
(FPT2025)Poco-为任务并行 HLS 编程扩展多生产者多消费者缓冲区支持的新框架
背景与挑战
PoCo 是一个为任务并行 HLS 编程扩展多生产者多消费者缓冲区支持的新框架
首先,当的任务并行系统框架,如 TAPA 和 PASTA, 主要采用单生产者单消费者模型,进行任务通信。这意味着,所有任务间的交互都必须通过点对点的通道(FIFO 流或 PASTA 缓冲区通道)显示实现。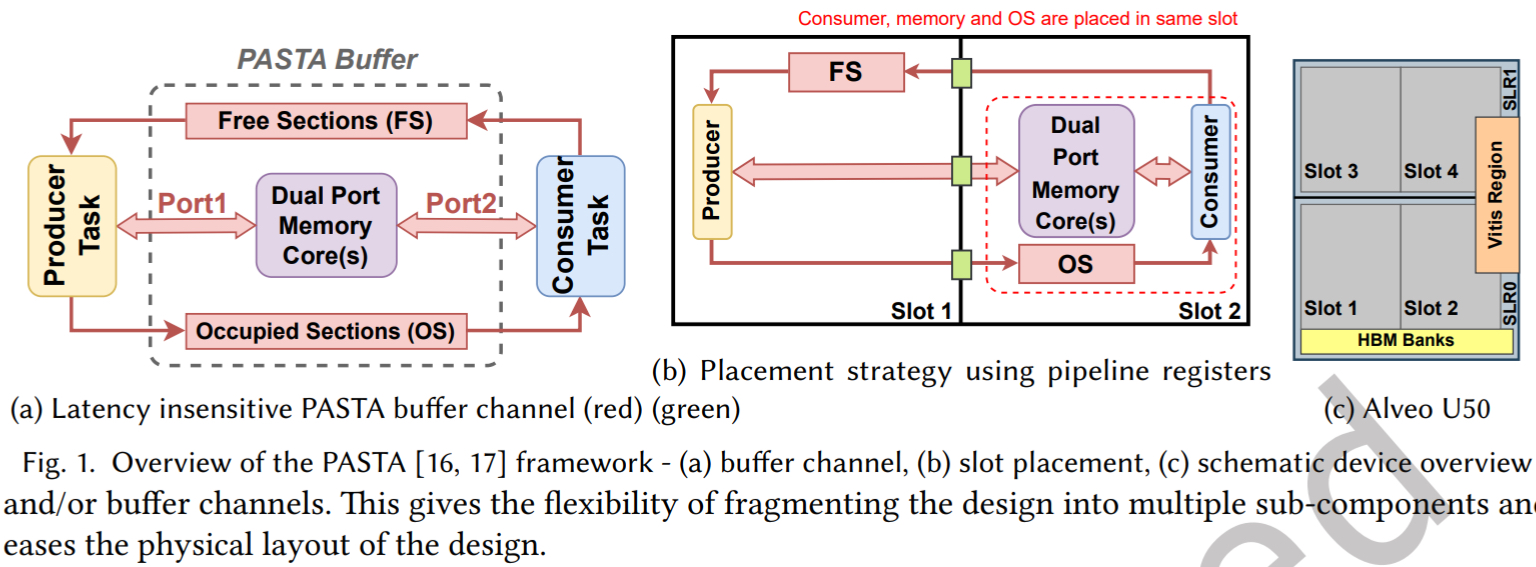
这种 SPSC 模型带来一个根本限制:任务之间无法共享一个统一的视图和片上存储器。如果一个片上内存需要被多个消费者访问,现有 HLS 工具和 TPS 框架都会遇到巨大挑战。
以 Shuffle 内核的例子所示,如图,我们有 4 个生产者任务 T 1 和 2 个消费者任务 T 2. 每个 T 1 写入自己独立的缓冲区,但是每个 T 2 需要读取所有 4 个缓冲区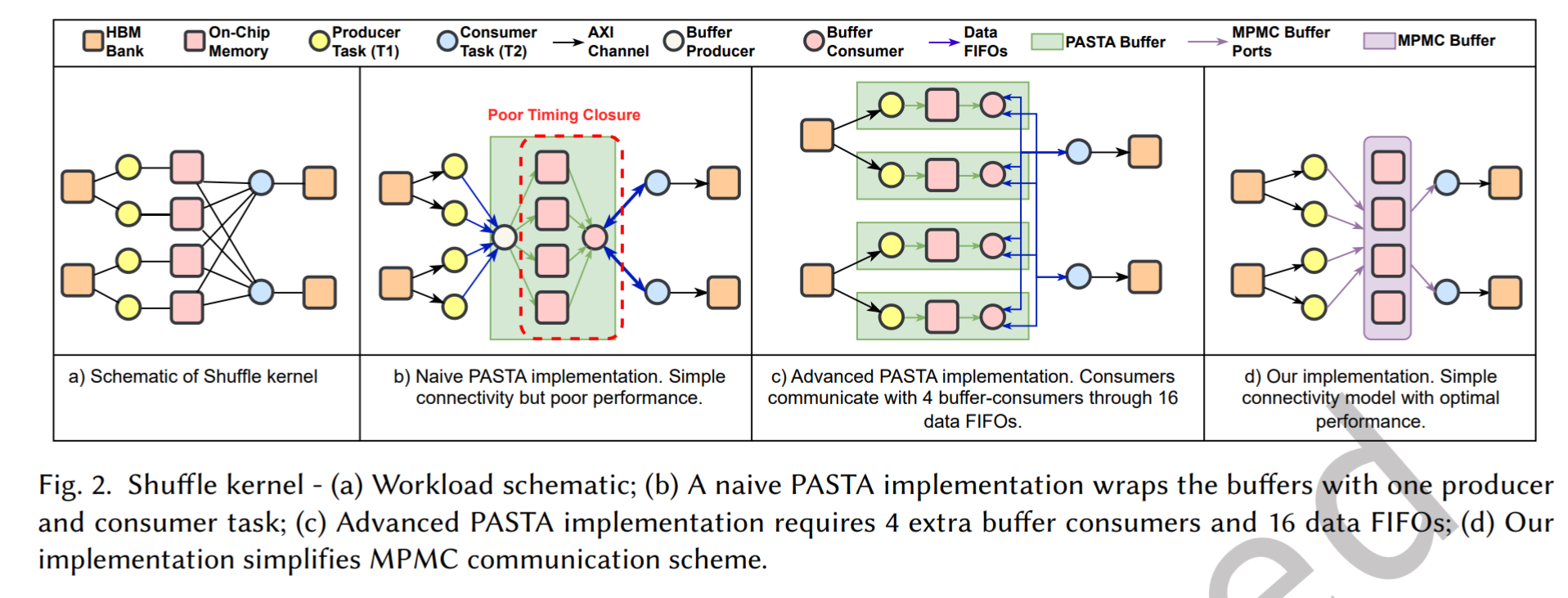
挑战一:复杂的连接性与访问调度
在 SPSC 模型下,实现这种访问模式比较难,一个简单的实现会把 buffer 和 T 2 任务包装成一个巨大的单体任务,这会导致组合逻辑路径过长,难以进行跨芯片区域的布局,频率会很低。
采用 PASTA 实现,需要为每个缓冲区创建专用的消费者任务,然后在它们和真正的 T 2 任务之间再引入大量的数据 FIFO 来传递请求和响应。
如图中所示,这需要 4 个额外的缓冲消费者和 16 个新的 FIFO。这不仅增加了设计的复杂性,其性能还能严重依赖于这些中间任务如何仲裁请求。静态调度会导致带宽利用率低下,而实现动态优先级调度又非常困难,并且会破坏任务独立性的设计哲学
挑战二:控制协调与资源重用
在实际应用中,任务的资源使用通常是动态变化的。例如,不同的 T 1 实例可能产生不同数量的键值对。如果我们为每个任务静态分配固定大小的缓冲区,就必须按最大可能需求来分配,这会迅速耗尽宝贵的片上资源。
理想情况下,我们应该允许 buffer 在 producer 之间动态共享和重用。但这就需要在 producer 之间动态管理地址偏移,防止数据被意外覆盖,这对程序设计来说更为复杂。
挑战三:不平衡管道中的带宽利用不足
标准的 SPSC buffer 为 producer 和 consumer 各分配一个内存端口。但在不平衡管道中(例如 producer 快,consumer 慢),总有一个端口处于闲置状态,导致可用带宽仅利用了 50%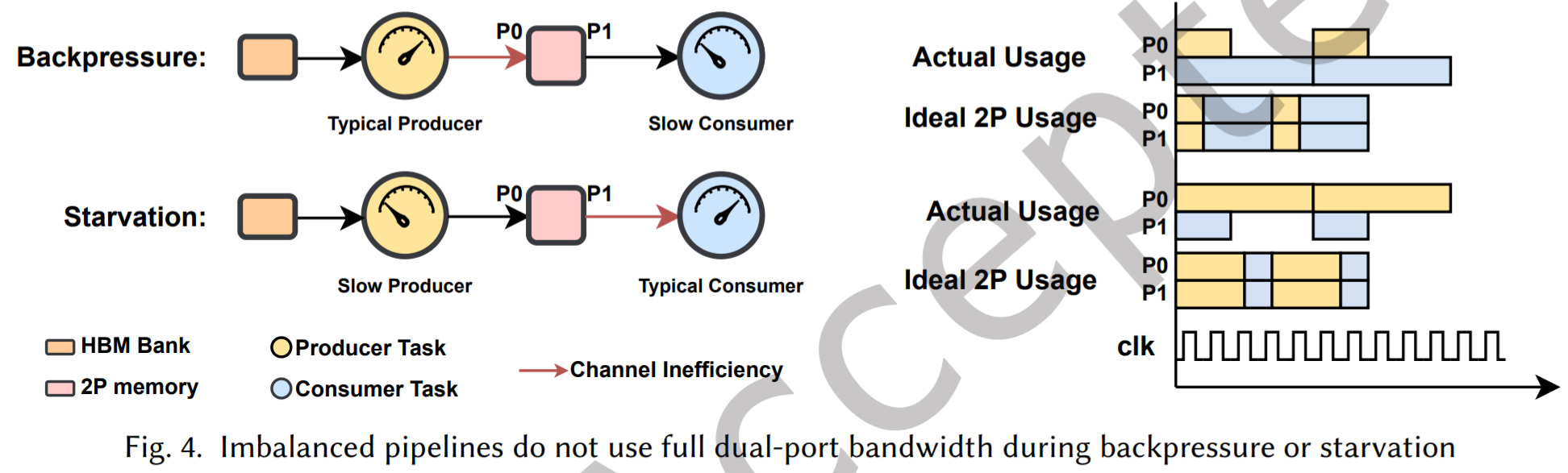
挑战四:布局与物理规划
在现代多芯片 FPGA 上,将大型单体设计放置于单一区域会导致布线拥塞和频率下降。虽然我们可以尝试手动将一些 buffer 移到其他空闲区域,但这些会引入延迟敏感的路径,并且需要重新设计任务的接口和通信逻辑,过程非常繁琐。
解决方案
为了解决这些挑战,该论文提出了 PoCo 框架,其核心是一个共享 MPMC buffer 抽象。让设计者只是在用软件上的共享内存(shared memory),而底层自动处理了所有复杂连线、仲裁和优化
简化的连接模型
在 Poco 中,引入一个新的概念:事务器。它可以是 produce、consumer或者两者兼有。每个事务器通过一个或多个定义好的 MPMC 缓冲区端口连接到共享缓冲区。每个端口实际上是一对请求/响应 FIFO。如图 6 (a)
事务器只需要通过这些标准端口发送读写请求,完全无需关心其他事务器的存在。添加新事务器或扩大 buffer 规模,都不会干扰现有任务。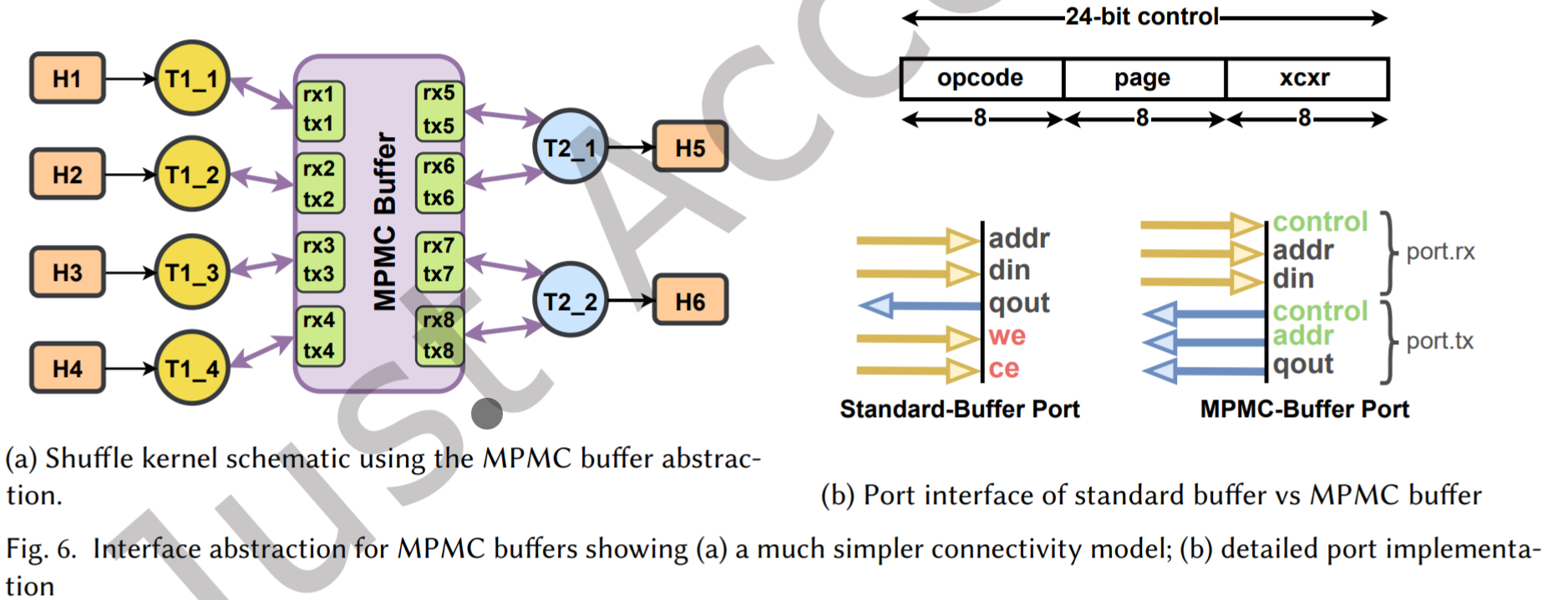
自动协调管理与动态内存分配
在后端实现了自动的协调机制
内存布局:buffer 被组织为多个 Block,每个 Block 包含多个 Page。Page 是最小的可锁定(用于读或写)的连续地址空间单元,地址用 index 访问
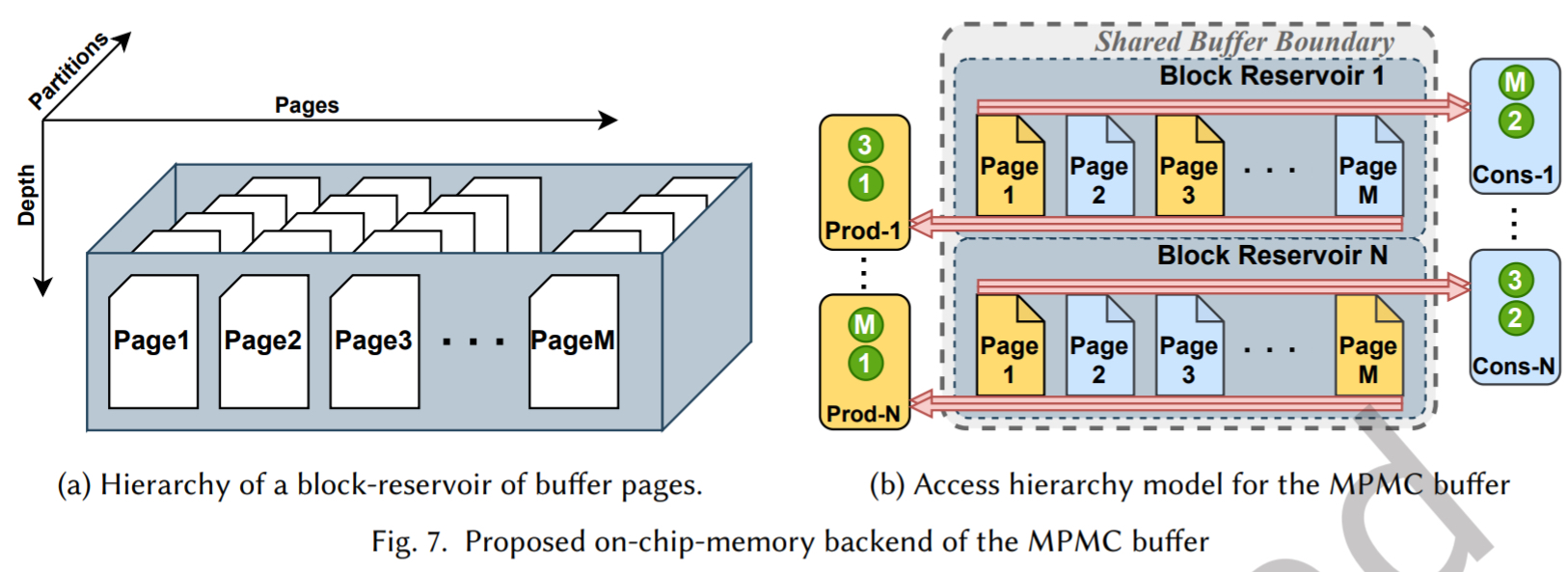
互斥访问:每个 block 由一对访问器管理(一个处理所有写请求,一个处理所有读请求)。我们利用 PASTA 框架为每个页面构建 SPSC 后端,但将页面间的 token 管理封装在父级包装器。通过确保一个页面在同一时刻只能被写入或读取,我们自动防止了数据冒险。
动态分配:我们提供了
allocate和free等 API,允许事务器在运行时动态请求和释放页面。这实质是在静态分配的内存池中动态分配索引。一旦 producer 分配了一个 page 并写入数据,它只需将 page index 共享给 consumer,consumer 就可以立即读取,类似于在软件中共享一个 index
针对不平衡管道的车道交换缓冲区
为解决带宽利用不足的问题,设计了一个 RTL 模块:Lane-Switching Buffer(LBB)。它包装在双端口内存核外部,可以动态地将两个内存端口同时切换给 producer 或 consumer
其工作原理是监控 producer 和 consumer 的活动信号。当检测一方(如 producer)即将获得访问 token 时,它会预先将两个内存端口都切换到 producer 所在的“Lane”。这样,当 producer 活跃时,它可以利用完整的双端口带宽进行写入。这使得即使在生产-消费速度不匹配的场景下,也能最大化内存带宽利用率。将这种优化后的内存抽象称为 Lane-Switching Buffer,并将其作为 MPMC buffer 中每个 page 的实现基础
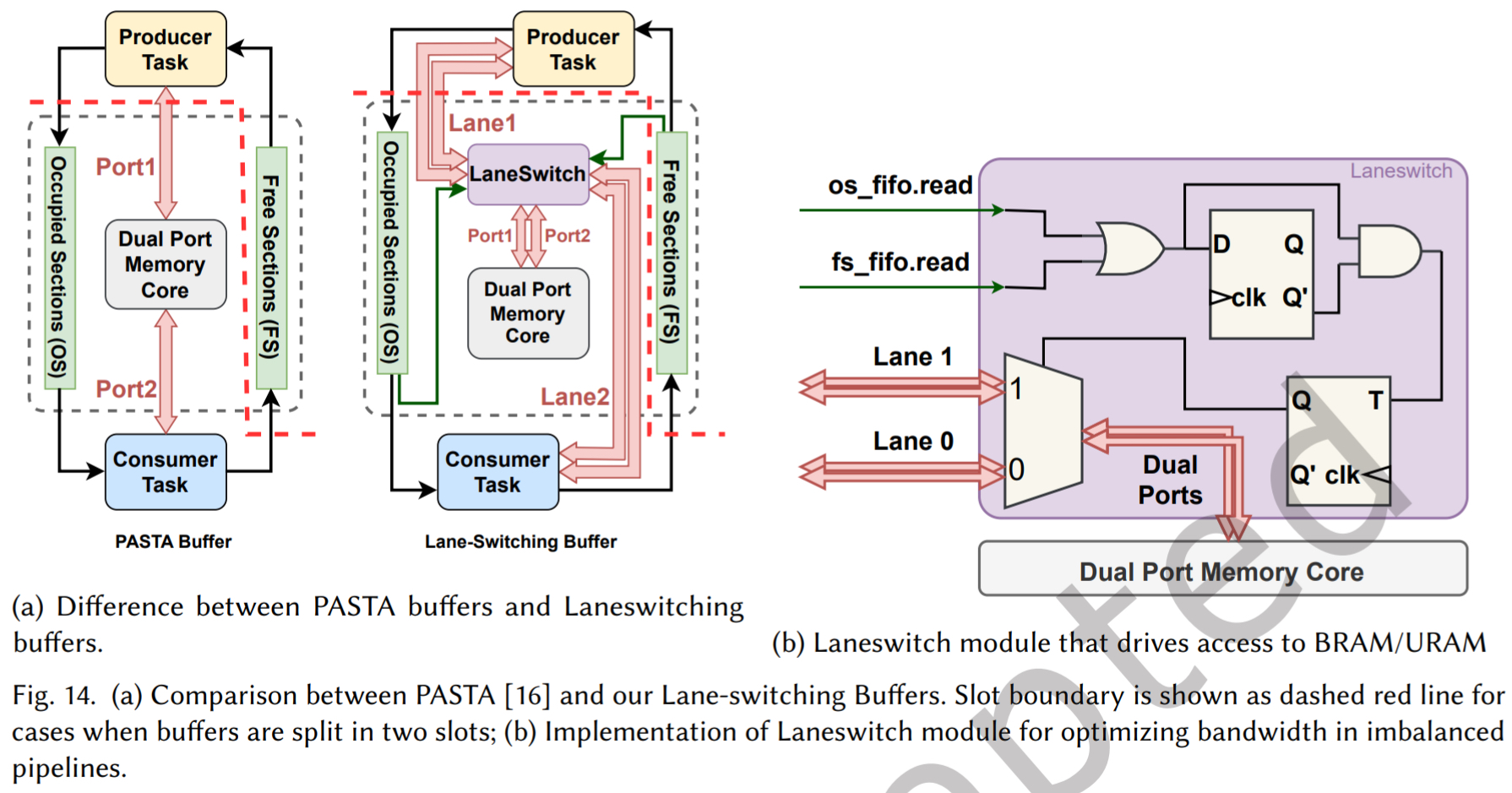
- 传统问题: FPGA 上的 BRAM 通常是双端口的(Port A 和 Port B)。传统的 Ping-Pong Buffer(乒乓缓存)通常固定 Port A 写,Port B 读。如果生产者写得很慢,消费者早就读完了在空等,Port B 就闲置了,这叫“负载不平衡”
- LBB 解决方案:
- PoCo 设计了一个动态开关(Lane Switch)。
- 它允许生产者或消费者 动态地 抢占任意一个空闲端口。
- 如果只在写(没有读),两个端口都可以用来写(双倍写入带宽)。
- 如果只在读,两个端口都可以用来读。
- 效果: 在负载不平衡的应用中,这能节省高达 50% 的 BRAM 资源,因为你不需要为了带宽去复制多份内存。
布局感知的物理规划
Poco 框架的架构天然有利于物理规划
- 其内部数据路经(如请求路由器、数据请求解析器等)由多个独立相同的单元任务组成,它们之间没有组合逻辑连接,因此可以分散布局在芯片的不同位置
- 除了 LBB 与访问器之间的接口,其他所有任务间连接都是延迟不敏感的,可以通过插入流水线寄存器来满足时序要求。
- 这使得该论文的工具能够自动识别那些对延迟不敏感的 buffer block,并将它们从拥挤的芯片区域移动到空闲区域。如图 5 所示,移动这些块只会增加固定的访问延迟,而不会影响吞吐量,从而在缓解拥塞的同时获得显著的频率提升。
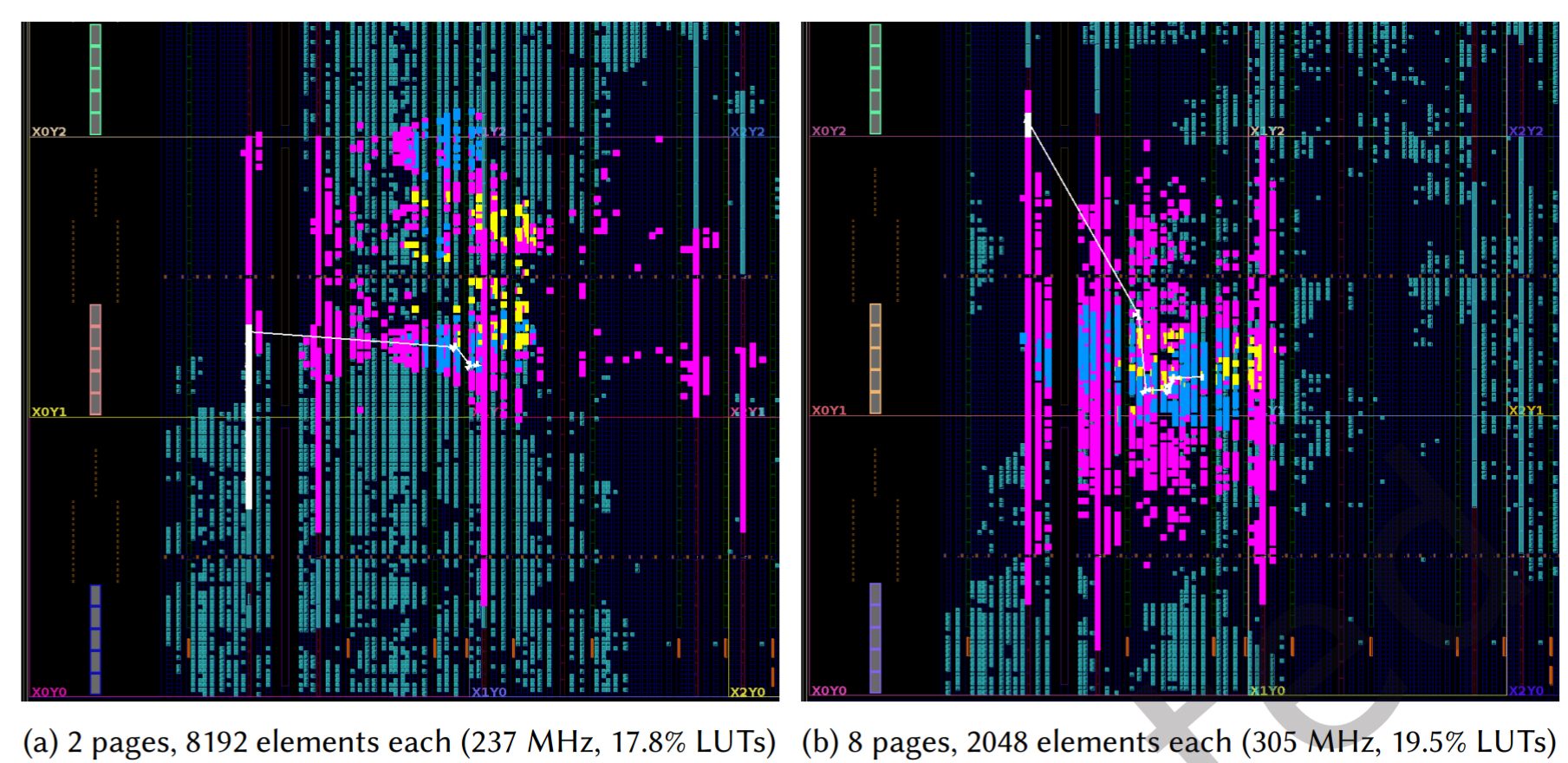
- 问题: 如果把所有内存都放在一个地方,远处的任务访问它就会导致时序违例(Timing Violation),频率降低
- PoCo 的方法:
- 它将共享内存打散成多个 Block
- 这些 Block 是独立的,通过互连网络连接。
- PoCo 的算法会自动计算,把 Block 放置在离使用它的任务最近的物理区域(SLR)。
- 它会在跨越长距离的连线上自动插入“流水线寄存器”(Pipeline Registers),虽然增加了一点点延迟(Latency),但极大地提高了运行频率(Frequency)。
实现架构与工作流程
PoCo 顶层架构包含多个自由运行的任务,构成内部数据路经。PoCo 不直接拉一根线去读内存,而是构建了一个类似“微型网络”的系统,整个读写过程变成了“发送请求->处理->接收响应”:
- RQR(Request Router)请求路由器:将请求按类型(控制/数据)路由
- CRP (Control Request Parser) & PGM (Page Manager) 控制路经:
- 专门处理
alloc(申请内存页)和free(释放内存页) - PGM 是一个硬件模块,维护一个位图(Bitmap)或空闲链表,能在一个时钟周期找到空闲内存页并返回其索引。这实现了动态内存管理
- 专门处理
- DRP (Data Request Parser)数据路经:处理具体的
read和write数据请求 - Omega-MIN (Omega Network) :一个高效的多级交换网络,负责将请求从任意事务器路由到正确的目标访问器。它负责将 T 个用户任务的请求,路由到 N 个内存块(Blocks)中去。这种网络结构在硬件中非常高效,延迟低且吞吐量大。
- I/OHD(Input/Output Handler):即 block 的访问器,负责执行具体的读写操作,并与 Lane-Switching Buffer Block 交互。锁定具体的内存页 (Mutex),确保同一时间只有一个任务在写入,防止数据冲突。
- 响应再通过 Omega-MIN 网络返回给响应生成器,最终送回事务器
整个工具流基于 PASTA 构建。用户使用我们提供的 API 编写任务并行程序。前端解析器提取任务和 MPMC buffer 配置,生成相应的任务图和 RTL 模块。所有任务经 Vitis HLS 编译后,由我们粗粒度物理规划器(基于 AutoBridge)进行初始布局。最后,结合资源报告生成的约束,进行最终布局布线,生成比特流。
架构图: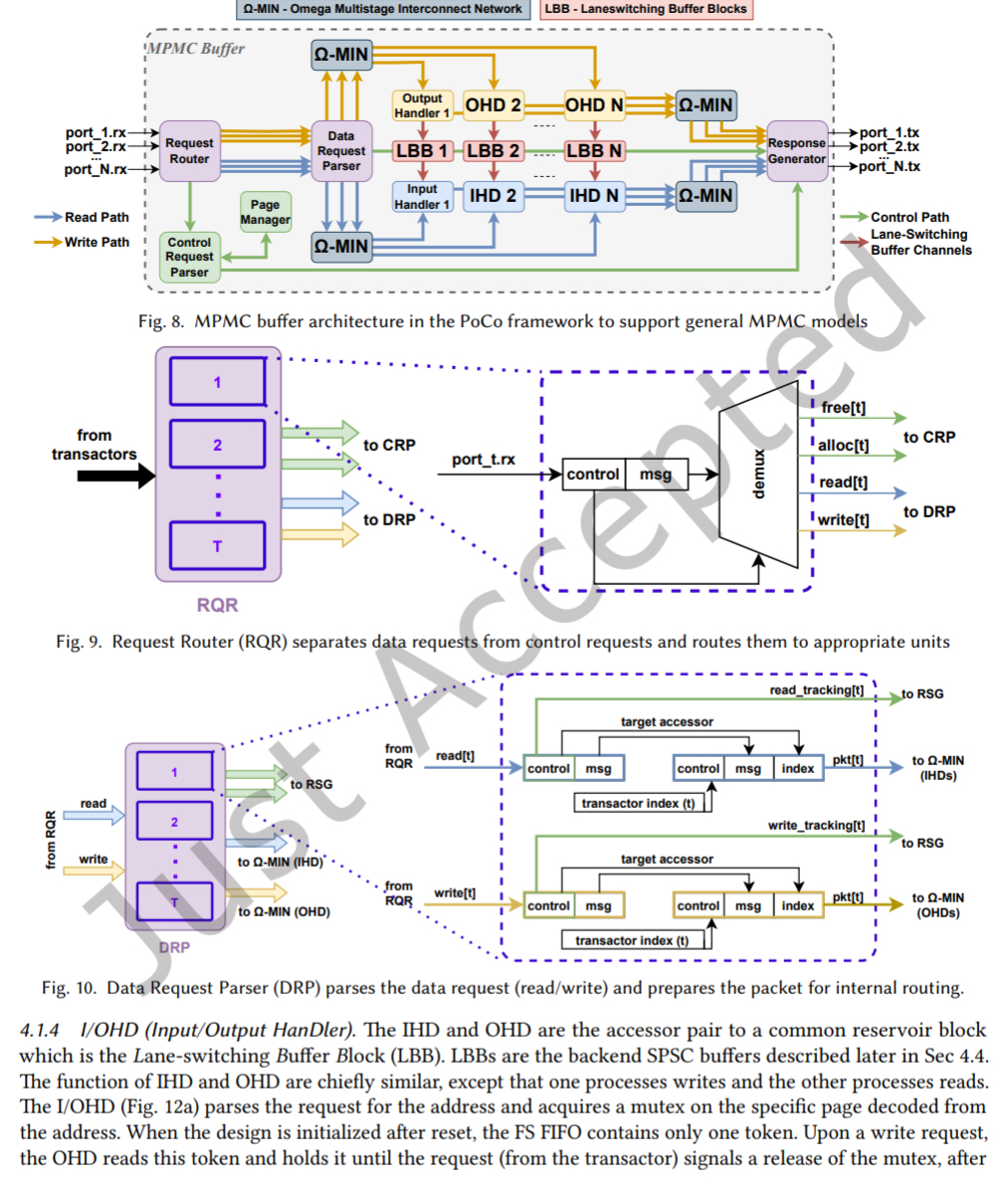
工作流程: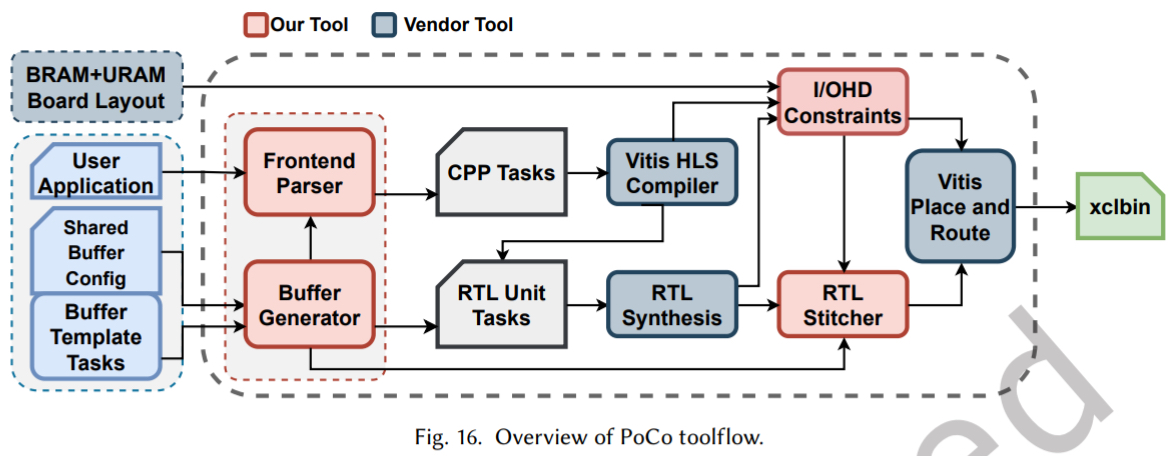
实验结果
这篇文章的实验结果是真的很多,做的很完整,从 page 24-31 都在对比不同的架构 (SPSTA, TAPA), 以及不同的设计大小 (standard, Multi-die)
开源
*开源仓库: https://github.com/SFU-HiAccel/poco
问答
是否与 TAPA 框架进行比较?在论文的实验结果中看到了对比数据。我的问题是,直观上看,TAPA 也使用高级综合和自动布局技术。那么,相比 TAPA,你的框架主要优势是什么?是什么带来了频率上的大幅提升?
这是一个非常好的问题。TAPA 最大限制在于它不支持 shared buffer 模型。在 TAPA 中,任务间只能通过点对点的 FIFO 流连接。
这意味着,如果一个进程需要访问多个大型数组,或者多个任务需要访问同一块内存,所有这些数据都必须通过 FIFO 接口进行打包和传输。这迫使整个计算任务连同其所需的所有缓冲区,都必须放置在同一个 FPGA 槽位中。
这正是 TAPA 在最终实现中所做的,也是其频率表现不佳的主要原因——它试图将大量组合逻辑和 buffer 积压在同一个区域,导致布线拥塞和长路经延迟。它无法利用空闲的芯片区域,因为其架构没有在任务和 shared memory 之间提供带寄存器的、延迟不敏感的接口
因此,PoCo 和 TAPA 在 buffer 与任务的接口上是根本不同的。TAPA 是直接、紧密的内存连接,而 PoCo 是通过标准化的请求/响应与 shared buffer 通信。这种架构分离使我们能够将计算任务和内存块解耦,并利用我们框架的布局优化算法,将 buffer 灵活地分布到不同芯片区域,从而显著提升整体频率