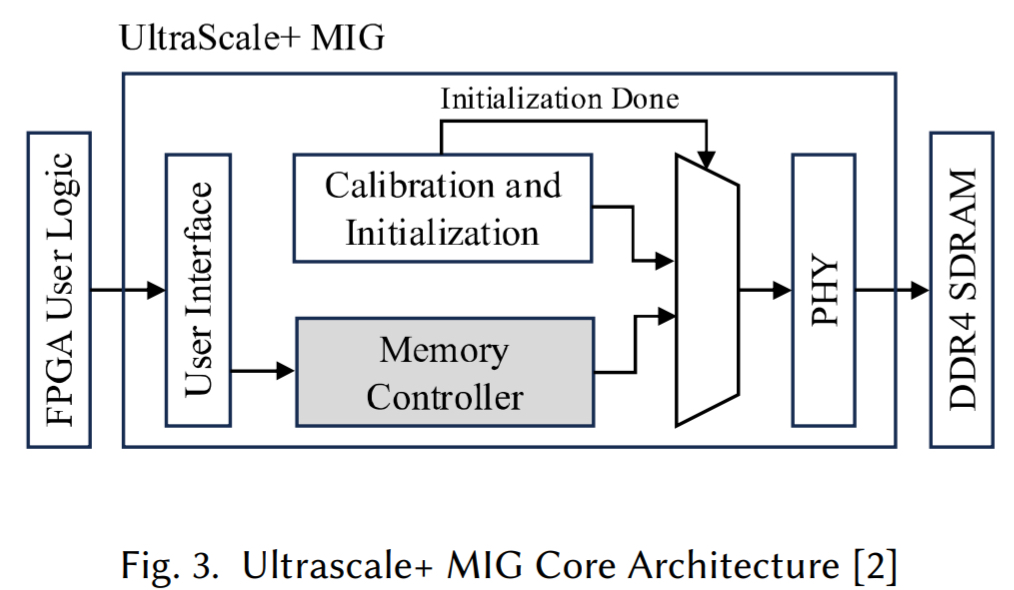
- 用户接口捕获 l 来自 FPGA 逻辑的请求并管理数据
- 校准逻辑处理校准步骤
- PHY 包括用于串行化/反串行化和 PLL 硬 IP,以及用于初始化的软 IP
MC 和校准逻辑在较慢的时钟域中与 PHY 交互,该时钟域是 DRAM 设备频率的 1/4。
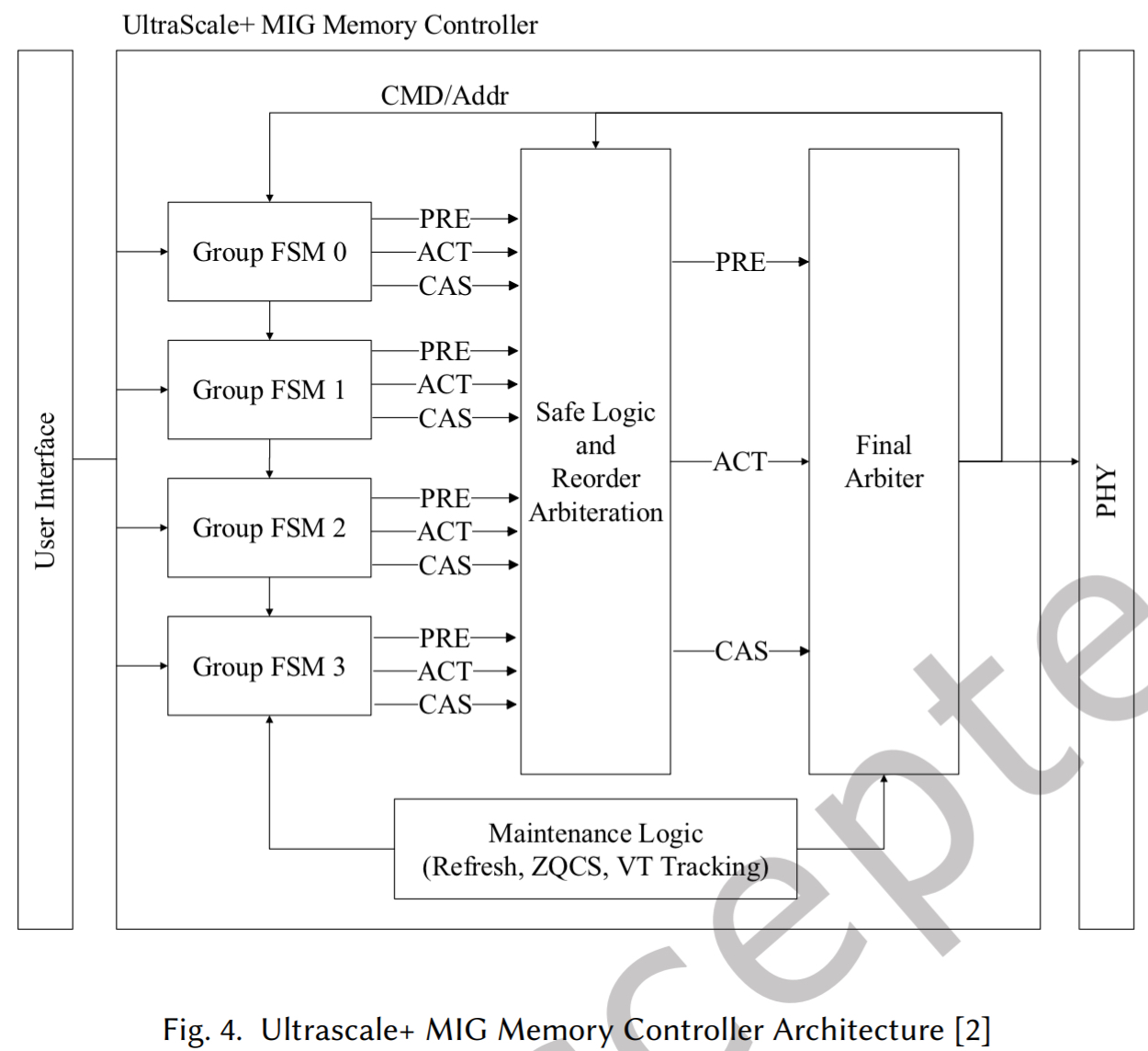
MC 必须要在一个时钟周期内发出四个命令槽点数据包以满足 PHY 频率要求。在这四个槽中,MIG 的 PHY 限制 CAS 命令只能在槽 0 或槽 2 中发出。如图 4 所示,MIG 的 MC 包含多个组件:四个状态机(Group FSM)、仲裁器以及维护和刷新模块。
- x 4 和 x 8 型号(具有 4 个存储体组),每个组 FSM 分配给一个存储体组,在 x 16 型号(具有 2 个存储体组),每个存储体分配两个组 FSM。
- 每个 Group FSM 具有两个阶段,具有独立的队列和状态机。
- 第一阶段入队请求并根据需要发出 PRE 和 ACT 命令
- 第二阶段管理 CAS 命令,在满足时序约束时发出
- 在 Group FSM 内,MIG MC 根据请求到达顺序以 FIFO 方式仲裁请求,而不同组 Group 的命令使用循环轮询仲裁器选择。
- 这种仲裁方案不利用重排序来优先处理针对开放行的请求,从而限制了性能
OpenDram
一个高性能、可配置的 DDR 4 MC,具有基于存储体的 FR-FCFS 前端请求调度器和循环轮询后端命令调度器。沿用 MIG MC 模块设计。
前端在请求/事务级别运行,而后端在 DRAM 命令级别运行。请求和命令的调度完全独立,可以修改而不影响。并引入 5 种命令调度器设计。(由于模块化设计可以随意切换调度,或者修改)
OpenDram 的 MC 核心架构如图 5。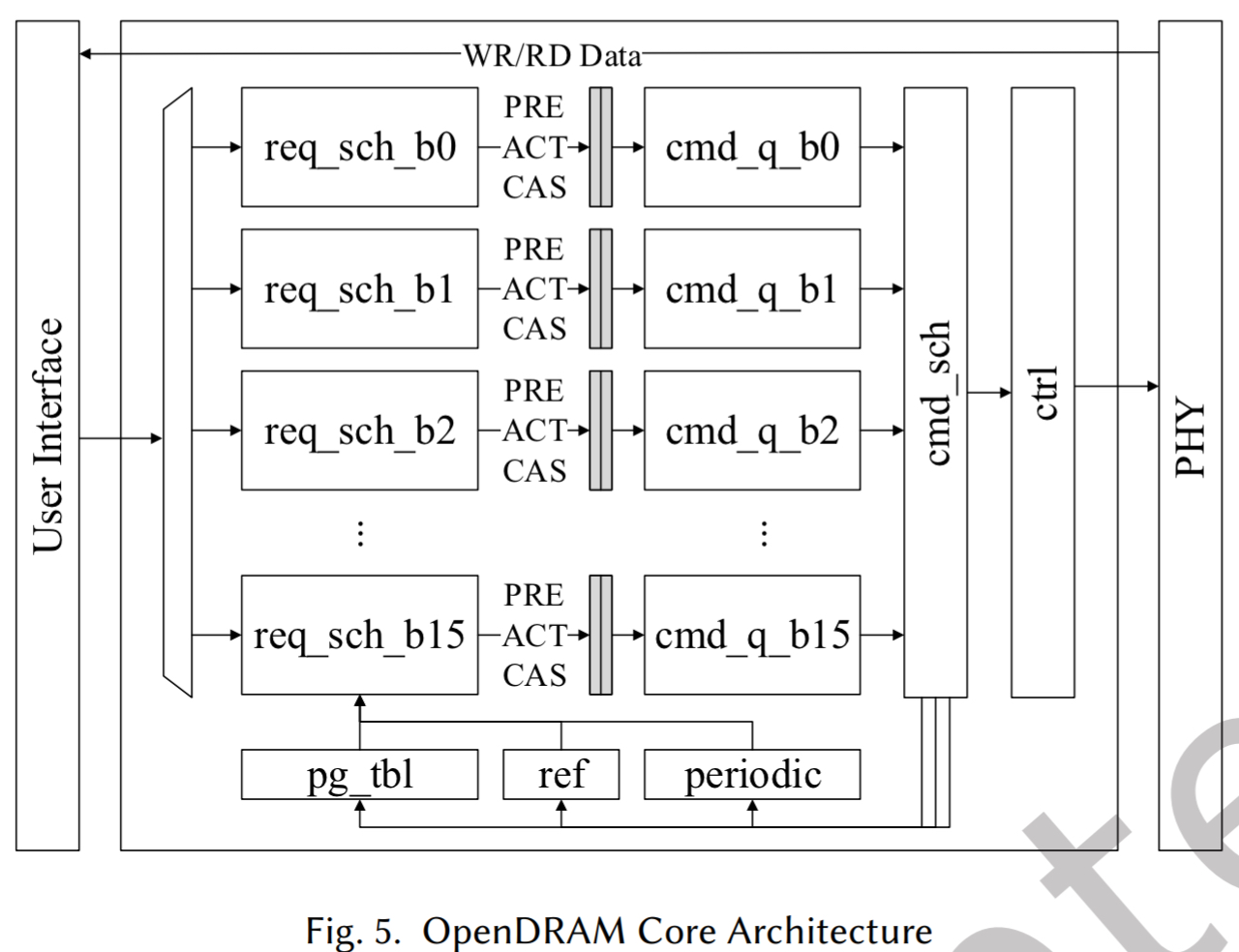
- 请求调度器(
req_sch_b_i, 其中 i 是存储体索引)执行请求的排队和仲裁,然后根据页表(pg_tbl)中存储体状态为选定的请求生成一组 DDR 4 命令 (PRE, ACT, CAS) - 然后,这些命令被入队到相应的命令队列 (
cmd_q_b_i)中。 - 与 MIG 的存储体组并行性不同,OpenDram 使用基于存储体的请求队列和命令队列来利用存储体并行性
- 命令调度器 (
cmd_sch)选择最多 4 个命令,类似于 MIG, 同时最小化读写请求转换 - 命令作为数据包传递给 carl 模块,转换为 PHY 适当的信号
- 子模块 ref 和 periodic 从 MIG 借用,分别刷新过程运行时校准
- 刷新请求在每个刷新间隔 (tREF1)内,一旦挂起的读。写请求完成,就有机会地调度。
- 用户接口也从 MIG 中重用;该模块通过传入的请求入队到请求调度器的队列中,并未读请求返回相应,与内存控制器的系统侧交互
页表
页表中每个条目对应一个特定的存储体,并包含两条信息:该存储体中当前打开的行,以及一个指示存储体是空闲还是活动的单 bit
页表跟踪发送到 DRAM 中的 PRE、ACT 和 REF 命令。PRE 将相应存储体的空闲 bit 设置为 1,而 REF 将所有存储体的空闲 bit 设置为 1。
页表由每个唯一存储体的请求调度器模块内 FR-FCFS 仲裁器使用,以识别请求队列中针对该存储体的开放请求
请求调度器
MC 的前端在请求级别运行,包含三个主要组件:请求队列、请求调度器和命令生成器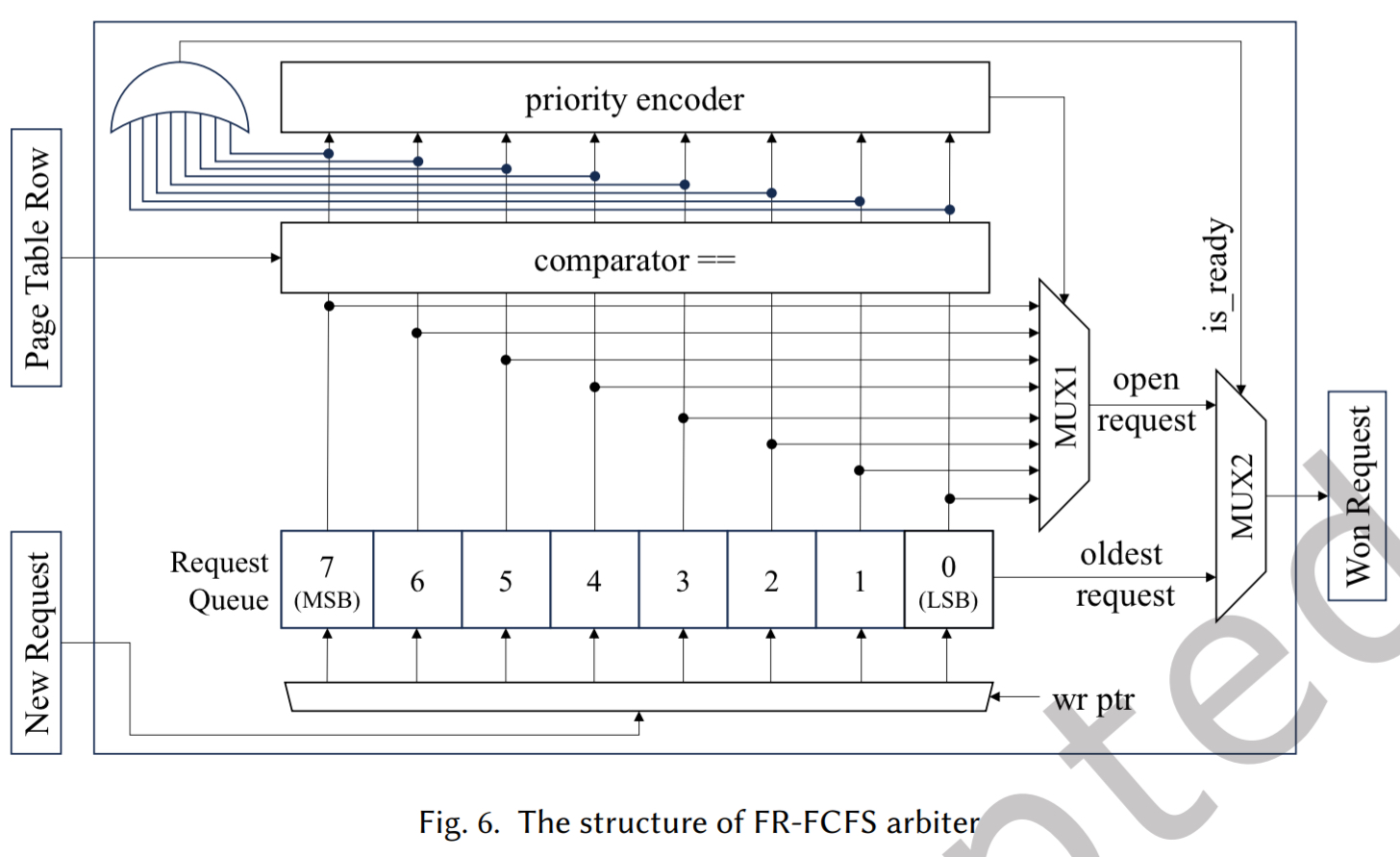
它有一个大小为 8 的请求队列,索引 0 (LSB)是最老的槽,索引 7(MSB)是最新的槽。
请求队列条目中的行地址与页表中存储的当前的行进行比较,生成指示请求是否为开放的标志。这些标志决定 MUX 2 的选择信号
- 1)如果存在至少一个开放请求,优先编码器会使用 MUX 1 选择最老的开放请求
- 2)如果没有开放请求,则从索引 0 选择最老的请求。一旦选择了一个请求,就会生成相应的 D RAM 命令并进入对应存储体的命令队列
命令队列
基于存储体的命令队列最多可容纳三个命令。
因为发送到同一存储体的两个连续命令之间最短的时间是 tCCD_L 的 6 个周期,因此,MC 无法在连续的周期内背靠背地向同一个存储体发送两个命令, 所以 MIG MC 只能在特定槽发出
命令调度器
查看每个命令队列的前端命令,并在一个时钟周期内在四个槽中选择最多 4 个命令。词啊用循环轮询指针在命令队列之间进行仲裁。
命令调度器主要功能包括命令仲裁和约束跟踪器模块内的时序约束。
- 约束跟踪器模块内的计数器组织成表,每个表按存储体实例化。在每个表中,指定了四个计数器,每个计数器专用于该存储体相关联特定命令类型(PRE, ACT, CD 和 WR),计算特定命令到达就绪状态(即计数器达到零),并可以被仲裁器选择之前剩余的对应槽点 DRAM 周期数。
- 该表的设计运行并行访问所有表中的所有条目。例如,命令调度器可以同时检查片间和片内约束。通过应用对就绪命令的循环轮询仲裁,命令调度器宁愿在 CAS 类型不同之前选相同类型的 CAS, 从而最小化读写切换。

提出了 5 个版本的命令调度器,在性能和频率之间提供不同的权衡。主要设计挑战是对如何在每个 MC 周期内调度命令施加约束,从而简化调度逻辑,减少逻辑级数,最终提高工作频率。 - v 1: 工作在最低频率,但是在命令仲裁方面提供了最高的自由度,因此具有最佳性能
- v 2: 与 v 1 相比,在关闭内存访问模式下的性能差异非常小。V 1 允许每个周期发出最多 4 个 PRE 命令,而 V 2 限制为两个 PRE 命令。其次,与 v 1 不同,ACT 不再允许在任何槽中发出;而是强制在槽 1 和槽 3 中选取。分别通过推迟 PRE 或 ACT 来延迟关闭或行打开,并不总是导致性能损失。相反,在某些情况下是有益的
- v 3 增加了 tRRD_L 的值,这可能会延迟 ACT 命令的发出。
- v 4 中增加了 tRTP 和 tWTR_S,可能分别延迟读命令后的预充电以及写后的读。
- v 5 与 v 4 相比,没有对调度逻辑施加额外的约束,因此不会直接降低 MC 性能。
版本 1 (v 1)
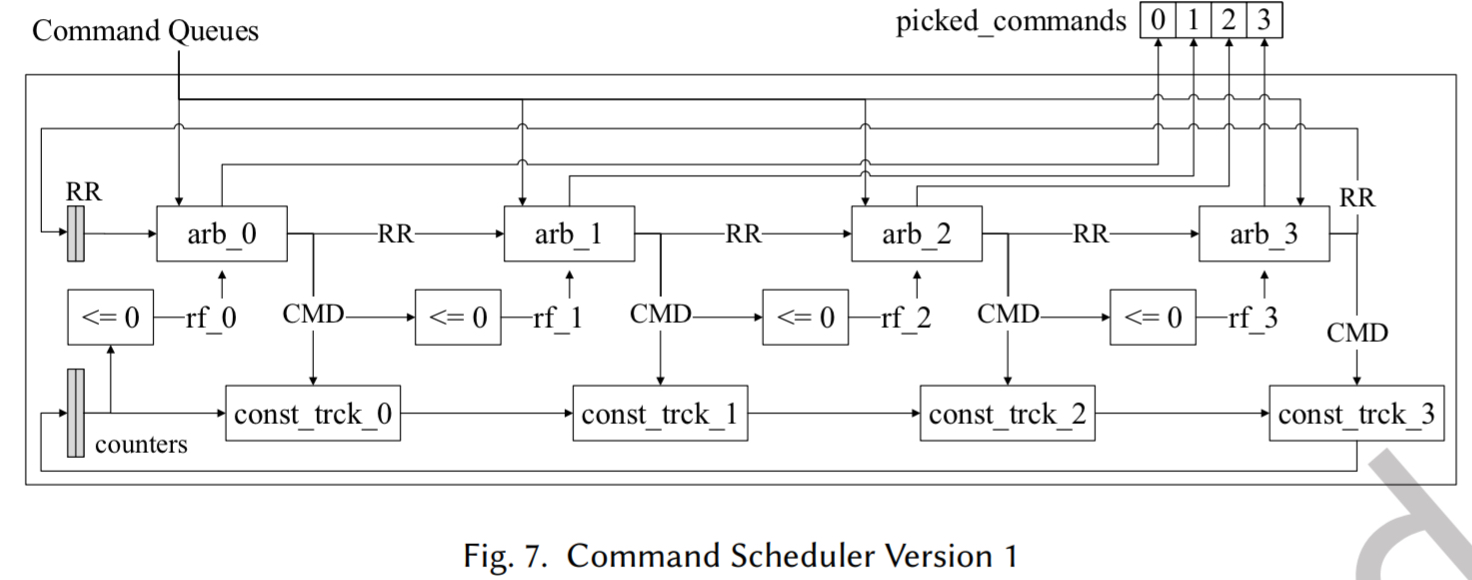
提供了最高的调度粒度,但是工作在较低的工作频率。包含 4 个链式的组合逻辑块,每个块基于计数器值和循环轮询指针为一个槽选择一个命令,更新相关计数器和循环轮询指针以供下一个周期使用。
图 7 中每个槽使用三个块:一个比较器(<=0)、一个基于槽点循环轮询仲裁器 (arb)和一个约束跟踪器 (const_trck)。
过程从槽 0 开始:
- 比较检查命令队列前端的命令,并根据计数器找到准备发出的命令,输出就绪标志 (rf_0)
- arb_0 使用这些基于存储体的标志为槽 0 选择一个命令。选中的命令然后传递给 const_trck_0,后者根据时序约束更新计数器。
- 这个过程依次对剩余槽重复
版本 2 (V2)
- V1 的局限: V1 在每个时钟槽(Slot)使用一个通用的仲裁器来处理所有类型的命令,导致效率低下。
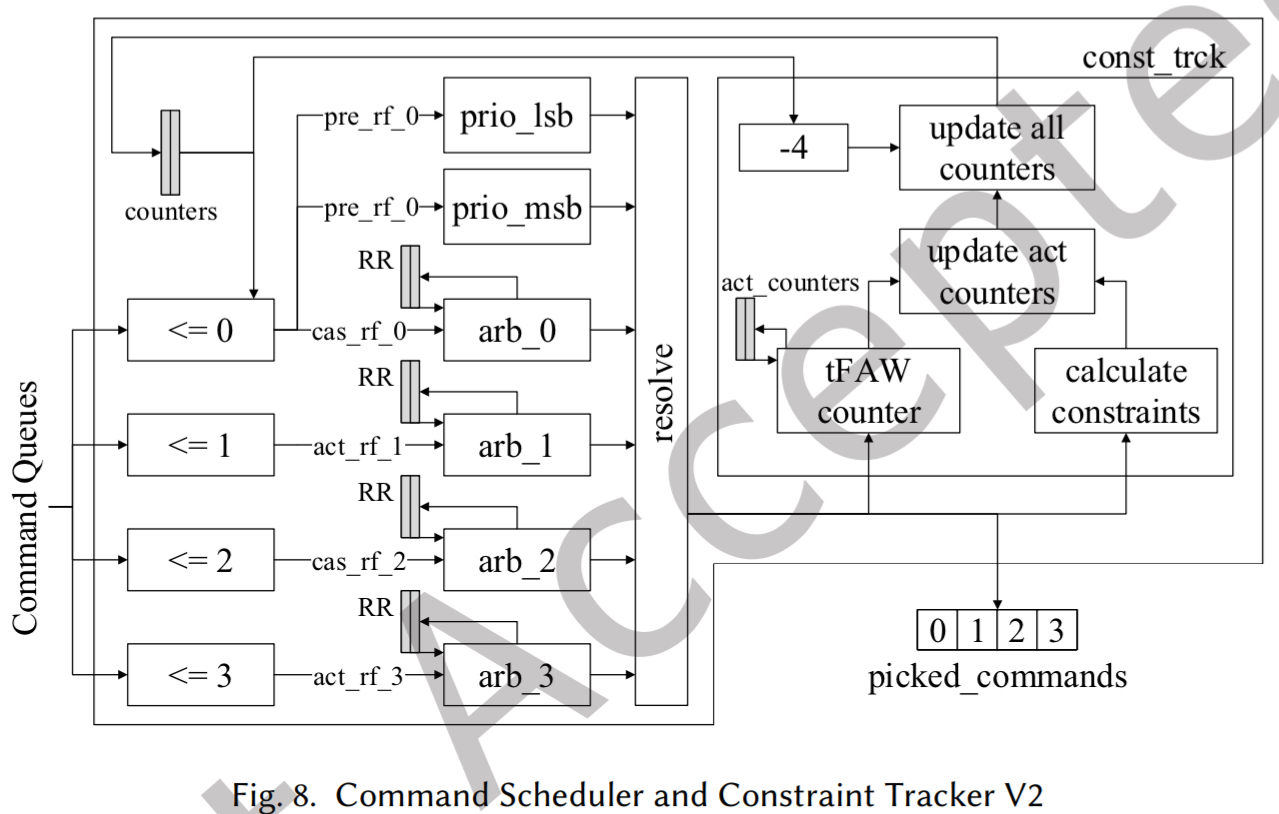
- V2 的核心改进:
- 独立仲裁机制: 利用 PRE(预充电)命令不影响其他 Bank 时序的特性,V2 将仲裁器拆分为四个专用仲裁器(2个用于 ACT,2个用于 CAS),实现并行选择。
- 槽位分配与防争用:
- 由于 PHY 层限制 CAS 命令只能在槽 0 和 2 发出,为避免争用,设计将 ACT 命令分配给槽 1 或 3。
- 剩余的空闲槽位留给 PRE 命令。PRE 由两个优先级编码器选择:一个优先选 Bank 0,另一个优先选高位 Bank,这种固定优先级因 PRE 命令时间间隔大而不会造成不公。
- 工作流程:
- 就绪检测: 比较器检查各 Bank 命令是否就绪(例如:<=0 标志表示命令可发)。它会生成如 cas_rf_0(槽 0 的 CAS 就绪)和 pre_rf_0 等标志。
- 并行仲裁: 所有仲裁器和 PRE 编码器同时运行。PRE 的就绪性仅由比较器判断,不依赖后续分配的特定槽位。
- Resolve 逻辑: 最终决定阶段。先分配获胜的 ACT 和 CAS 到其固定槽位,再将 PRE 填入剩余槽位,最后发送给 const_trck 和 PHY。
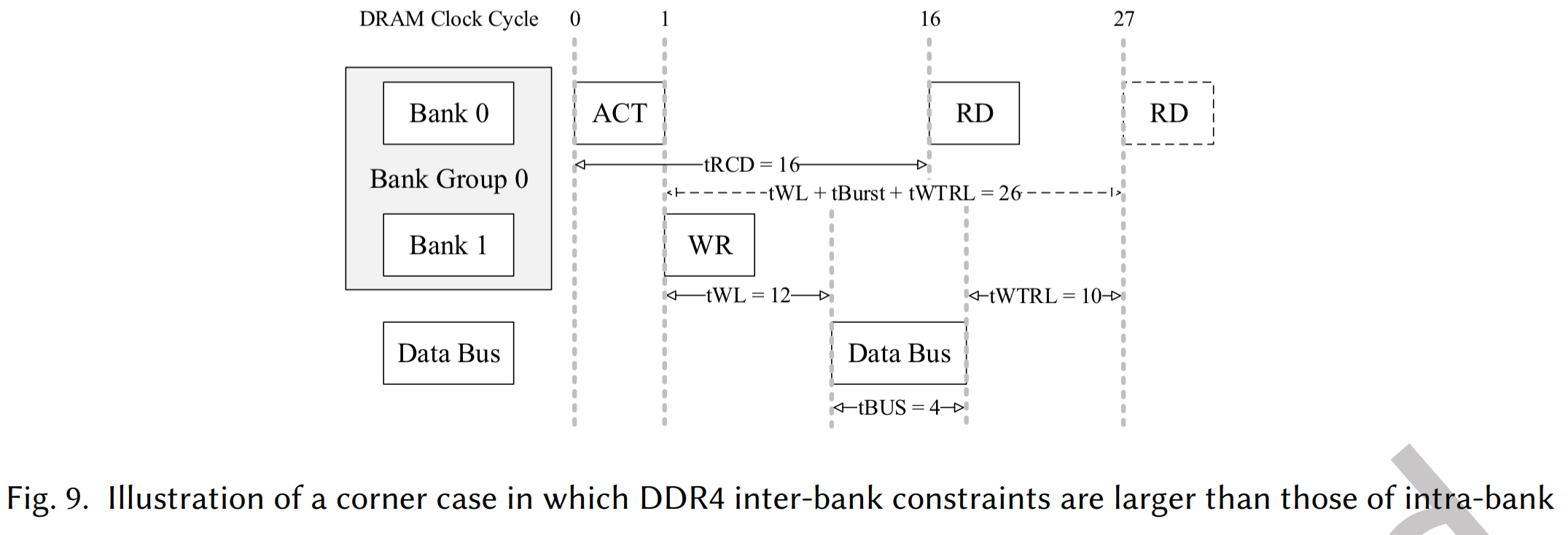
- 约束跟踪与例外情况(图 9):
- 通常 ACT 和 CAS 计数器并行更新。但在处理 ACT (Bank 0) -> WR (Bank 1) -> RD (Bank 0) 这种序列时,存在一个时序“角落情况”:虽然 ACT 对 RD 的片内约束(tRCD)允许在周期 16 发出 RD,但中间插入的 WR 命令带来的片间约束要求 RD 必须等到周期 27。
- 设计通过监控发出的命令序列,强制对 RD 应用更长的片间约束来解决此问题。
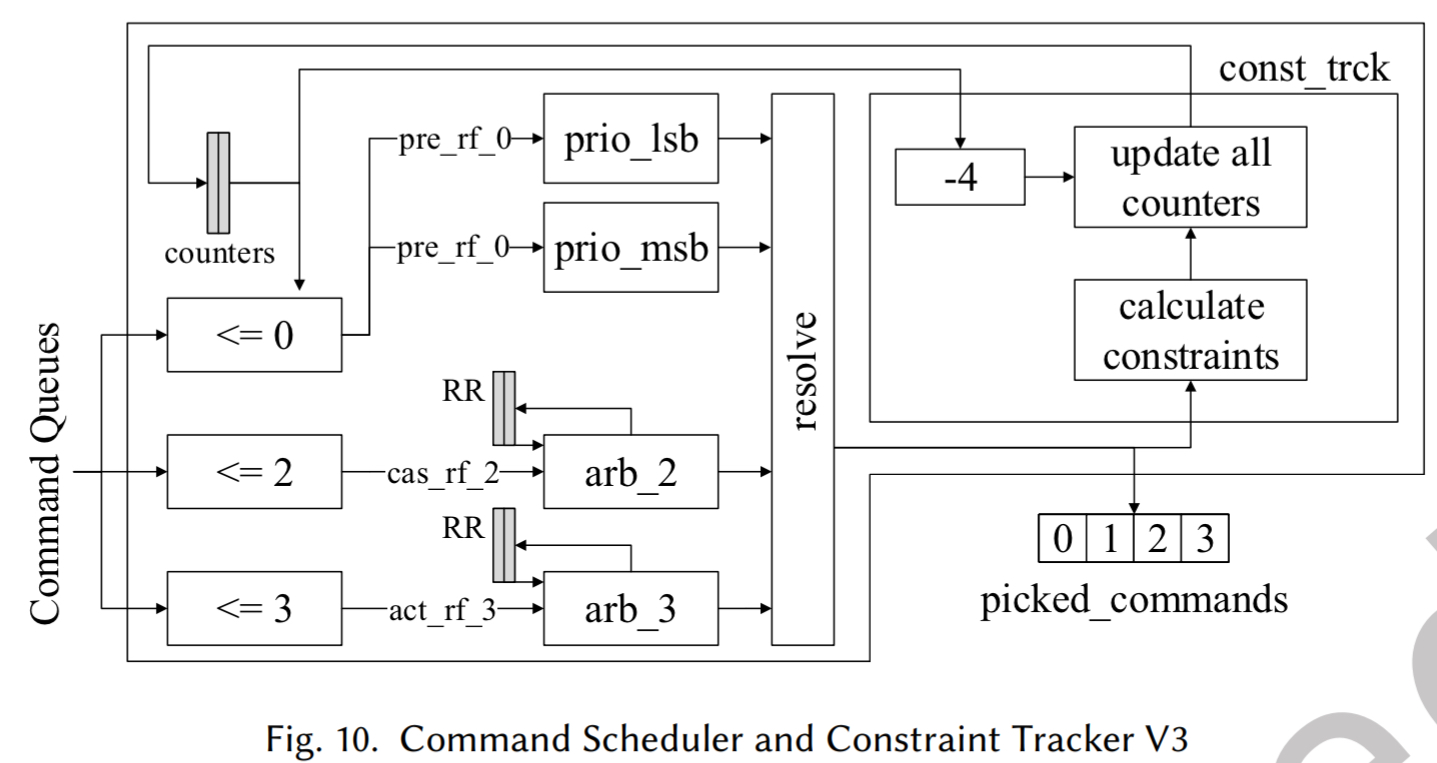
版本 3 (V3)
- Resolve 逻辑的简化(图 10):
- V2 允许 ACT/CAS 在其两个专属槽中自由选择,但这增加了逻辑复杂度。
- V3 策略: 强制固定 CAS 发往槽 2,ACT 发往槽 3,槽 0 和 1 专门留给两个 PRE。
- 收益: 循环轮询仲裁器只需要针对 1 个 ACT 和 1 个 CAS 进行,减少了查找表(LUT)的使用,降低了 FPGA 布线延迟。
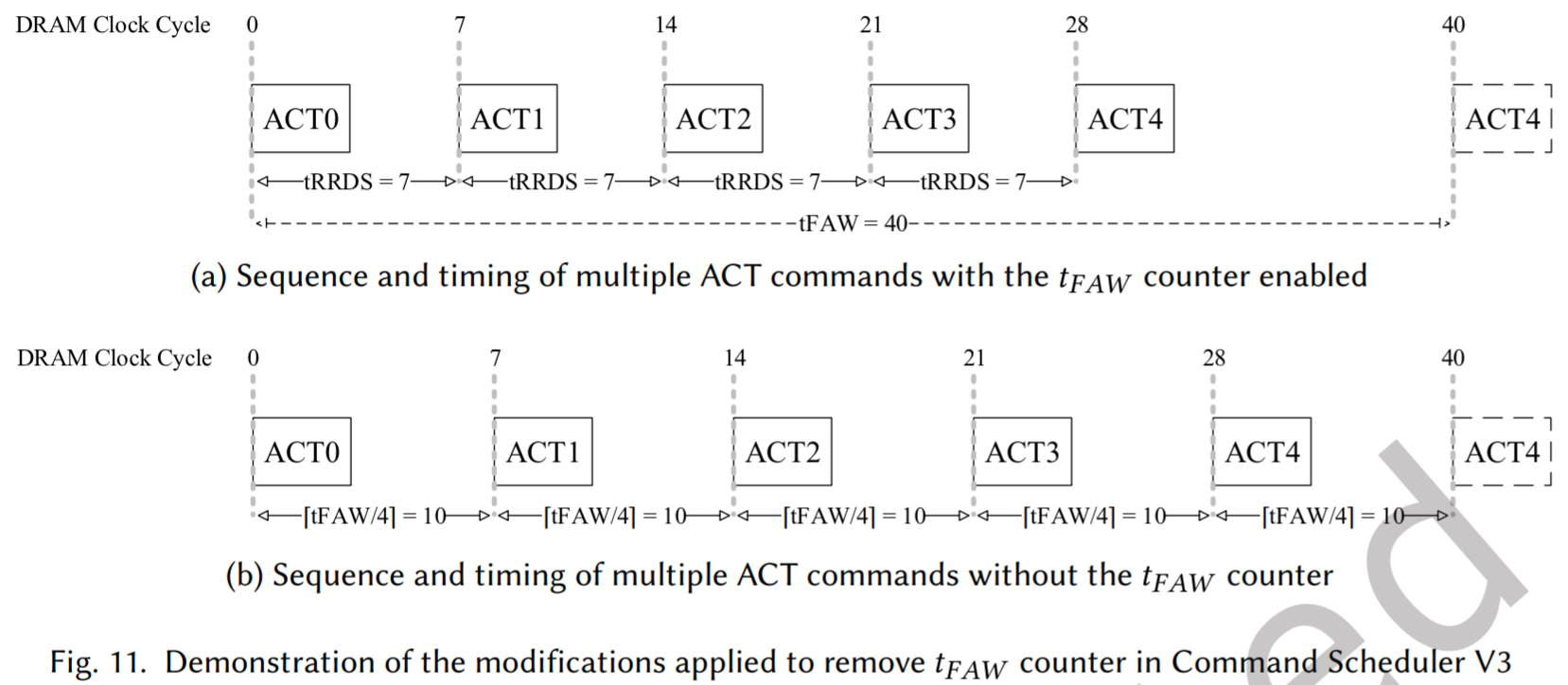
- 移除 tFAW计数器(图 11)
- 问题: tFAW(四激活窗口)通常需要一套复杂的计数器和移位寄存器来跟踪最近 4 次 ACT。
- 解决方案: 通过修改 ACT 到 ACT 的短时序约束 tRRD,使其满足
$$
t_{RRD}=[t_{FAW}/4]
$$ - 效果: 如图 11 所示,通过数学上增大 tRRD,使得每 4 个 ACT 命令的自然间隔总和自动满足 tFAW。这允许完全移除 tFAW 专用计数器及其比较逻辑,减少了逻辑级数。
版本 4 (v 4)
- 核心架构修改(图 12):
- 将约束跟踪器中的时序表拆分为两组独立表:一组存片内约束,一组存片间约束。
- 目的: 确保新计算的约束值总是大于表中的当前值,从而直接覆盖而无需先进行“新值 vs 旧值”的比较。这在 FPGA (LUT 6) 中节省了至少两级逻辑。
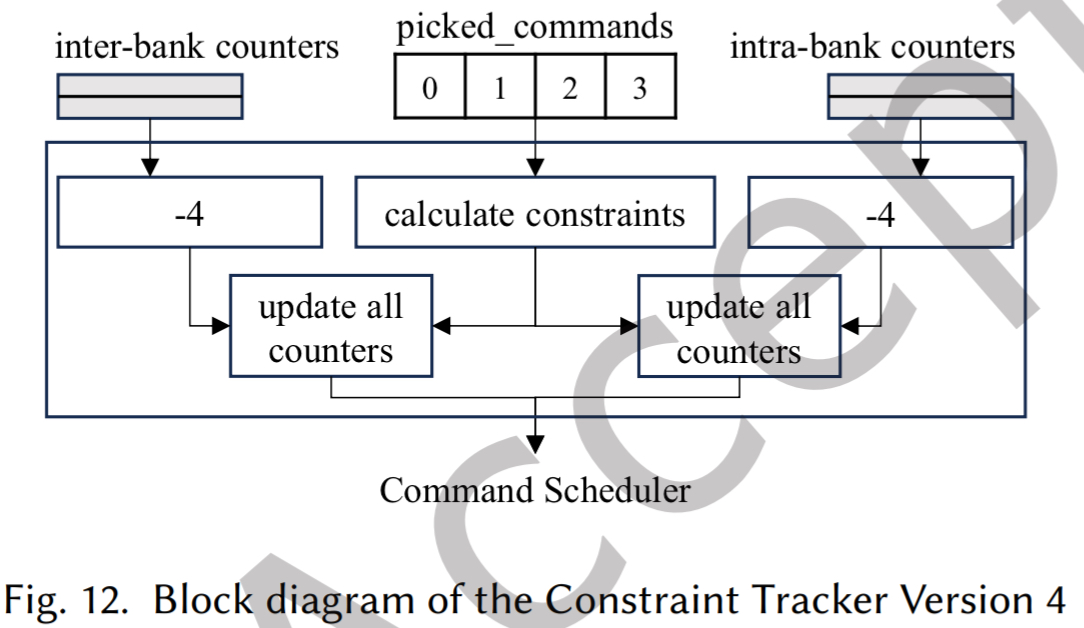
- 例外情况的参数修正(无需比较的保证):
为了确保“直接覆盖”总是安全的,必须处理计算值可能小于表值的特殊情况: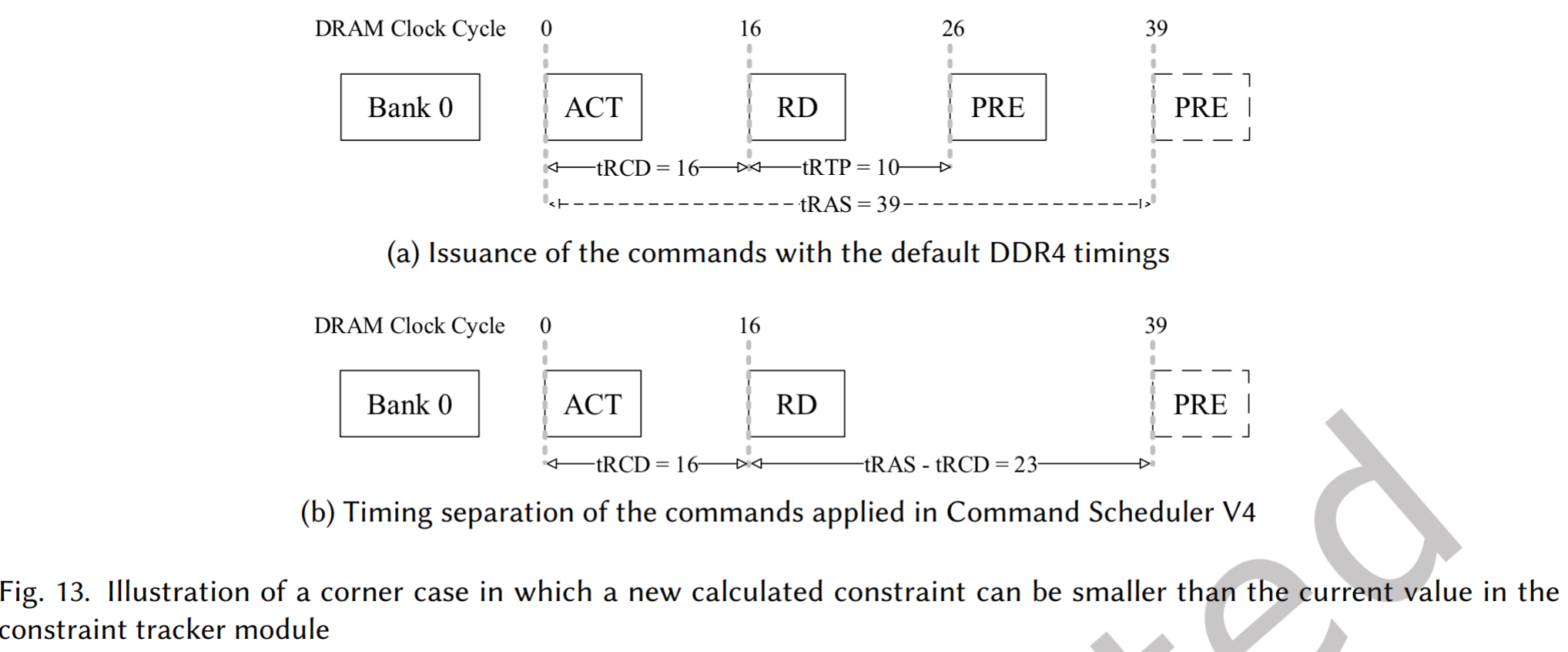
- ACT-RD-PRE 序列(图 13):
- 冲突: RD 发出后更新 PRE 的计数器值为 tRTP。但若 ACT 到 PRE 的约束 tRAS 更长,直接用 tRTP 覆盖会导致违反 tRAS
- 修正: 强行增加 tRTP 的值,令$$t_{RTP}=t_{RAS}-t_{RCD}$$这样无需比较即可确保持续满足 tRAS
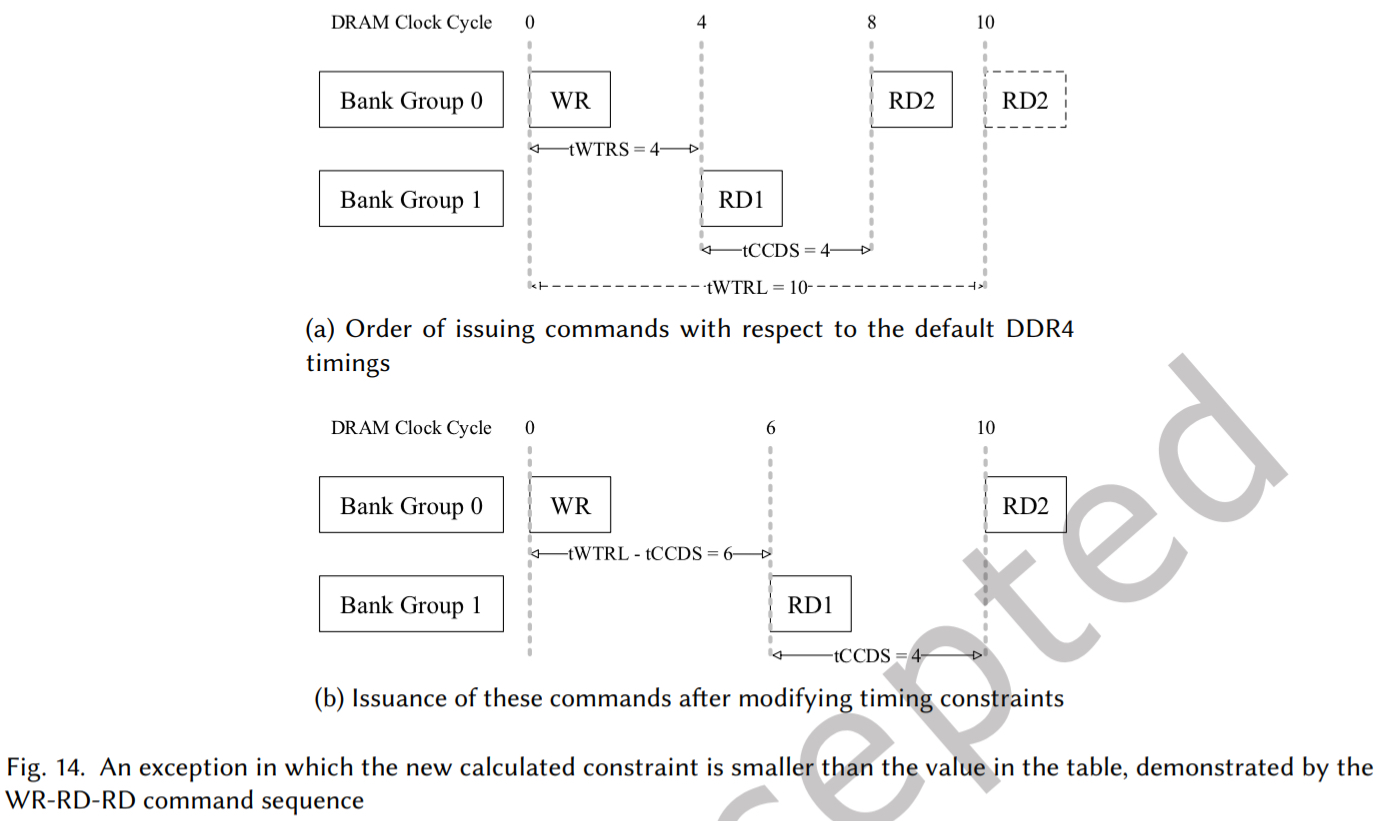
- WR-RD-RD 序列(图 14):
- 冲突: 中间的 RD(不同 Bank Group)会用较短的 tCCD_S 更新约束,可能导致后续同组 RD 违反由 WR 引起的 tWTR_L 约束。
- 修正: 增加 tCCD_S 的值,令$$t_{WTR_S}=t_{WTR_L}-t_{CCD_s}$$
- 代价: 这些修改虽然简化了逻辑(移除了比较器),但可能会轻微延迟关闭请求(Close Request)的处理。
- ACT-RD-PRE 序列(图 13):
版本 5 (V5)
- 两级循环轮询仲裁:
- 原问题: 之前的版本在 8 个 Bank 间直接进行循环轮询(8位向量),旋转和编码至少需要 4 级 LUT 逻辑
- V5 改进: 引入层级化仲裁。
- 第一级: 每个 Bank Group 内部(4选1)并行仲裁。由于只处理 4 个输入,单个 LUT6 即可实现。
- 第二级: 在 Bank Group 之间进行仲裁(最多 4 个组),同样只需单个 LUT。
- 结果: 总逻辑深度减半,大幅提升频率。
- 计数器位宽压缩(6位 -> 3位):
- 修改: const_trck 不再以 DRAM 周期为单位,而是改用 MC 周期(1 MC 周期 = 4 DRAM 周期)来跟踪约束。
- 收益: 计数器位宽从 6 位减少到 3 位。
- 逻辑优化: 比较器现在只需比较 3 位数值与槽位号(0-3)。在 FPGA 中,两个 6 位数的比较需要多级 LUT,而 3 位数的比较仅需一个 LUT6 即可完成。这不仅减少了逻辑级数,还减少了寄存器使用,改善了布线延迟。
验证
行为 RTL 仿真
使用一个仿真基础设施来生成不同模式的读写请求以验证控制器的功能。该基础设施类似于多个 PE 向内存控制器发出内存流量。由 PE 派生的每个流量模式由一个跟踪文件描述,包括地址、操作类型(RD 或 WR)和发出部分写请求,随后对相同地址发出读请求,以确保数据正确性。
1. 性能对比
OpenDRAM 在大多数测试场景下,吞吐量均显著优于工业界标杆(AMD MIG)和学术界开源项目(OPRECOMP)。
- 对比 AMD MIG (工业标准):
- 总体提升: OpenDRAM 的平均性能比 AMD MIG 高出 62%,在特定场景下提升高达 157%。
- 合成测试(Synthetic):
- 在纯读或纯写模式下,两者性能相近。
- 在混合读写(Random Read/Write) 模式下,OpenDRAM V1/V2 吞吐量比 MIG 高出约 40%,V3-V5 高出约 30%。这归功于 OpenDRAM 更好的读写切换最小化策略。
- 加速器内核测试(Real-world workloads):
- 在使用 DDR4-2400-x16 内存时,OpenDRAM 在所有测试内核上的表现均优于 MIG(提升 77% - 107%)。
- 原因分析: OpenDRAM 采用了 FR-FCFS(先就绪先服务) 调度策略和Bank 级并行,能够对请求进行重排序以优先命中行缓冲区(Row Hit)。例如在流式内核(如 dot, dscal)中,OpenDRAM 实现了约 50% 的行命中率,而 MIG 仅为 0%。
- 对比 OPRECOMP (开源竞品):
- OpenDRAM 的平均吞吐量比 OPRECOMP 高出 37%。
- 在读写切换频繁的内核(如 dscal)中,OpenDRAM 的优势最大(提升 267%),因为 OPRECOMP 的读写切换率极高(61%),而 OpenDRAM 优化至 40%。
2. 内部对比
实验展示了调度灵活性(性能)与工作频率之间的权衡。
- V1 (基准): 拥有最高的调度自由度,通常性能最好,但在 FPGA 上能达到的频率最低。
- V2 (并行仲裁):
- 性能与 V1 几乎持平(差异 < 1%)。
- 在某些存在行复用(Row Reuse)的场景(如 trmm)中,由于 V2 延迟了预充电(PRE),性能反而略优于 V1。
- 在写密集型流式应用(如 dscal)中,性能略有下降(约 20%)。
- V3 & V4 (时序与逻辑优化):
- 为了提高频率,引入了更严格的槽位限制和时序参数(如增大 tRRD 、tRTP
- 性能代价: 相比 V2,V3 平均性能下降约 9%;V4 相比 V3 平均下降约 6%。这主要是因为必须等待更长的时序约束才能关闭行或发出激活命令。
- V5 (两级仲裁 & 高频优化):
- 这是最终的高频版本。虽然在某些对 Bank Group 敏感的内核(如 mvt)上吞吐量有波动(相比 V4 有增有减),但它能够支持最高的时钟频率,从而在物理层面弥补逻辑上的调度限制。
3. FPGA 资源占用与频率支持
- 资源占用:
- OpenDRAM 的资源占用(LUTs 和 Registers)与 AMD MIG 相当,甚至在 V5 版本中略低于 MIG。
- 相比 OPRECOMP,OpenDRAM 占用资源较多,因为 OPRECOMP 是非性能优化的极简设计。
- 主要消耗: 大部分逻辑资源消耗在请求调度器(Request Scheduler) 中,主要用于实现 FR-FCFS 重排序逻辑。
- 频率支持:
- 通过 V1 到 V5 的演进,支持的 DDR4 频率逐渐提升。
- V5 版本在测试的 FPGA 上可支持高达 1200 MHz 的内存频率,而 OPRECOMP 仅支持到 1066 MHz。