
(FPT2025)简化FPGA开发:敏捷设计流程带来的挑战和机遇——张薇教授(香港科技大学)
HLS 编译流程与设计空间爆炸

这张图展示了 HLS 生成 RTL 代码的流程并给出了一个示例,展示了增加 HLS pragma 之后代码的区别
- gemm(矩阵乘法)的原始代码(gemm.cpp)和优化代码(gemm_opt.cpp)
- 原始代码使用三重嵌套循环实现矩阵乘法
- 通过添加
#pragma HLS UNROLL factor=2指令,HLS工具会将循环展开,让多个计算同时进行,从而大幅提高速度。
可以看到生成的 verilog 的不同
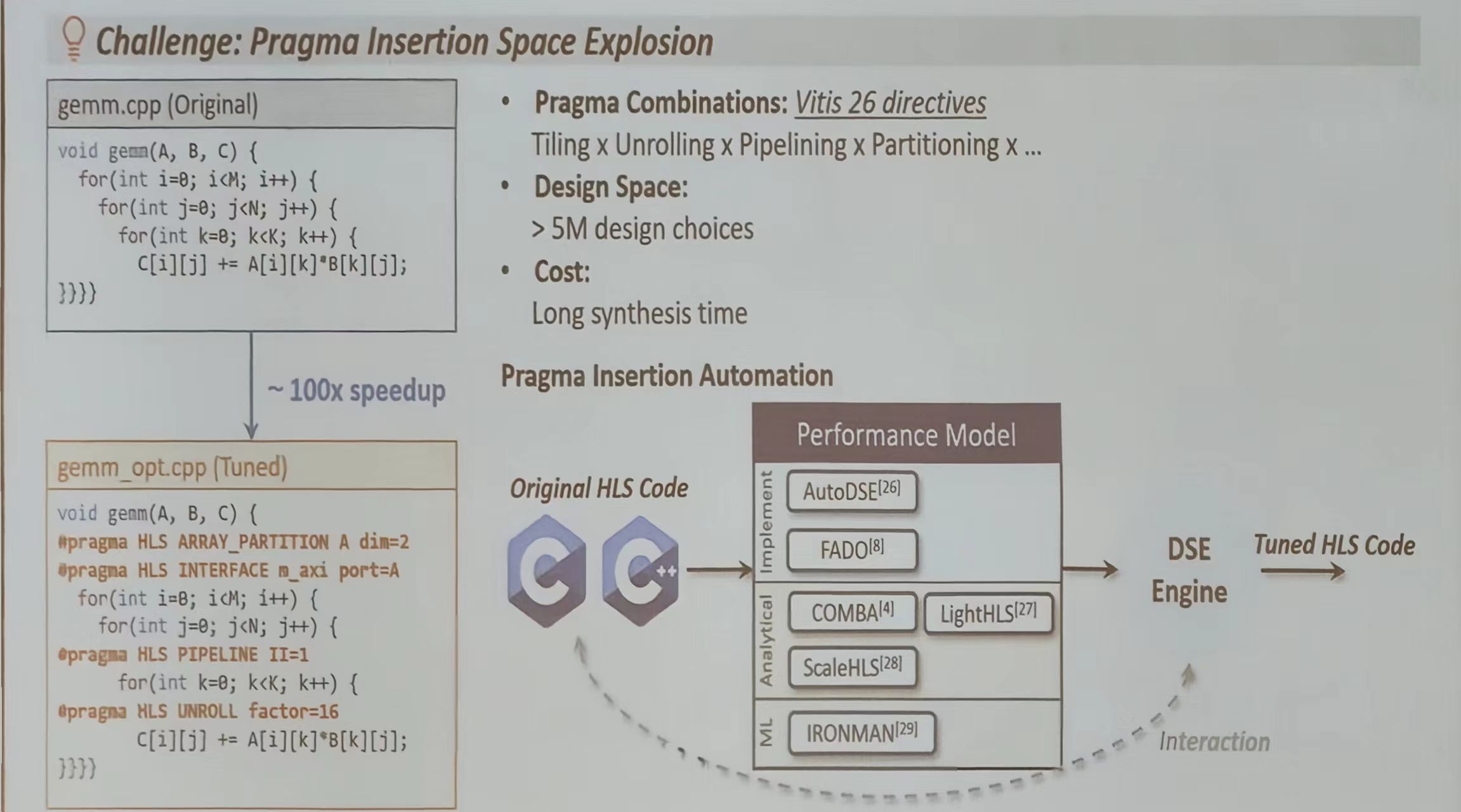
但问题在于:HLS 有26个常用指令,每个指令有多个参数,组合起来有500万种可能的配置。想象一下,如果每个配置都需要人工尝试,开发人员需要尝试500万次才能找到最佳方案,这显然是不现实的。
所以,HLS 工具需要自动优化能力,帮助开发人员从500万种可能性中快速找到最佳配置。优化后,性能可以提升100倍,这说明了 HLS 指令优化的巨大价值。
图中指出了一些性能优化模型结合 DSE 将原始 HLS 迭代生成调优后的 HLS 代码
分析式性能建模的整体框架
性能建模通常从 C/C++代码开始,通过一个特征化库(Characterized Library)进行分析,最终构建出分析模型 (Analytical Model)。该模型可用于对硬件设计的性能、功耗和面积(PPA)进行早期评估,以 COMBA (ICCAD’17)为例,展示了一段带有函数调用的循环的代码以及对应的控制流图,说明如何通过将结构化分析将逻辑转化为可量化的模型
从代码分析出发,通过建立精确的循环流水线、循环展开、数据流 II 和内存资源等模型,能够高精度地预测硬件行为的性能与资源消耗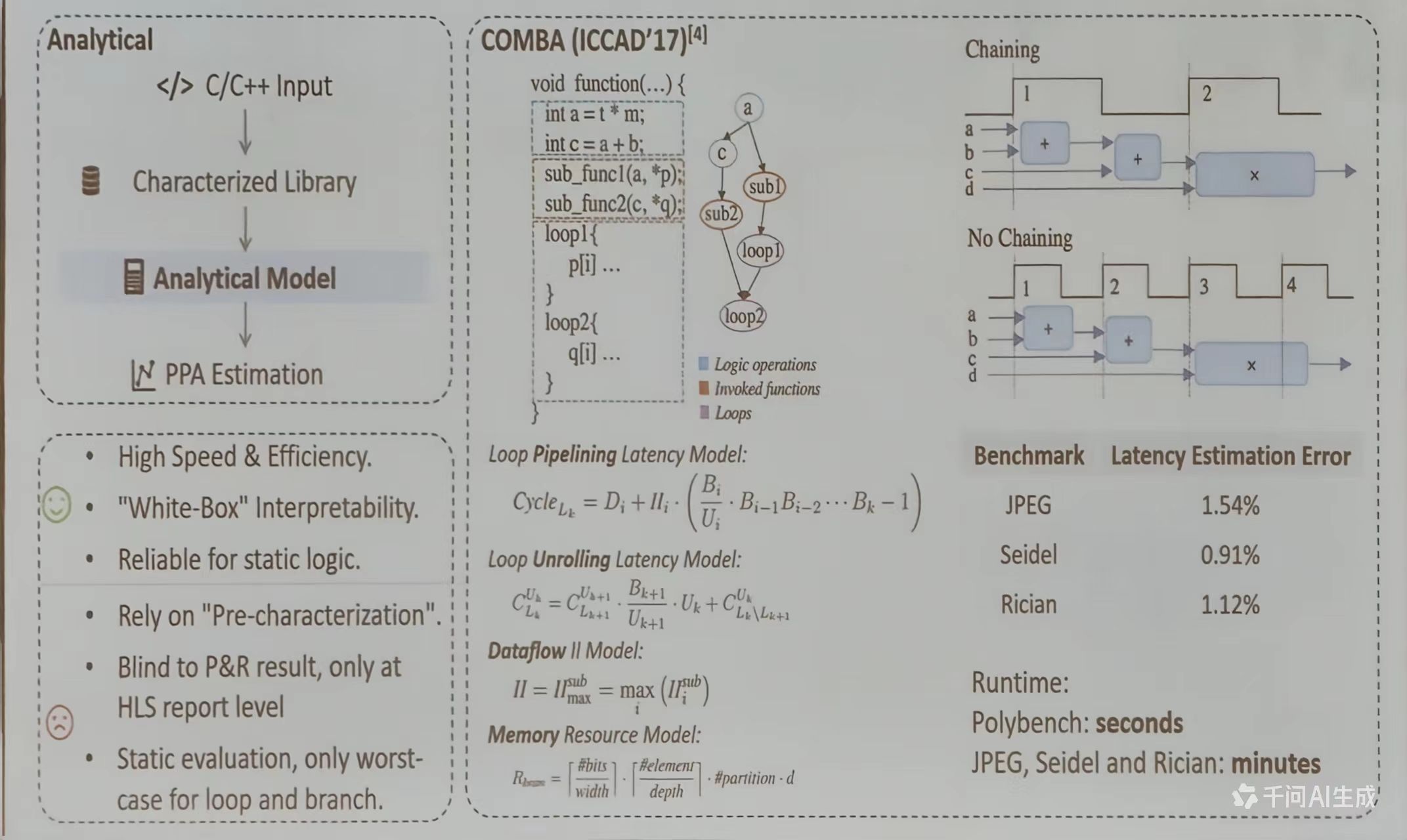
核心延迟建模的方法
性能建模的关键在于确预测程序(尤其是循环结构)的执行延迟。图中重点阐述了两种主流的延迟模型
- 循环流水线延迟模型(Loop Pipelining Latency Model): 该模型通过公式计算循环在流水线执行的总周期数,综合考虑了单次迭代的延迟(D_i)、迭代间隔 (II_i)、循环带宽 (B_i)和实际利用率 (U_i) 等因素。反映了在现代硬件(如 FPGA、ASIC)中,循环并非简单串行执行,而是通过流水线重叠不同迭代来提升性能
$$
Cycle_{L_k}=D_i+II_i\cdot (\frac{B_i}{U_i}\cdot B_{i-1}B_{i-2}\cdot\cdot\cdot B_k-1)
$$ - 循环展开延迟模型(Loop Unrolling Latency Model): 当采用循环展开优化时,延迟计算变得更为复杂。该模型通过递推公式,将外层循环与内层展开后的循环延迟结合起来计算,考虑了不同层级的带宽利用和展开因子 (U_k),用于评估展开策略对整体延迟的影响
$$
C_{L_k}^{U_k}=C_{L_k+1}^{U_{k+1}}\cdot \frac{B_{k+1}}{U_{k+1}}\cdot U_k+C_{L_k/ L_{k+1}}^{U_k}
$$
迭代间隔与资源约束建模
除了延迟、性能建模还需考虑资源限制对并行度的约束
- 数据流 II 模型(Dataflow IOI Model): 迭代间隔 (II)是流水线中启动连续两次迭代所需的最小周期数。该模型指出,整体 II 取决于所有子模块中最大的 II, 这通常是由最慢的资源或数据依赖决定的
$$
II=II_{max}^{sub}=max_{i}(II_i^{sub})
$$ - 内存资源模型 (Memory Resource Model):该模型公式用于估算实现特定数据结构(如数组)所需的资源存储量。它考虑了数据位宽、存储深度、分区数量等多个维度,确保设计在满足性能目标的同时不超出可用的片上存储资源
$$
R_{bom}=[\frac{\#bits}{width}]\cdot [\frac{\#element}{depth}]\cdot \#partition \cdot d
$$
优化技术:链接(Chaining)
图示对比了链接 (Chaining)与非链接 (No Chaining)的操作流程。链接允许将多个逻辑操作在同一个时钟周期内组合执行,从而减少总延迟。
实验结果
最后,图片通过基准测试展示了该性能建模方法的准确性和实用性:
- 在JPEG、Seidel、Rician等测试用例中,模型预测的延迟与实际硬件实现的误差非常小(1.54%、0.91%、1.12%),证明了其高精度。
- 在运行时间方面,对于 Polybench 测试集,模型生成仅需秒级;而对于更复杂的应用(如 JPEG、Seidel、Rician),也只需分钟级,体现了该方法在实际工程中的高效性。
GNN 性能预测
用图神经网络 (GNN)破解传统高性能计算系统设计中的性能预测难题。其核心思想是将硬件设计转化为图结构,让 GNN 学习从设计特征到最终功耗、性能和面积 (PPA 的复杂映射关系,从而实现快速、准确的早期评估,对比传统方法与基于 GNN 的性能预测:
GNN 实现性能预测
GNN 解决了传统方式难以处理的两个问题:设计空间的指数级复杂性和高级优化指令 (pragma)带来的非线性影响
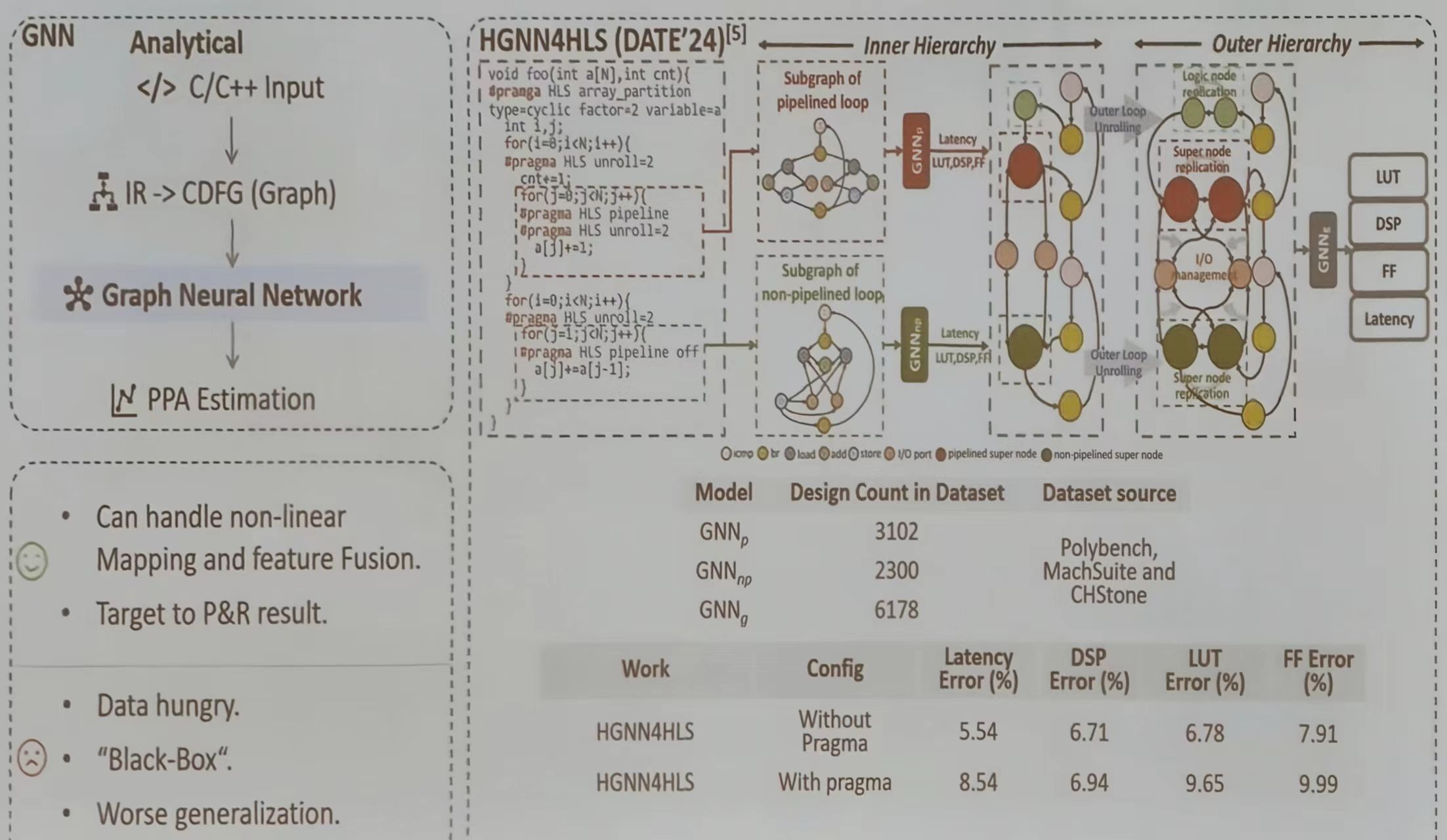
图构建:将设计转化为 CDFG
如图所示,GNN 的输入不是原始代码,而是从 C/C++代码经过中间表示 (IR)转换得到的控制数据流图。图中的节点表示运算符(如加法、乘法、访存),边则代表数据控制依赖关系。这种表示方法保留了程序的结构和并行性信息层次化建模
层次化图结构是实现复杂设计的关键。它通过内存(循环子图)和外层(模块间连接)的分层抽象,让 GNN 能够理解局部计算模式(如一个流水线循环),再整合全局互连和优化(如循环展开、数组分割)的影响,融合不同来源和抽象级别的设计特征消息传递与预测
GNN 通过“消息传递”机制再图结构中迭代聚合邻域信息。在这个过程中,模型能学习到特定操作(比如一个乘法器)再特定上下文(如处于一个深度流水线中)下对资源和时序的真实影响,最终聚合全图信息,输出对延迟 (Latency)、查找表 (LUT)、触发器 (FF)、数字信号处理器(DSP)等关键指标的预测
DSE 算法比较
| 特性维度 | 迭代搜索 (启发式/ML) | 数学规划 (MILP/NLP) | LLM 驱动的 DSE (新趋势) |
|---|---|---|---|
| 核心思想 | 模拟自然或学习过程进行启发式探索 | 将设计空间转化为数学优化问题并精确求解 | 利用大语言模型的常识与代码能力生成设计 |
| 优化目标 | 通用目标,大规模近似帕累托前沿 | 特定领域,追求理论最优解或高质量可行解 | 将自然语言描述直接转化为优化设计点 |
| 关键优点 | 灵活性高,适用于黑盒模型;全局探索能力强 | 最优性有保证,提供整体视角;可严格建模复杂约束 | 样本效率极高(零样本/少样本);端到端自动化;交互直观 |
| 主要挑战 | 样本效率低;对超参数敏感;易陷局部最优 | 建模复杂;求解耗时;问题规模扩大时复杂度爆炸 | 结果不可靠(幻觉、不一致);缺乏理论保证;领域知识依赖强 |
| 典型应用 | 早期、大规模设计空间初筛;HLS PPA 预测模型优化 | 脉动阵列、Stencil 计算等规则结构化硬件的精细优化 | 快速原型设计;基于高层描述探索架构灵感;自动化设计脚本生成 |
未来的 DSE 趋势并非只能采用一种方法,而是多种方法的融合:利用 LLM 快速生成高质量起点,通过数学规划在局部进行精细调优,再借助基于 ML 的迭代搜索在全局范围内验证鲁棒性,从而构建出更强大、更智能的下一代 EDA 工具链
HLS 编译流程的演变
传统的 HLS 编译流程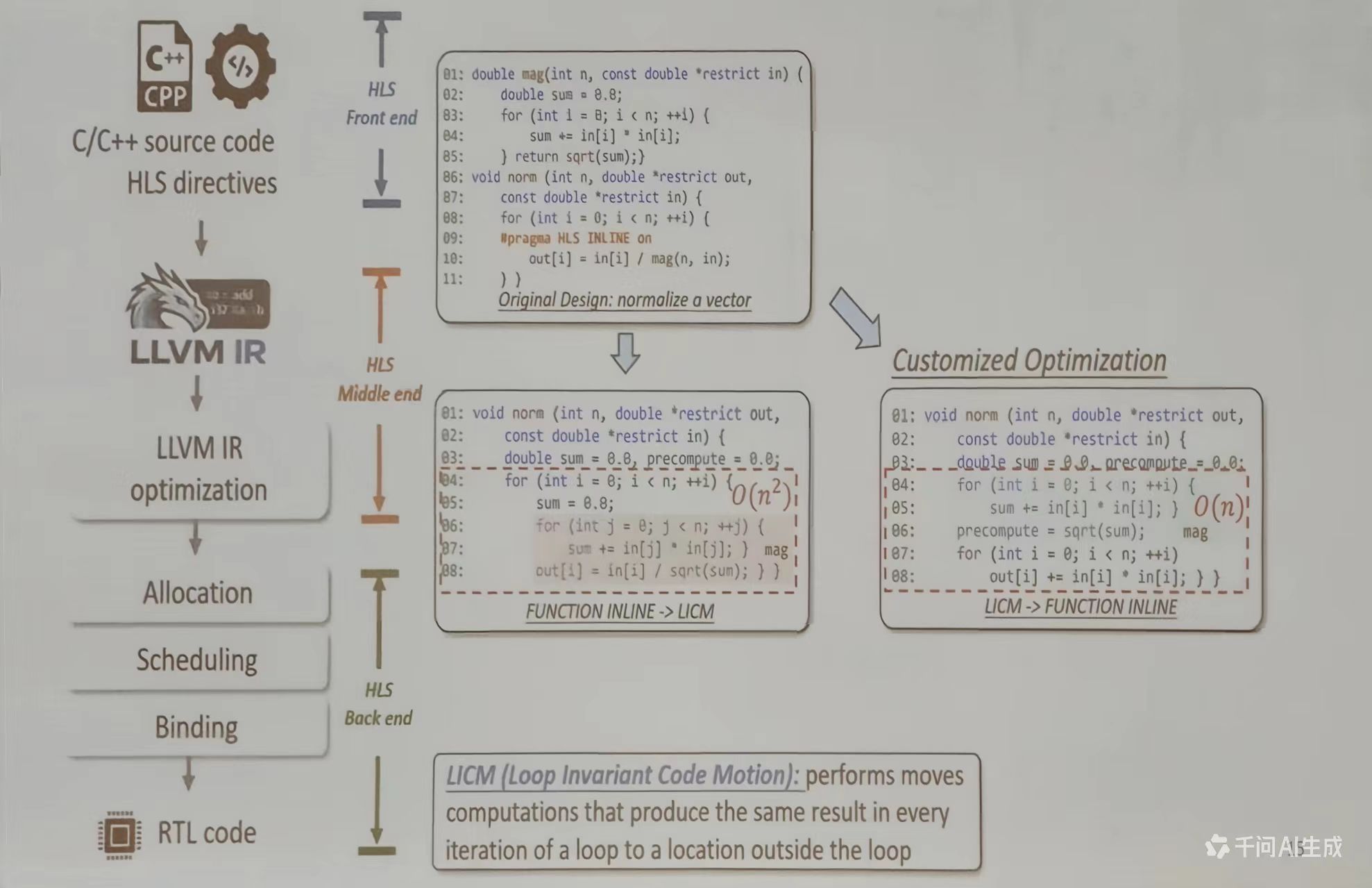
传统的 HLS 采用单一 IR (LLVM IR),缺乏清晰的循环结构,不利于高级优化。而新的 MLIR 支持多级 IR,可以保留结构信息,允许不同级别进行优化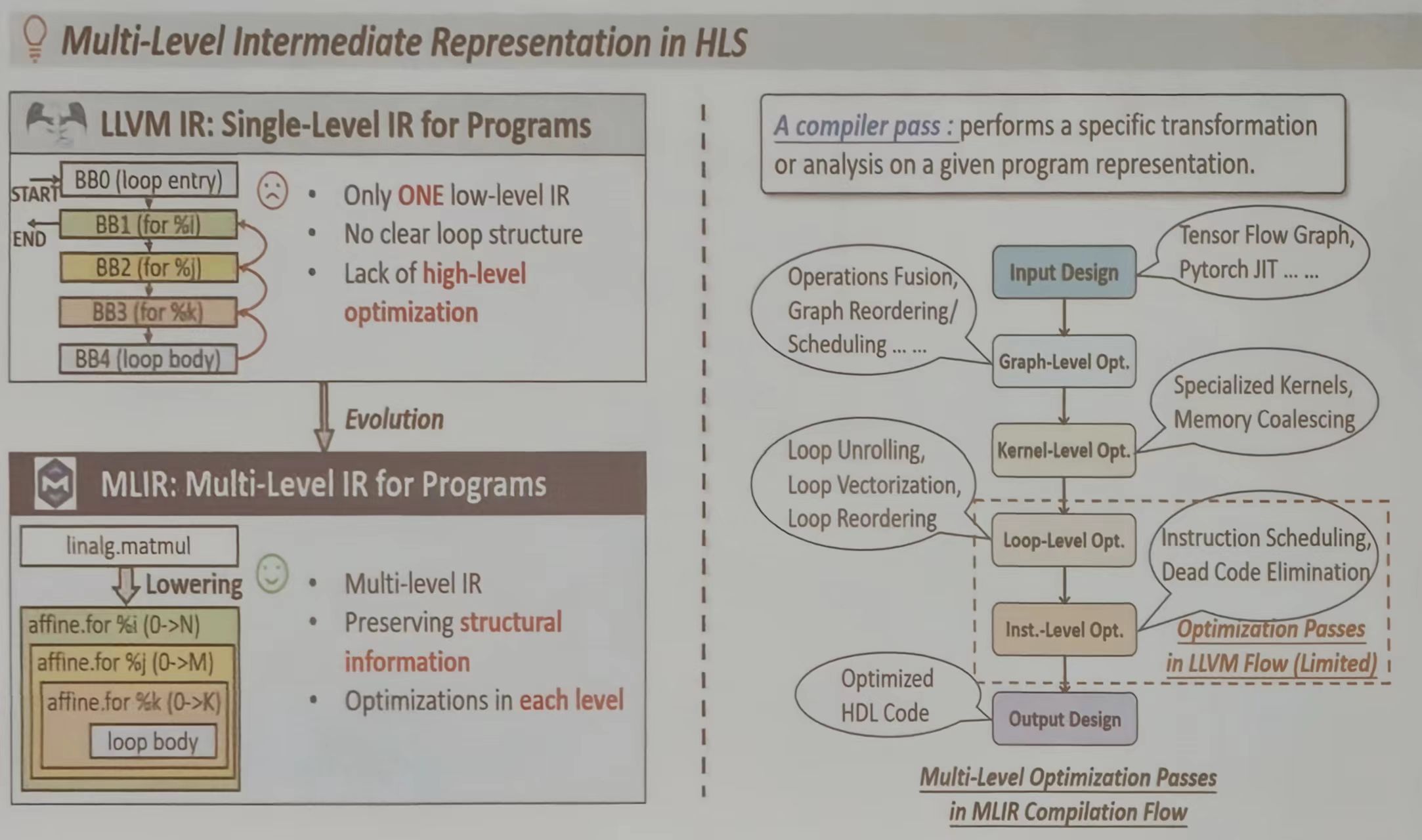
| 特性维度 | LLVM IR (传统单级表示) | MLIR (现代多级表示) |
|---|---|---|
| 核心哲学 | “万能”的单一、稳定、底层的编译器IR | 可扩展、多层次的编译器基础设施框架 |
| 抽象级别 | 主要集中在低层,接近机器指令 | 贯穿高级算法到低级硬件的多层抽象 |
| 结构信息保留 | 丢失大量高级语义(如循环、数据流结构) | 原生保留并显式表达高级结构(循环、任务、数据流) |
| 优化方式 | 主要在固定层级进行通用优化 | 渐进式降低抽象级别,在每一级进行领域特定优化 |
| 领域适配性 | 通用性强,但领域特定扩展困难 | 通过“方言”机制,原生支持领域特定扩展 |
通用编译到硬件设计的核心需求
传统 LLVM IR 在 CPU/软件编译上非常成功,但在面对 HLS 时却显露出根本性局限:
语义鸿沟:LLVM IR在设计上剥离了高级语义(如循环的并行性、数组的分块方式、流水线约束等),而这些恰恰是HLS进行高质量硬件综合所必须的信息。这导致许多本可在高层进行的优化(如循环变换、内存层级映射)无法实施或效果不佳。
优化僵化:其优化流程相对固定,难以灵活插入领域特定优化(如为 FPGA 定制循环流水线策略、为 AI 加速器定制数据流映射)。优化过早降低到低层,丧失了在高抽象级别探索不同实现策略的机会。
MLIR 的核心创新:方言与多层次 IR
MLIR 通过两大核心设计解决了上述问题:
方言机制:这是MLIR的基石。不同抽象级别的操作(如高层的
linalg.matmul表示矩阵乘法,中层的affine.for表示循环,低层的llvm.load表示访存)可以共存于同一模块中。这允许HLS工具定义自己的方言(如表示硬件流水线的pipeline操作或表示硬件资源的resource约束),将设计意图直接编码在IR中。渐进式 lowering:MLIR的编译流程不是一个“断崖式”的下降。如图所示,优化可以分层次、分阶段进行:
- 在图形级,可进行算法级任务划分和粗粒度流水。
- 在内核级,可进行内存布局优化和内核融合。
- 在循环级,可进行展开、流水线、数据流变换。
- 在指令级,最终生成目标 RTL 或 IP 核。每一级的优化都在最适合的抽象层级上进行,且信息可向下一级传递。
MLIR 的实践项目
- CIRCT项目:这是基于MLIR构建开源硬件编译工具链的核心项目。它提供了从高级语言(如Chisel、FIRRTL)到低级硬件描述(如Verilog)的一系列MLIR方言和转换通道,成为了连接算法与硬件的“编译器中间层”
- 厂商工具革新:主流FPGA厂商(如Xilinx/Xilinx Vitis)和EDA公司正在将MLIR集成到其下一代工具中。例如,通过定义专属方言,工具可以更智能地理解AI模型中的算子,并自动映射到最优的DSP阵列或存储架构上
- 与 DSE 结合:结合上一张幻灯片提到的设计空间探索(DSE),MLIR 因其结构化的 IR,使得自动化工具能更容易地分析和施加不同的优化策略(如尝试不同的循环展开因子或流水线启动间隔),并快速评估其效果,从而极大加速了优化决策过程
MLIR 带来的新机遇
算法-硬件解耦 (Algorithm-Hardware Decoupling)
传统 HLS 中,算法代码和硬件优化指令混在一起,MLIR 允许将算法和硬件优化分开,开发者只需专注于算法,硬件优化由编译器自动完成。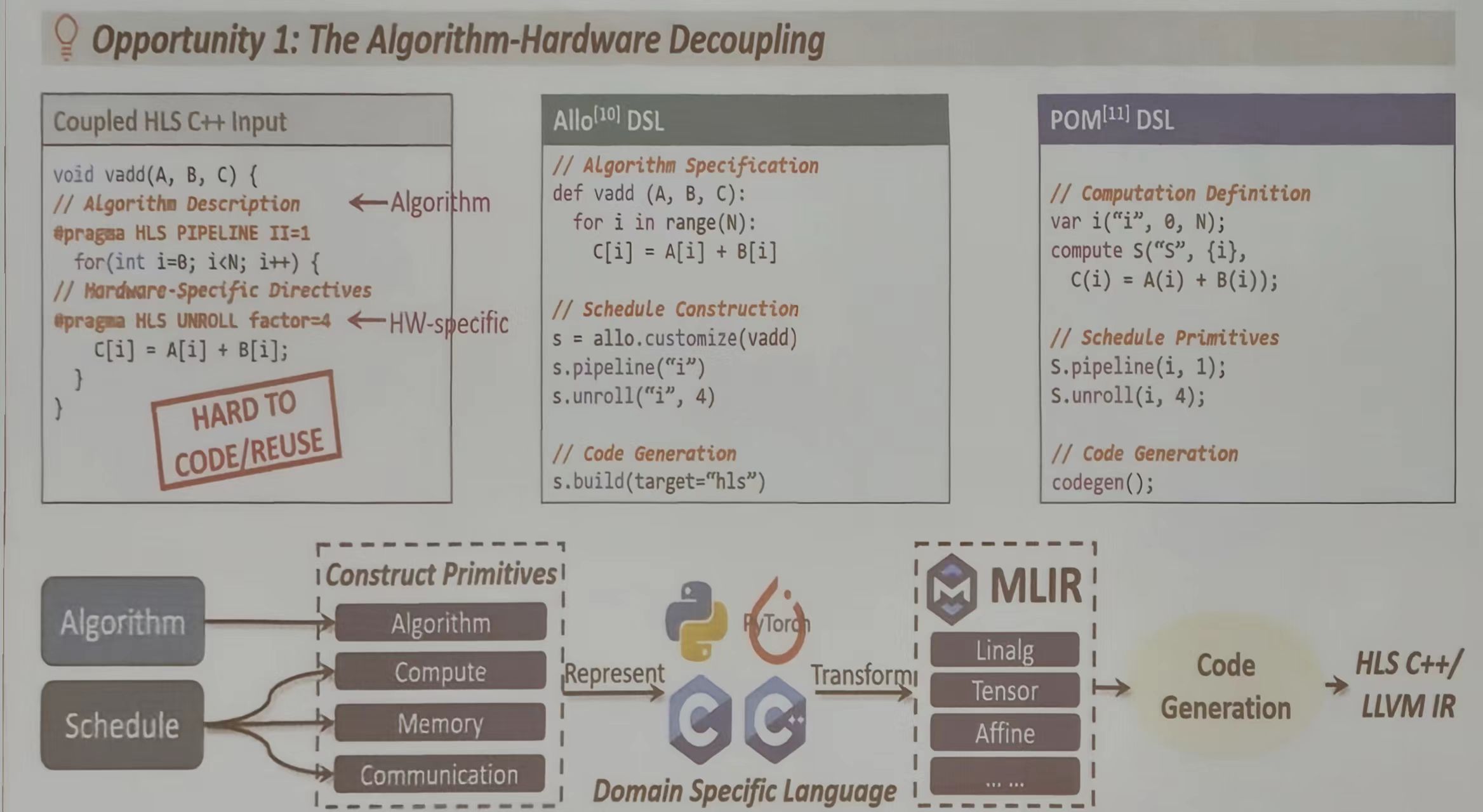
- 将算法描述和硬件特定指令分离
- 使用 DSL 描述算法,通过调度构造器指定硬件特性
异构 FPGA 的统一编译栈(Unified Compilation Stack)
现代 FPGA 包含多种计算单元(CPU、PL、AIE),传统 HLS 需要为每种设备单独优化,但是 MLIR 提供统一的编译接口,可以自动适配不同的计算单元。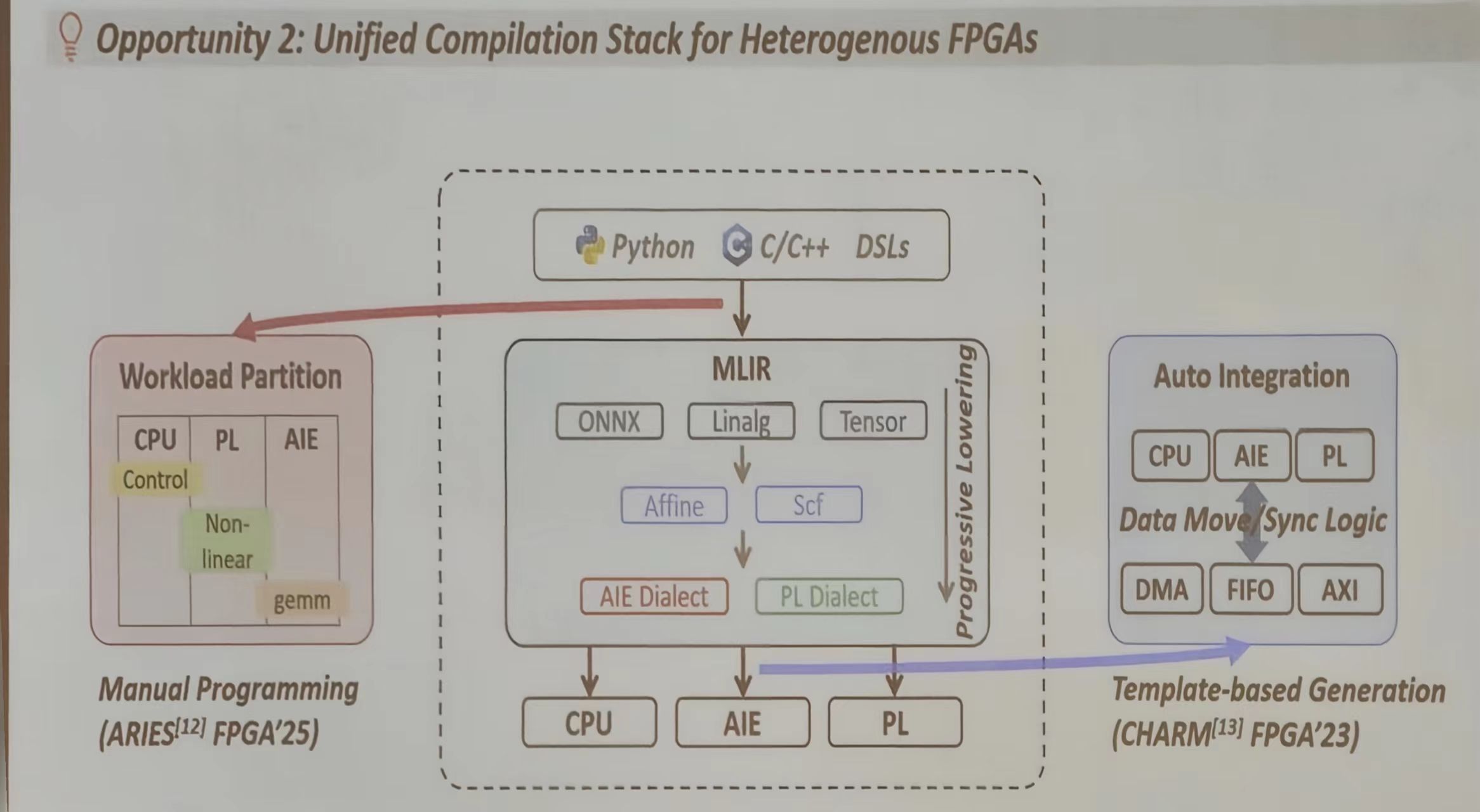
- 将 CPU、PL、AIE 等不同计算单元统一编译
动态调度与静态调度比较
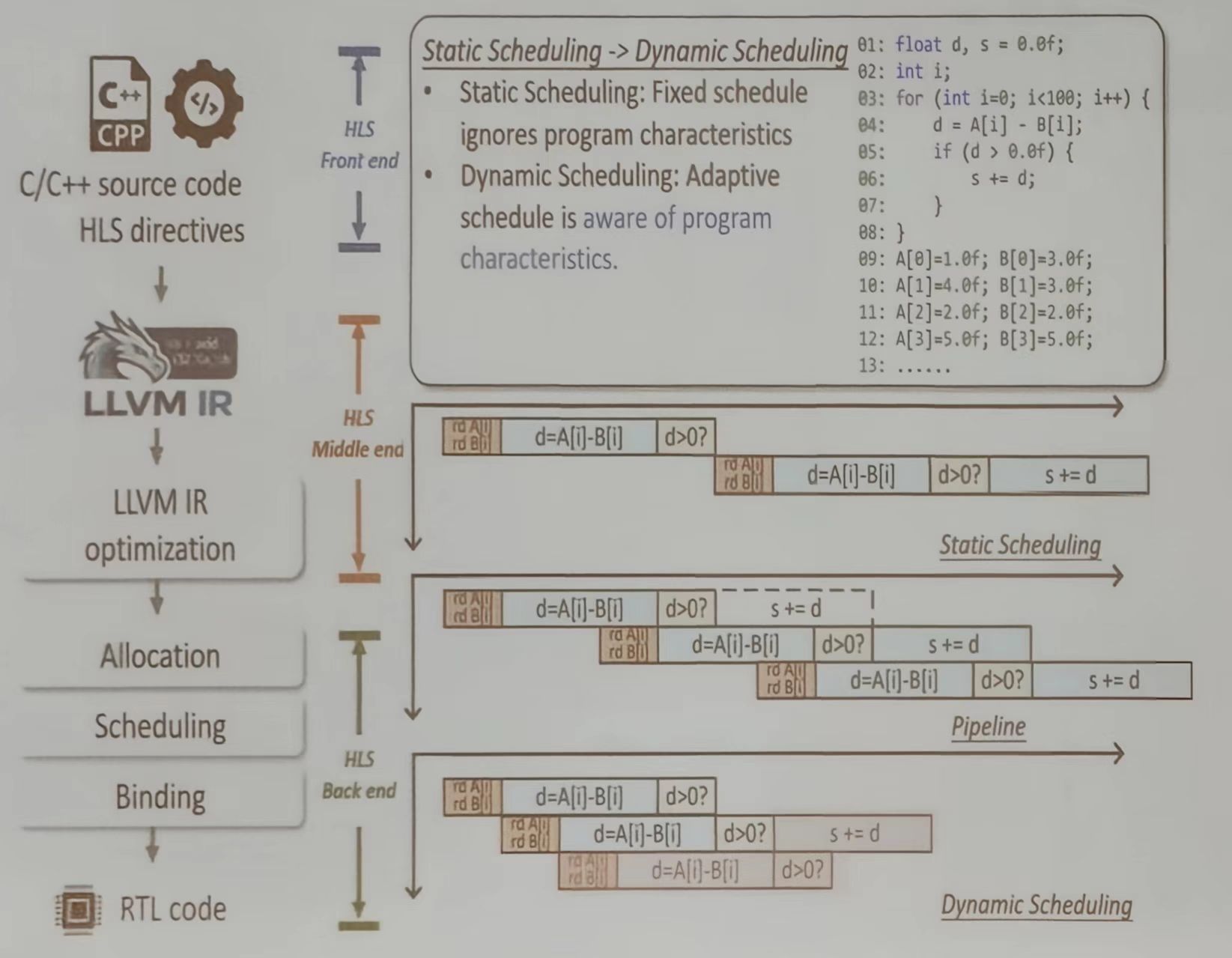
调度是 HLS 优化的关键环节——决定任务如何在硬件上执行。该图比较了两种调度方式:
- 静态调度:就像固定时间表,无论任务如何变化,都按固定顺序执行。传统 HLS 使用静态调度,虽然简单,但无法充分利用硬件并行性。
- 动态调度:Dynamatic 项目使用动态调度,能根据程序运行时的特性自适应调整,提取更多并行性,尤其适合处理”不规则循环”(如条件判断导致的执行路径变化)
数据显示,Dynamatic 可以将延迟减少3.5倍,但会增加2.11倍的资源消耗。对于某些应用,这种权衡是值得的,因为延迟减少带来的性能提升远超过资源增加。
动态调度方法实例
HLS 正从静态、确定性的编译时调度,转向动态、弹性、运行时管理的硬件生成。本质上是将现代 CPU 中乱序执行的智能与灵活性引入到定制硬件中,以应对日益复杂的计算需求。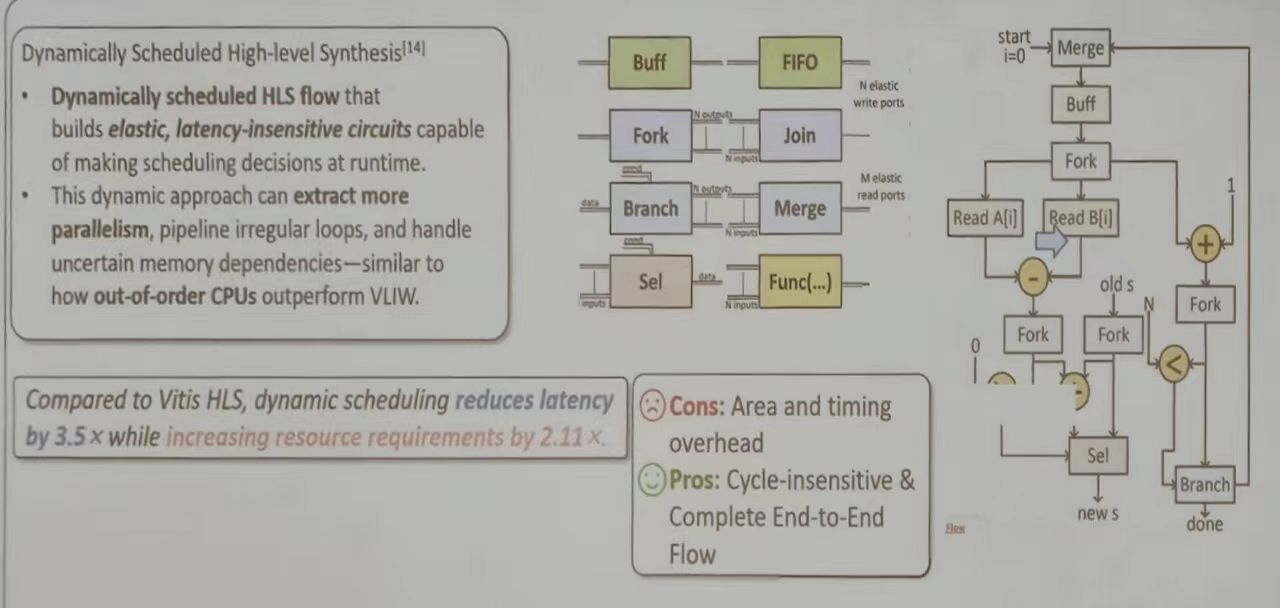
| 特性维度 | 传统静态调度 HLS (如 Vitis HLS) | 动态调度 HLS (弹性数据流架构) |
|---|---|---|
| 调度决策时机 | 编译时完全确定 | 运行时动态决定 |
| 电路特性 | 刚性、同步的时序电路 | 弹性、延迟不敏感的握手协议电路 |
| 并行性挖掘 | 依赖编译分析,限于规则、可预测的模式 | 可挖掘不规则、数据依赖的潜在并行 |
| 内存依赖处理 | 需静态分析,对不确定访问保守 | 可动态解析,支持非确定性内存访问 |
| 核心优势 | 硬件开销小,时序可控,工具链成熟 | 性能潜力高,对复杂控制流/变量延迟适应性强 |
| 主要代价 | 对不规则算法性能受限 | 面积开销大(增加控制逻辑),时序更难优化 |
刚性流水线到弹性数据流
传统 HLS 将 C 代码综合成类似同步数据流的硬件:每个操作在固定的时钟周期发生。这要求所有循环边界、内存延迟和分支路径都必须在编译时确定,极大限制了不规则算法(如图处理、稀疏计算)的优化能力
动态调度 HLS (也是弹性数据流 HLS)则采用不用范式:
- 延迟不敏感设计:模块间通过握手协议通信,而非全局时钟同步。一个模块只有在数据到达且下游就绪时才会执行。这自然消除了对固定组合逻辑延迟的担忧,使电路对工艺变化、电压频率缩放更鲁棒性
- 动态调度:图中展示的 Merge、Branch、Select 等组件时关键。例如:Merge 单元动态选择最先到达的数据流;Branch 单元根据运行时条件将数据分发到不同路径。实现数据驱动执行
核心组件
- 控制组件:
- Merge:动态仲裁多个输入通道,将数据汇入单一流。
- Branch:根据条件将数据流分发至不同路径。
- Select:从多个数据源中选择一个输出。
- 存储与同步组件:
- Buffer/FIFO:解耦生产者与消费者,是构建弹性流水线的核心,允许前后级以不同速率执行。
- Fork/Join:复制数据流并同步多条路径。
- 计算组件:
- Func(…):封装实际计算功能(如加法器、乘法器)的单元,其前后均有握手接口。

右侧的示例流程清晰展示了动态性:read A[i]和read B[i]两个操作可以异步、并行地访问内存,谁先完成谁就先行进入加法器。加法完成后,结果被动态送入分支单元进行判断,后续路径的选择完全由运行时数据决定。
- Func(…):封装实际计算功能(如加法器、乘法器)的单元,其前后均有握手接口。
HLS 优化
现在的 HLS 设计流程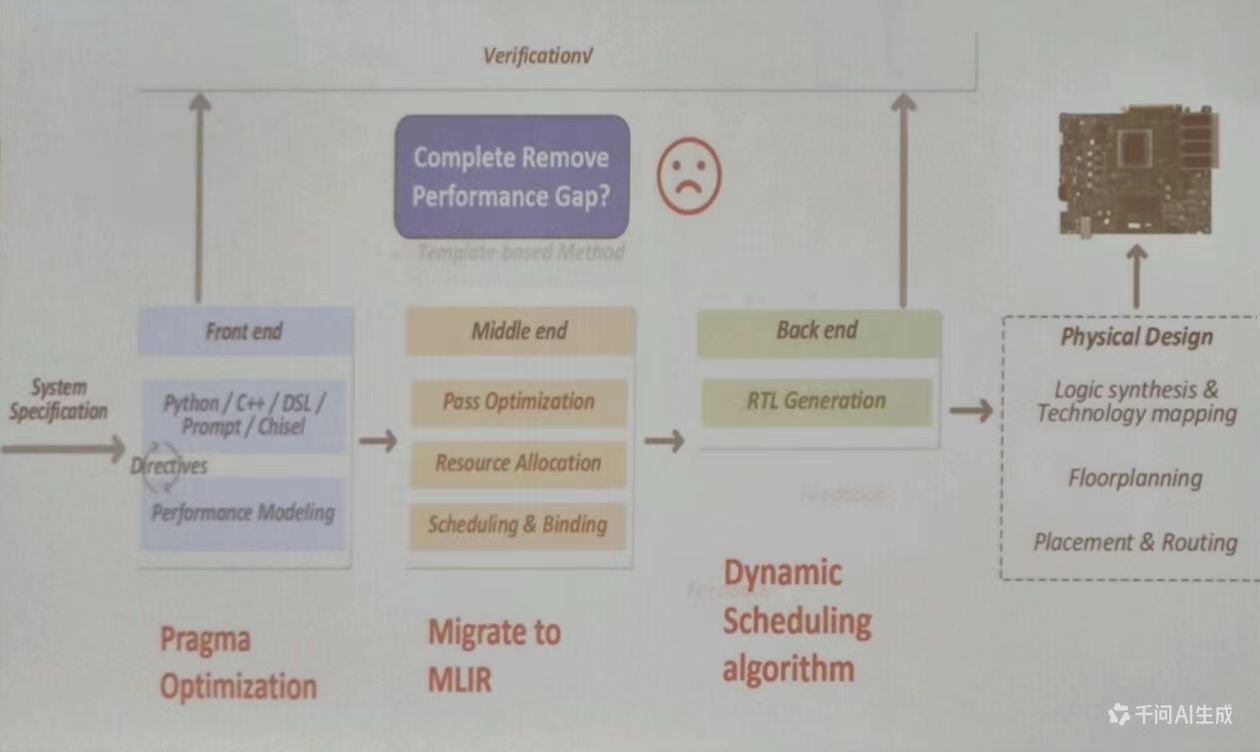
基于模板的设计流程
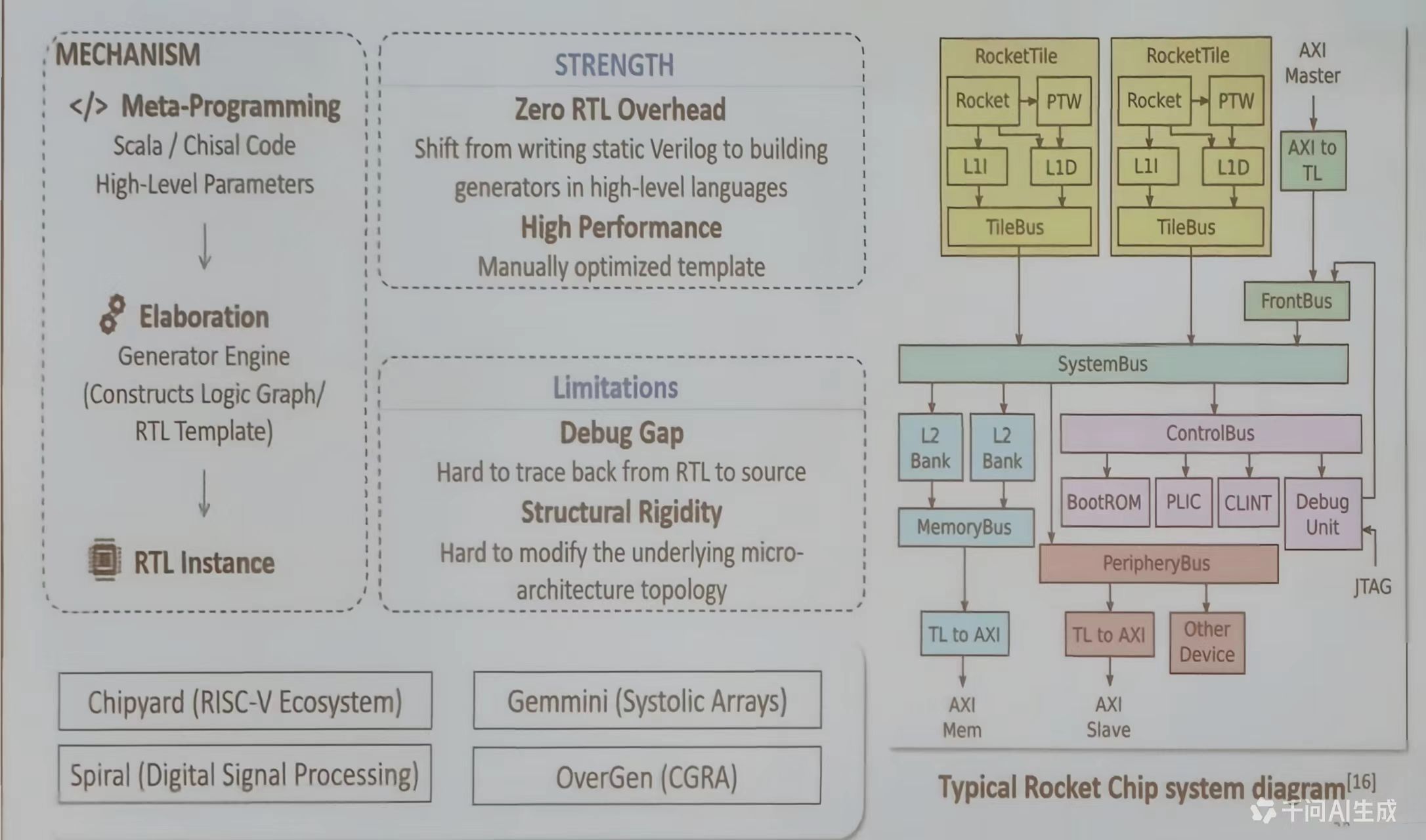
现在芯片设计逐渐从手写静态的、固定的 RTL 代码,转向编写能够动态生成定制化硬件的“生成器”程序。其核心在于,通过元编程(Meta-Programming) 将硬件设计提升到一个更高、更参数化的抽象层次,以应对复杂片上系统(SoC)的敏捷开发需求。
| 特性维度 | 传统 RTL 设计流程 | 基于模板/生成器的设计流程 |
|---|---|---|
| 设计载体 | 手写/编辑静态的Verilog/VHDL文件 | 编写高级语言(如Scala/Chisel)的生成器代码 |
| 核心产出 | 针对单一配置的、固定的网表/RTL | 一个可根据参数实例化无数种设计的生成器程序 |
| 复用与定制 | 通过复制粘贴、手动修改模块实现,易出错 | 通过参数化、继承、组合在架构层面实现类型安全的复用 |
| 设计探索 | 修改配置需重新编写代码,迭代慢 | 调整参数重新生成,快速进行设计空间探索 |
| 验证重点 | 验证特定实现的正确性 | 验证生成器逻辑的正确性,确保其所有合法输出均正确 |
| 核心优势 | 直观,对最终电路有完全控制,工具链成熟 | 生产力爆炸性提升,架构一致性极强,利于IP复用与系统集成 |
| 主要挑战 | 难以管理大规模复杂性,设计空间探索成本高 | 调试抽象鸿沟,生成代码的可读性,以及结构刚性 |
元编程与生成器引擎
以 Chisel 为例简述“元编程 → 细化 → RTL 实例”流程
- 元编程:设计师使用 Scala 等高级语言,编写的是描述硬件结构和行为的代码,而非最终的硬件描述本身。这些代码是参数化的,可以是一个处理器核的配置(如寄存器位数、缓存大小),也可以是一个互联网络的拓扑结构。
- 细化:当给定一组具体参数后,生成器引擎(如 Chisel 编译器)会执行这些 Scala 代码。执行过程并非计算数值,而是构建一个内部的硬件组件对象图,即“逻辑图”或“RTL 模板”。这个过程是类型安全的,并允许复杂的编译时逻辑。
- RTL 实例:最终,这个内部对象图被翻译成标准的 Verilog RTL 代码。这就是“零 RTL 开销”的含义:设计师从不直接编写或维护最终的 Verilog,所有 Verilog 都是无错的、由工具从高级描述生成的。
优势与局限
生成器封装了领域专家的最优设计知识
- 例如,一个矩阵乘法脉动阵列的生成器,内部已经固化了对数据流、内存层级和计算阵列的最优组织方式。用户通过调整阵列尺寸、数据位宽等参数,即可在保证架构最优的前提下,获得一个针对新需求的高性能实例。
调试复杂与结构刚性
- 当生成的 Verilog 出现问题时,设计师需要逆向追溯回生成它的 Scala 代码逻辑。这要求调试者同时理解硬件行为和复杂的软件生成逻辑。
- 生成器通常预设了固定的微架构模板。例如,一个缓存生成器可能允许你设置大小和相联度,但很难将其底层结构从组相联改为全相联。这要求生成器在灵活性与复杂性之间做出权衡,过度追求灵活性会使生成器代码本身变得难以维护。
典型案例:Rocket Chip 系统
整个复杂 SoC(包含 Rocket CPU 核、TileLink 总线、L2缓存、外设等)不是一个固定设计,而是一个由 Chisel 编写的、高度模块化的生成器框架
- 可组合性:
RocketTile、SystemBus、PeripheryBus等都是可配置、可替换的组件。用户可以通过混合匹配,快速生成从嵌入式微控制器到多核应用处理器的不同变体。 - 一致性接口:所有模块通过标准化的TileLink总线协议互联,这由生成器在架构层面保证,确保了系统集成的正确性。
- Chipyard 项目:正是构建在此基础上的完整SoC 设计、仿真与流片平台。
混合设计流程 (Hybird Design Flow)
现代异构计算系统(特别是 CPU+FPGA)设计复杂性的一个系统级解决方案。它并非是单一工具,而是一个集成框架,核心目标是将软件开发的敏捷性与硬件优化的极致性能相结合,实现从算法到可部署加速系统的全栈加速。

该流程将软件与硬件设计分开设计,并通过标准化接口进行协作
- 将高层次算法、控制流、数据准备与任务调度交给主机端 (CPU),使用 C/C++等高级语言开发,利用 CPU 的通用性和丰富的软件生态
- 将计算密集型、可并行的核心计算内核交给 FPGA 端,通过 HLS 或 RTL 生成实现极致加速,发挥 FPGA 的并行能力和能效优势
- 通过 OpenCL 异构编程框架和 Xilinx 运行时(XRT)作为接口,自动处理主机与 FPGA 之间的内存分配、数据迁移、内核启动与同步等复杂且易错的底层细节
GraFlex——一种基于 FPGA 的灵活散集式(scatter-gather)图处理框架,配备可扩展的互连网络。
- GraFlex 采用整体同步并行(Bulk-Synchronous Parallel, BSP)模型进行全局控制与同步,通过基于高层次综合(HLS)的设计流程,实现高性能图处理系统的快速部署。
- GraFlex 通过软硬件协同优化提升系统性能:它配置了紧凑的图数据格式、图划分策略以及内存通道分配机制,以支持可扩展设计
- 同时,采用资源高效的多级蝶形互连网络,实现片上数据通信并促进吞吐量匹配
- 为应对碎片化的内存访问请求,提出了合并式内存访问引擎,以提高带宽利用率
- 实验结果表明,与当前最先进的工作相比,GraFlex 在遍历吞吐量上平均提升高达 2.09 倍,同时显著降低了功耗和资源消耗。以广度优先搜索(BFS)为例的案例研究表明,借助所实现的散集机制及合理的实现选择,其平均算法吞吐量提升了6.58倍。
流程解析

- 设计入口:对应不同的设计风格和优化目标可采用
- 基于 Chisel 的元编程:用于生成高度定制化、架构复杂的控制与数据路径(如图中的 Scatter/Gather PE)。它适合构建底层基础设施和需要精细控制微架构的模块。
- 基于 C/C++的 HLS:用于快速将算法循环或函数转换为硬件加速器。它适合算法工程师快速进行原型验证和性能探索。
- 自动化内核封装与系统集成:生成的 RTL 内核会被自动封装成OpenCL 内核接口。这是关键一步,它为标准化的主机-设备交互提供了硬件抽象。随后,通过参数化实例化,该内核与来自基础设施 IP 库的必备组件(如总线接口 AXI、片上存储 BRAM/URAM、DMA 控制器等)集成,形成一个完整的系统块设计。
- 全栈编译与部署:主机端程序与 FPGA 比特流分别编译。最终,通过Xilinx 运行时(XRT) 和 Vitis 工具链实现自动集成,形成一个可部署的应用程序。主机程序通过 OpenCL API 调用 FPGA 加速内核,XRT 则透明地管理所有底层硬件操作。
LLM 驱动的设计流程
传统设计流程中,工程师必须将自己对系统的构思,通过严格遵循语法的硬件描述语言(如 Verilog)或工具命令(如 TCL)进行设计。这要求极高的专业性和精准度,任何语法或语义错误都可能导致设计失败。

LLM 驱动的流程彻底改变了这一动态:
- 输入:设计师用自然语言描述功能、性能目标或架构想法(如“设计一个支持AXI4总线的32位RISC-V CPU核,主频目标500MHz”)。
- 核心:LLM充当一位精通硬件设计、编程语言和工具链的“全能助理”,将模糊的意图转化为精确的可执行步骤。
- 输出:它生成的不是单一代码,而是一个可工作的工具链输入集合(HDL、Testbench、约束文件、TCL 脚本),从而直接启动一个标准化的实现流程。
构建可靠的 LLM 驱动
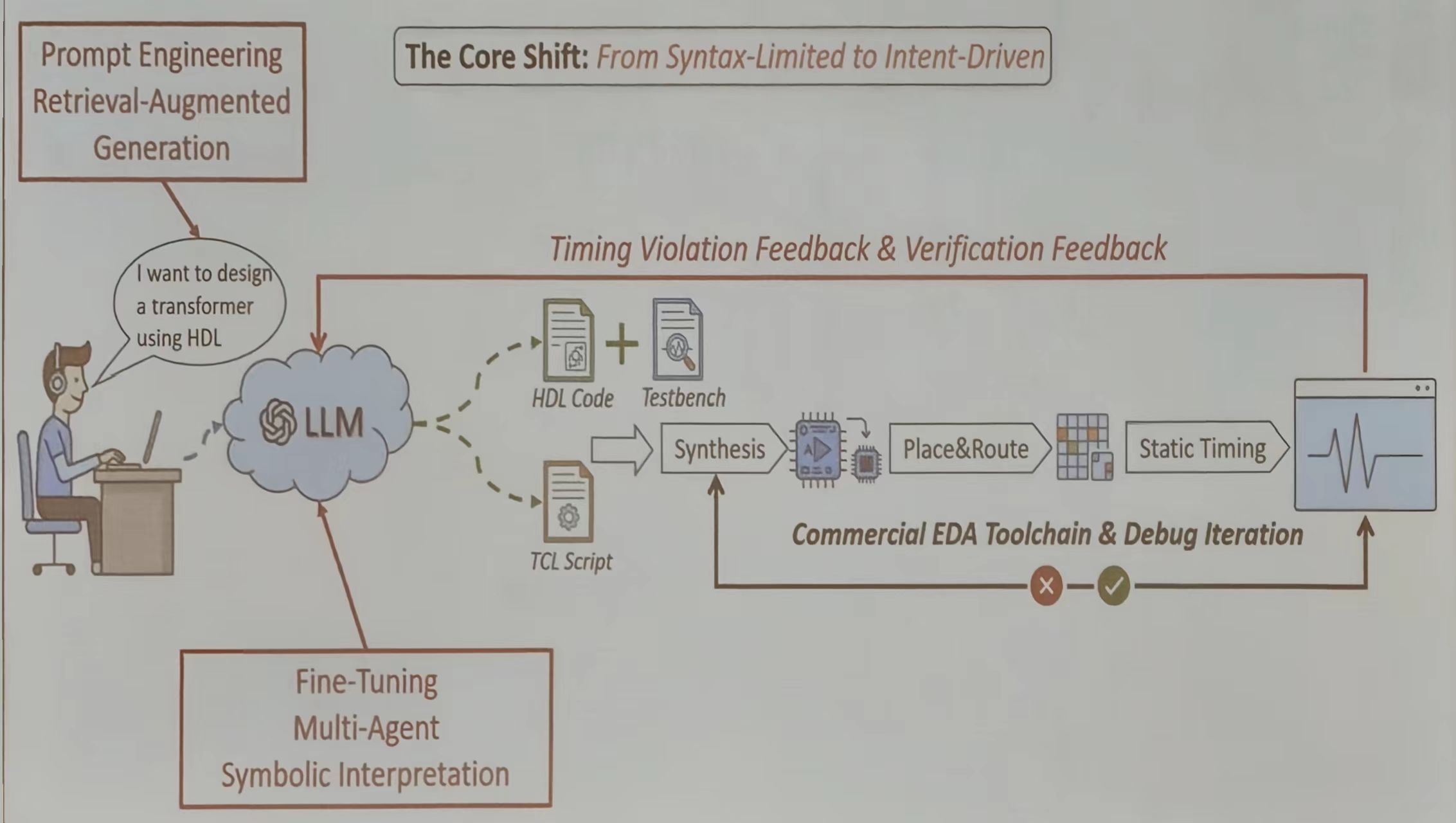
- 检索增强生成(RAG) 来解决 LLM“幻觉”和知识过时问题。它会从公司内部的设计库、IP 数据手册、最佳实践文档和过往错误案例库中实时检索相关信息,并作为上下文提供给 LLM。这确保了生成的代码符合内部规范、正确调用现有 IP,并规避已知陷阱。
- 反馈机制。当生成的代码经过综合、布局布线或仿真后,时序违规报告、功能覆盖率数据、功耗分析结果等都会被结构化地反馈给 LLM。LLM 可以据此自动分析问题根源(例如:“关键路径在某个多周期乘法器中,建议插入流水线寄存器”),并生成修正后的代码。这形成了一个自动化的调试迭代环,极大地压缩了手动调试的时间。
- 设计专用领域模型
- 微调 使用高质量的硬件设计代码和对话数据对基础 LLM 进行训练,使其深刻理解硬件设计模式、资源-时序权衡和 EDA 工具语义。
- 多智能体 系统可以扮演不同角色:一个“架构师”负责顶层模块划分,一个“验证工程师”负责编写测试用例,一个“后端专家”负责生成物理约束。它们相互协作与校验,共同完成复杂任务。
- 符号解释 则是对生成代码进行形式化分析,在仿真前就从数学逻辑上保证某些属性的正确性,提升初始代码质量。
实验结果
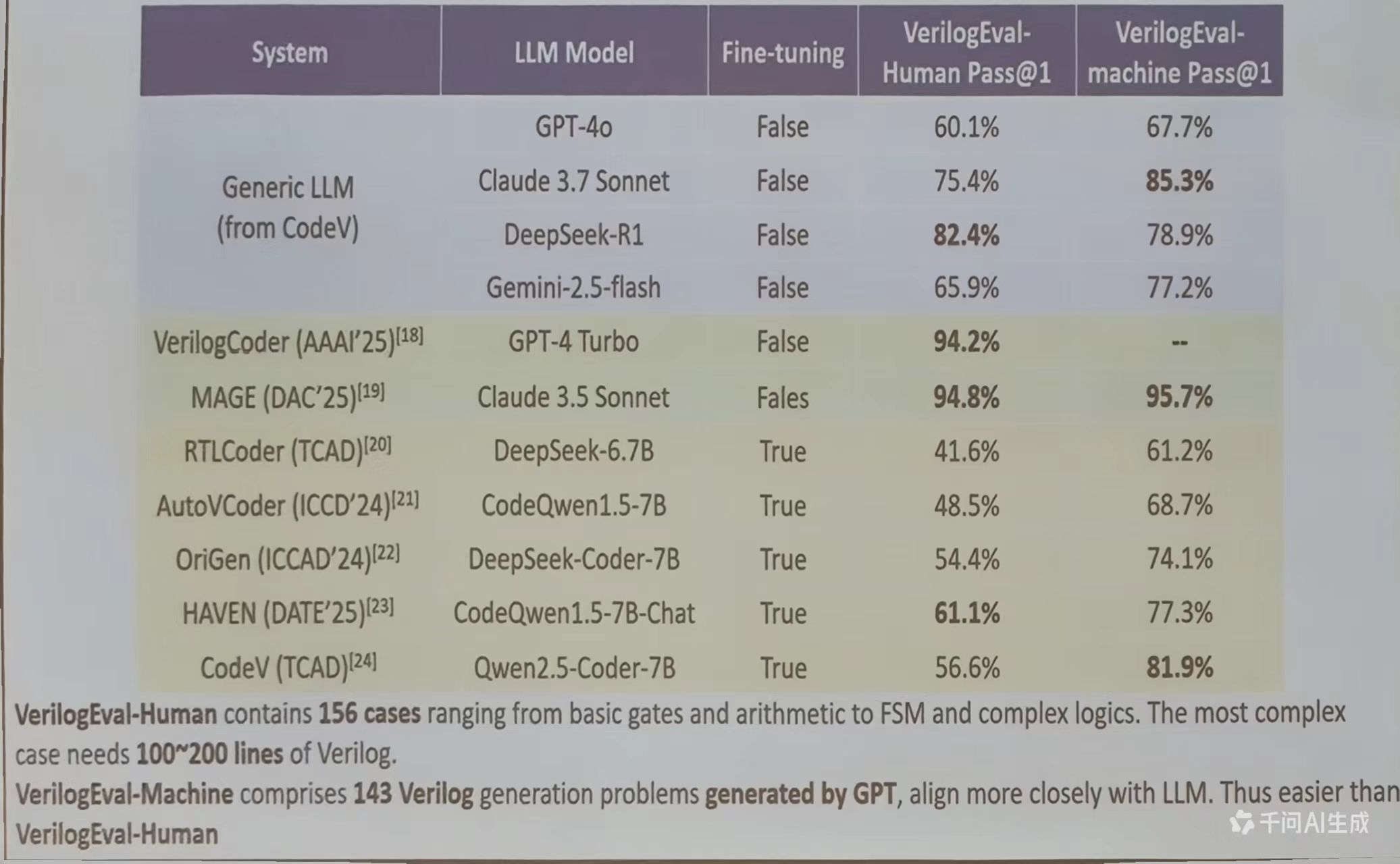
该图展示了 LLM 在 HDL(硬件描述语言)生成中的最新进展。VerilogEval 数据集是评估 LLM 生成 HDL 代码质量的基准,包含156个案例。
- GPT-4o:能正确生成60.1%的HDL代码(人类评估),67.7%的代码(机器评估)
- Claude 3.7 Sonnet:75.4%和85.3%
- MAGE(专为HDL设计的LLM):94.8%和95.7%
- HAVEN:61.1%和77.3%
这些数据表明,经过专门训练的 LLM(如 MAGE)能生成高质量的 HDL 代码,准确率接近96%。这意味着,未来开发人员可能只需要用自然语言描述硬件需求,LLM 就能自动生成符合要求的 HDL 代码,就像用自然语言写软件一样简单。
未来方向
如何融合编译器的可靠性、模板设计的性能以及 LLM 的灵活性->如何充分利用所有优势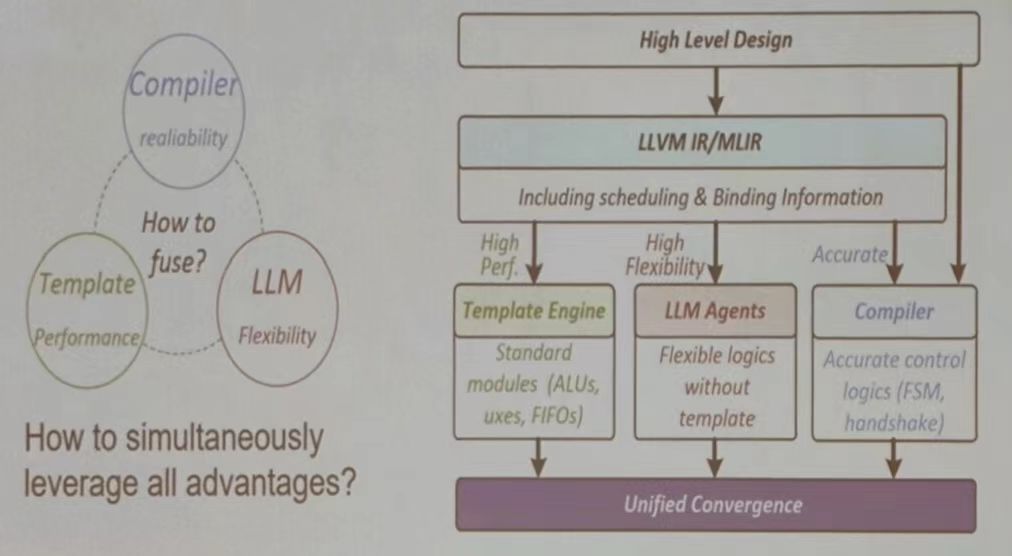
端到端的自主设计平台
SODA Synthesizer 是一个开源、模块化、端到端的硬件编译器框架,旨在自动化地从高级框架描述生成优化的硬件设计。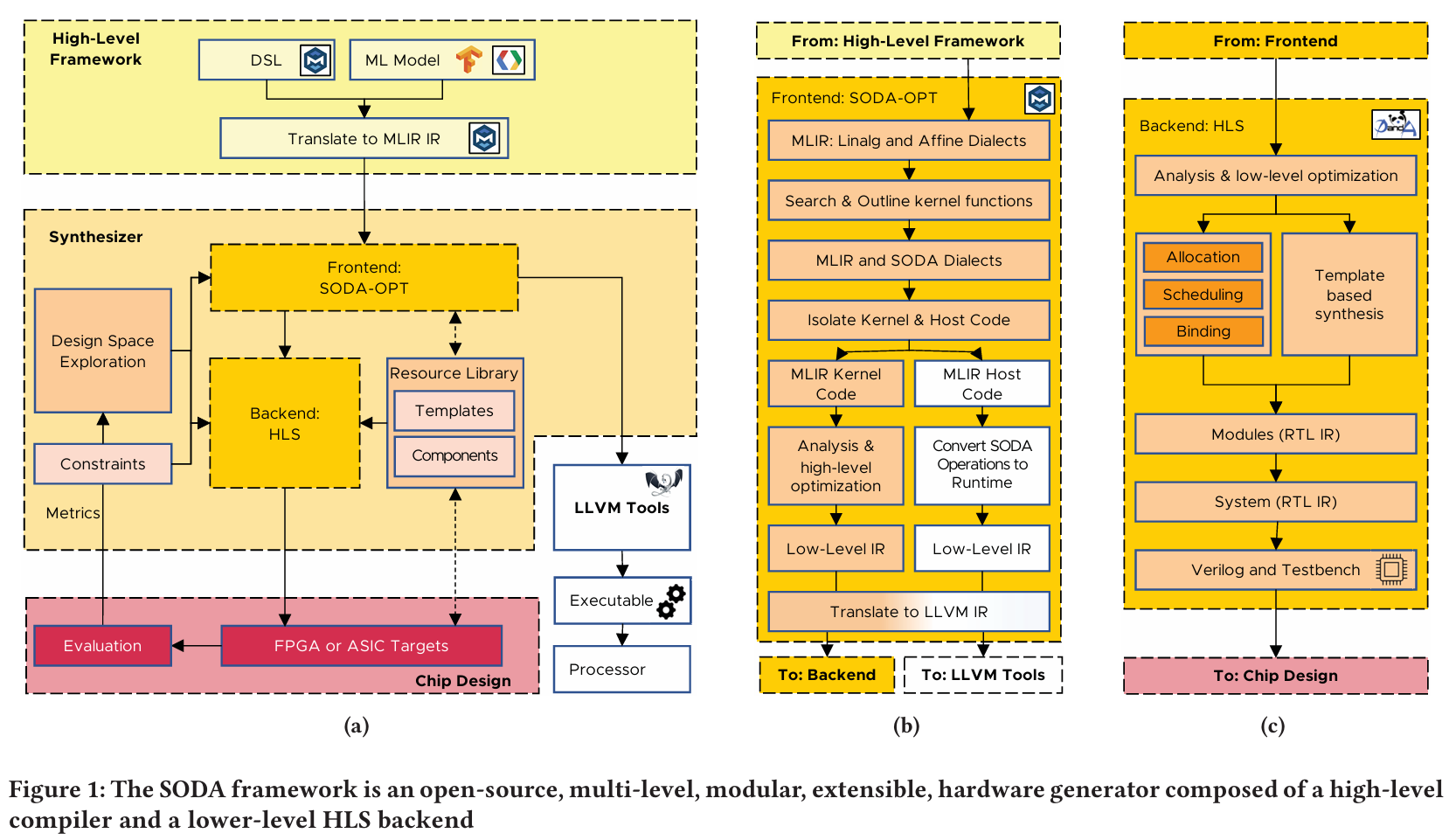
系统架构
SODA 采用两级编译架构,强调模块化与可扩展性
在前端设计了 SODA-OPT:
- 基于 MLIR 构建,自动分析 MLIR 代码,识别适合硬件加速的代码区域(内核)并将其提取。
- 利用 MLIR 方言(如 linalg, affine)的语义信息,进行架构无关的循环变换等高级优化,而无需手动代码标注。
- 通过自定义的
soda方言,自动将应用划分为主机程序(负责协调)和硬件加速器内核。
生成两类 LLVM IR——优化后的内核 IR(供后端 HLS 使用)和主机代码 IR(供 CPU 编译执行)
在后端采用 PandA-Bambu 开源的 HLS 工具
- 接收前端生成的 LLVM IR,执行低位宽分析、调度、绑定等标准 HLS 步骤,生成 Verilog/VHDL RTL 代码及测试平台。
前后端协同,支持通过不同的编译 pass 序列和参数进行自动化设计空间探索。SODA Synthesizer 通过其创新的MLIR-based 前端与强大的开源 HLS 后端相结合,提供了一个切实可行的端到端解决方案
跨层
背景与问题
- 多芯片FPGA的挑战: 为了容纳大规模加速器,多芯片(由多个SLR组成)FPGA被广泛使用。然而,跨越芯片边界的连线(SLL)会带来显著的延迟(约1ns),导致时序问题。
- 现有方法的局限:
- 传统的HLS指令优化通常只关注单一芯片的资源约束,忽略了多芯片间的跨芯片延迟和特定区域的资源限制。
- 全局布局规划(Floorplanning)算法(如基于 ILP 的方法)虽然能解决布局问题,但计算复杂度高,运行时间极长,难以与迭代式的指令搜索过程高效结合。
FADO 框架
作者提出了一种指令与布局规划协同优化(Co-optimization)的方法,将该问题建模为多维装箱问题(Bin-packing variants)。FADO 包含两个版本的迭代优化流程:
FADO 1.0:基于综合(Synthesis-based)的流
- 方法:
- QoR 库: 预先运行HLS工具生成函数级别的质量结果(QoR)库(包含延迟和资源消耗)。
- 贪婪搜索: 基于延迟瓶颈(Latency bottleneck)引导的指令搜索。
- 增量式布局合法化: 替代全局布局算法。使用在线“最差适应”(Worst-Fit)算法平衡资源,以及离线“最佳适应递减”(Best-Fit Decreasing)算法重排布局。
- 流水线插入: 在跨芯片边界的长连线上增量添加流水线寄存器。
- 缺点: 构建 QoR 库需要极长的预处理时间(数小时)
FADO 2.0:基于解析模型(Analytical Model)的流程(本文扩展重点)
- 改进点: 旨在消除耗时的QoR库生成过程,并探索更广阔的设计空间。
- 解析 QoR 模型: 基于COMBA模型开发并校准,支持任意数据类型和位宽。它能快速估算给定指令配置下的延迟和资源,无需运行HLS综合。
- 智能搜索策略: 重新设计了指令搜索算法,通过分析循环层级结构(单循环与多循环搜索),不仅收敛速度更快,还能平衡 BRAM、URAM 和 LUTRAM 的使用,从而提升频率
关键技术细节
- 问题建模: 将问题公式化为最小化总延迟,同时满足每个 SLR 的资源约束、跨芯片连接约束(SLL 数量)以及特定模块(如通过 RAM 连接的模块)的分组约束。
- 增量布局规划(Incremental Floorplanning): 这是FADO的核心。当指令改变导致模块资源变化时,FADO不进行全局重排,而是通过在线和离线算法微调模块位置,极大地减少了搜索时间。
- Look-ahead/Look-back 机制: 为了应对非单调的设计空间(即资源增加不一定带来延迟减少),FADO 1.0 引入了向前/向后搜索采样策略;FADO 2.0 则通过改进的搜索顺序自然地解决了这一问题。
实验结果
在 AMD Alveo U250 FPGA 上,使用混合了数据流(Dataflow)和非数据流内核的大规模基准测试进行了评估:
- 与全局布局规划相比:
- 速度: FADO 1.0 的搜索时间缩短了 693倍到4925倍。
- 性能: 设计性能(以执行时间衡量)提升了 1.16倍到8.78倍。
- FADO 2.0 vs. FADO 1.0:
- FADO 2.0 通过解析模型消除了预处理时间。
- 得益于更广阔的搜索空间和存储资源平衡策略,FADO 2.0 优化后的设计性能比 FADO 1.0 平均进一步提升了 1.40倍(排除一个极端特例)。
- FADO 2.0 相比基于解析模型的全局布局规划基线,性能平均提升了 2.66倍。
参考资料
*PPT 及其图示来自 FPT 2025 讲座——简化 FPGA 开发:敏捷设计流程带来的挑战和机遇(张薇教授)