
(FPT2025)超摩尔与深度学习时代的的空间架构——Vaughn Betz 教授(多伦多大学& Cerebras Systems)
背景介绍
以电动汽车 Chevy Bolt (6 kw) 与 Nvidia Drive AGX Pegasus (750 W) 为例,说明在自动驾驶等安全关键场景中,低推理延迟至关重要。
- 评价指标“性能/功耗/成本”,其中功耗约占总成本的 30%
FPGA 具有的可定制化与操作数精简的特点,通过重构实现网络所需的精确硬件,无需指令流,直接进行必要计算。其可编程路由与逻辑允许数据直连,并支持最小位宽操作,从而大幅降低能耗。
空间计算在数据局部性方面的优势
下图展示从片外 HBM2 到 SRAM (416kB、60kB、16kB 锁存阵列)数据流动,体现了不同存储层级的带宽与能耗差异。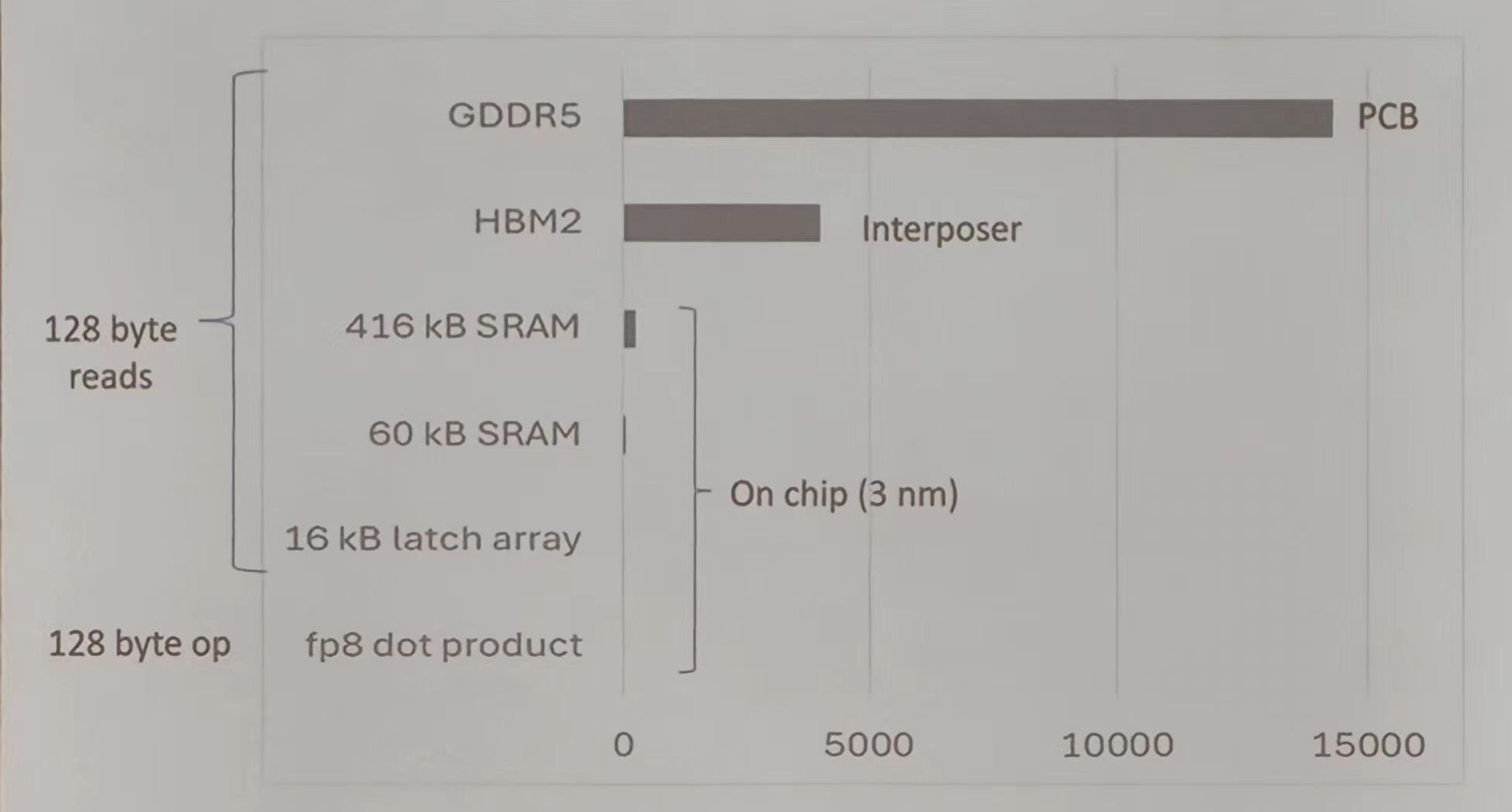
FPGA 在空间计算的优势:
- 可通过可编程逻辑与路由灵活存储,将数据贴近计算单元,显著减少数据搬运能耗。但是随着网络规模增大,依赖片外存储会削弱这一优势。
- 具备极高片上带宽 (~Pb/s,可划分为上万个独立存储块,支持按需定制存储大小与位置,并能与逻辑结合实现稀疏计算等优化。但超大规模网络仍需片外存储。
- 支持可编程串行 I/O(如 PCIe)、存储接口 (如 DDR)以及嵌入式低延迟定制 I/O,使其能够集成预处理、特征提取与深度学习推理,形成完整低延迟系统。
但可编程逻辑单元与路由比专用电路面积更大、速度更慢。因此,提出研究方向:是否可通过硬化关键功能(如 DSP 块)或改进软硬件结构,提升 FPGA 在深度学习中的效率
设计前端
HPIPE
HPIPE 数据流架构,其专为高效 CNN 推理设计,体现了如何通过空间映射提升计算效率。传统时序映射使用通过处理单元逐层处理 (PE),效率较低,如下图所示。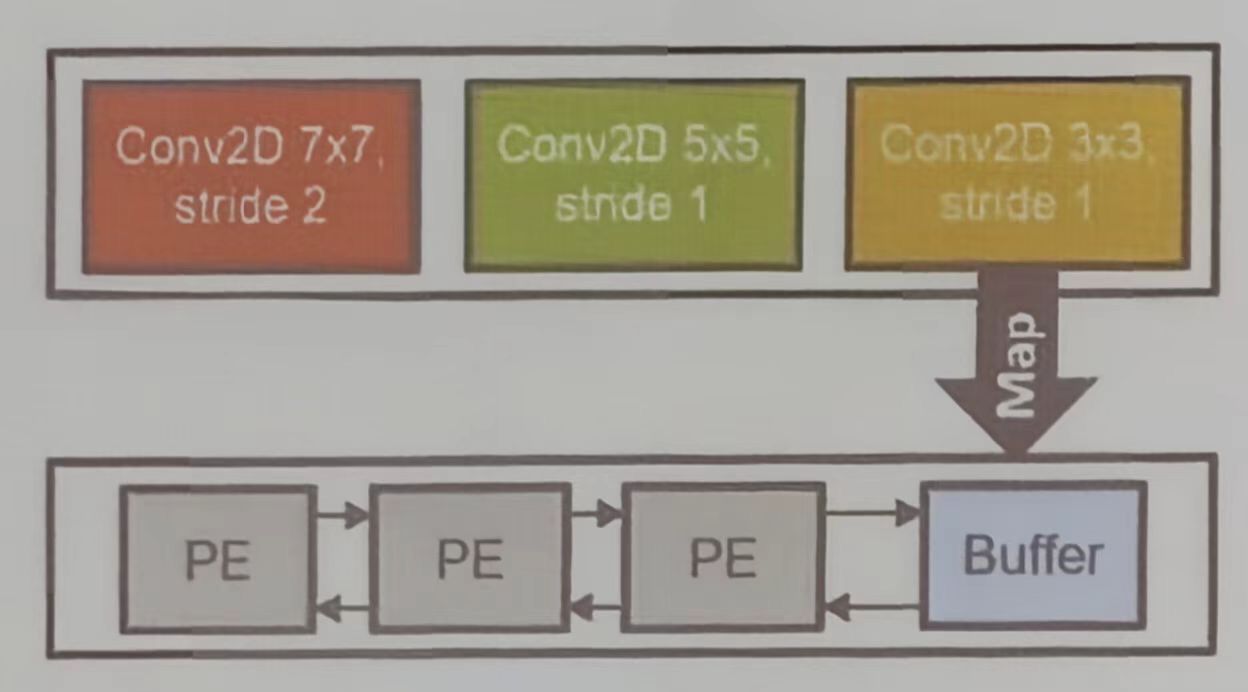
HPIPE 则为每层定制硬件单元,层间通过延迟不敏感接口连接,充分利用流水线并行提升效率与吞吐量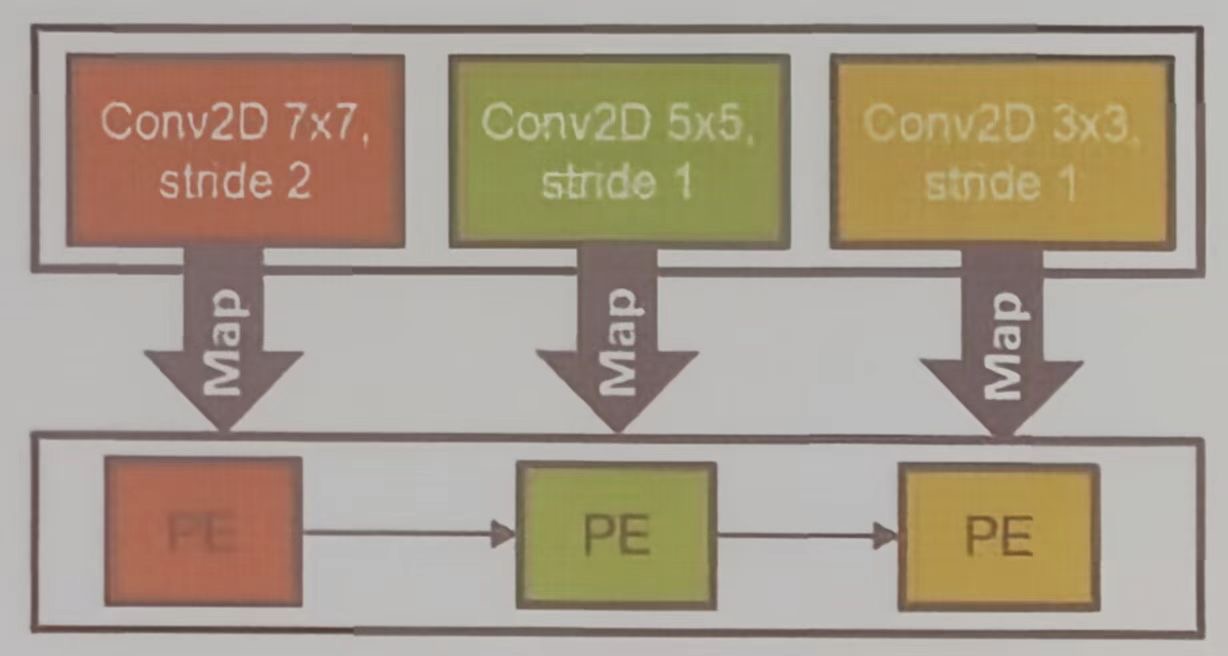
下图可以看出专用硬件与本地数据移动的优势;无指令译码开销、数据局部性高、但需为不同网络设计不同硬件,因此需要领域专用编译器的支持。
图来自,M.Hall et al,“From TensorFlow Graphs to LUTs and Wires: Automated Sparse and Physically Aware CNN Hardware Generation”, FPT 2020.
该图展示了 HPIPE 自动生成 CNN 硬件的流程:从 TensorFlow 模型出发,经过图优化、资源分配、RTL 生成、布局感知流水线与存储映射,最终生成 FPGA bitstream。该方法通过层融合、流水线平衡与本地化通信优化,提升整体效率。
HPIPE 通过将超大规模 CNN 的权重选择性卸载的策略,将部分权重移至片外 HBM, 释放片上存储,使更大网络能在单 FPGA 上运行。虽然会损失一定性能,但仍优于先前方案,体现了成本与性能的权衡。
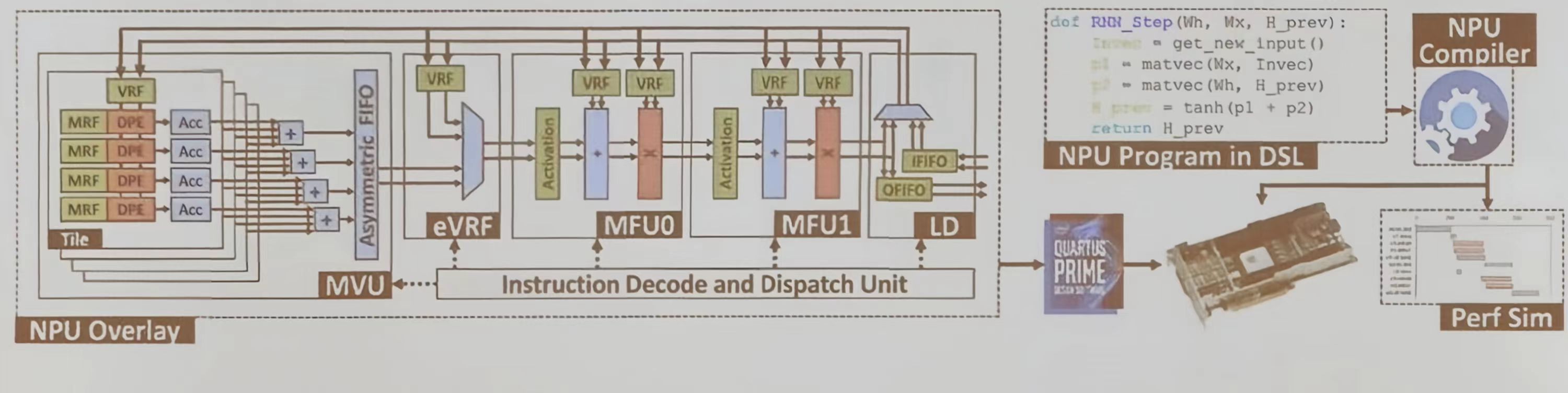
Overlay NPU
传统流程需要应用专家编写 RTL, 设计时间周期长;而 Overlay 方案则由硬件专家定义 ISA 与工具链,应用专家通过软件编程快速部署,实现“软件可编程的推理加速”。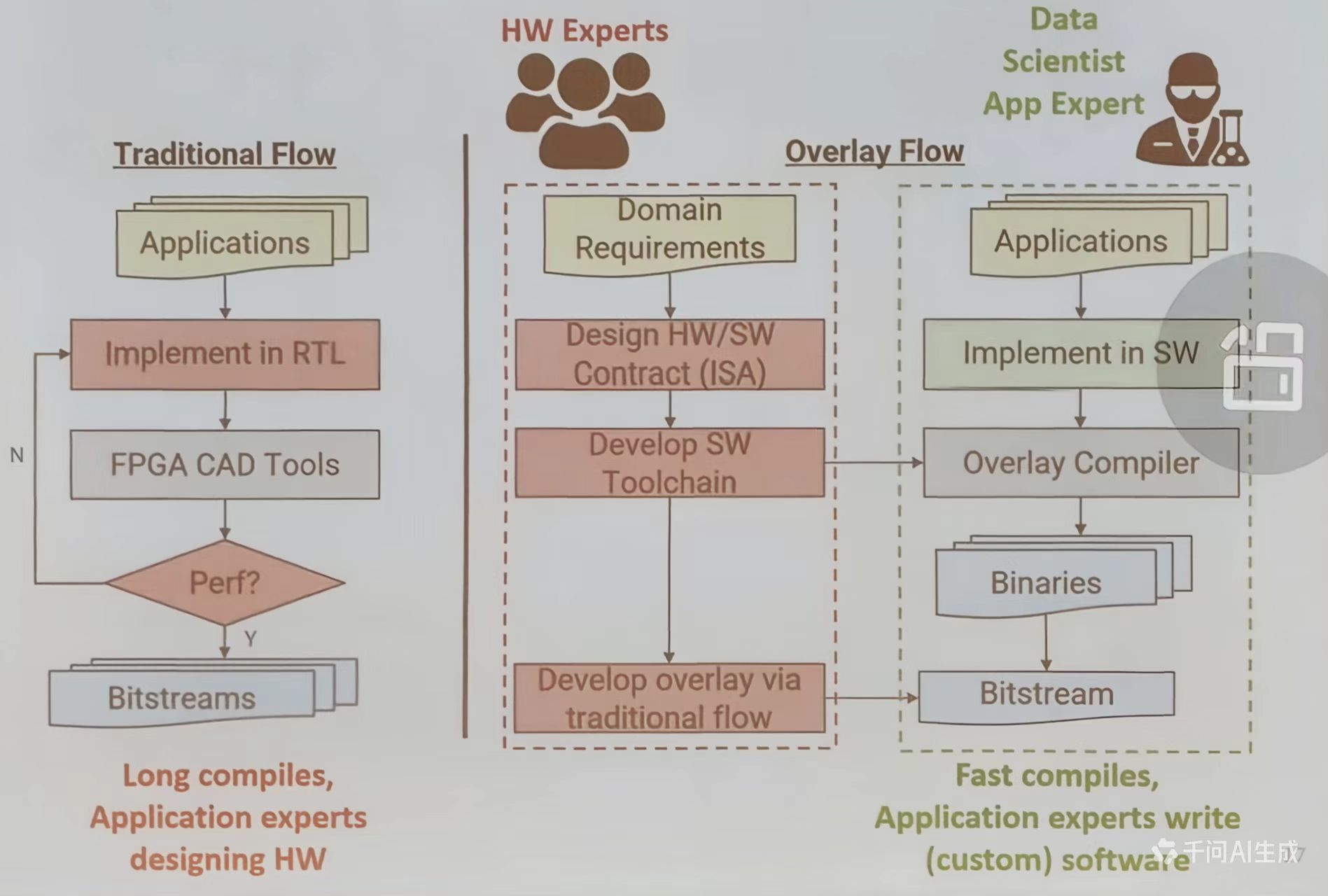
NPU 主要针对多层感知机 (MLPs)、循环神经网络 (RNNs)、门控循环单元 (GRUs)、长短期记忆网络 (LSTMs)和图神经网络 (GNNs)等神经网络模型
NPU 架构特点:
- 超长指令字 (VLIW)软处理器:采用 5 个粗粒度阶段的 VLIW 架构,单条指令可执行 45000 次操作
- Amortize control:优化指令执行效率
- 定制内存子系统:利用片上内存带宽、提升数据处理速度
- 数据级联:数据从一个阶段级联到下一个阶段,实现空间局部性优化
NPU 的组成结构:
- 包括多个功能单元 (MVU、eVRF、MFU 0、MFU 1) 及其连接方式
- 指令解码与分发单元:负责指令的解码和分发,确保各功能单元协同工作
NPU的开发流程:
- 使用领域特定语言 DSL 编写 NPU 程序
- 将 DSL 编写的程序编译为可在 NPU 上运行的代码
- 通过性能仿真工具评估 NPU 程序的执行效果
图片引用了A. Boutros等人在FPT 2020会议上发表的研究《Beyond Peak Performance: Comparing the Real Performance of AI-Optimized FPGAs and GPUs》,该研究比较了AI优化的FPGA和GPU的实际性能。
支持算术的逻辑结构优化

- 通过改进 LUT 与加法器结构,可在面积增加不足 4%的情况下,提升 MAC 密度 25%~50%

虽然可编程逻辑相比 ASIC 在面积上与速度上存在劣势,但针对常用计算模式(如 FIR 滤波器)硬化 DSP 块,仍能在面积与速度间取得较好平衡,需要综合考虑路由与使用范围。
Inter Stratix 10 NX 张量块的设计演变
传统 DSP 块支持 2 个 int 18 乘法器,而张量块则集成 30 个 int 8 乘法器,通过组织为 3 个 dot-10 引擎、输入广播与乒乓复用链,在相近面积内实现 15 倍 int 8 算力提升,适用于密集型低精度矩阵计算
输入输出配置:
- 480 输入/480 输出:初始配置下,Tensor Block int 8 支持 480 输入和 480 个输出

- 480 输入/72 输出:通过限制输出,将乘法器排列为 3 个 dot-10 引擎累加器,实现 480 输入和 72 输出
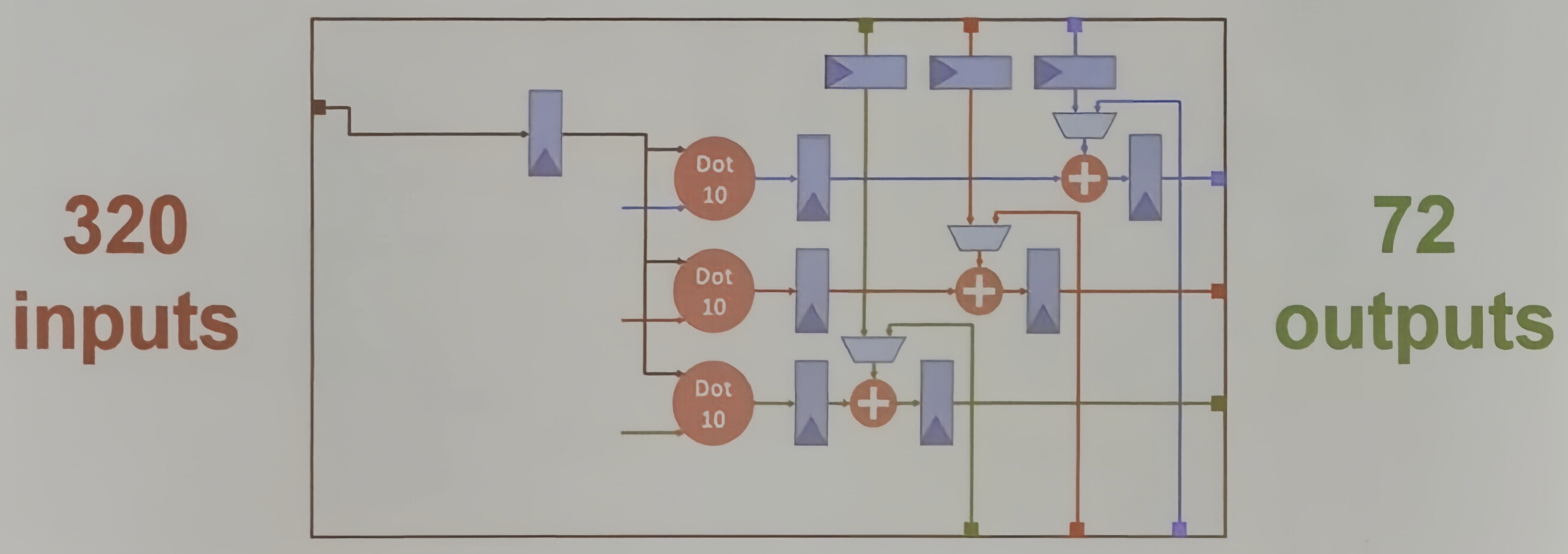
- 320 输入/72 输出:进一步限制输入,通过广播一组到所有 dot-10 引擎,实现 320 个输入和 72 输出
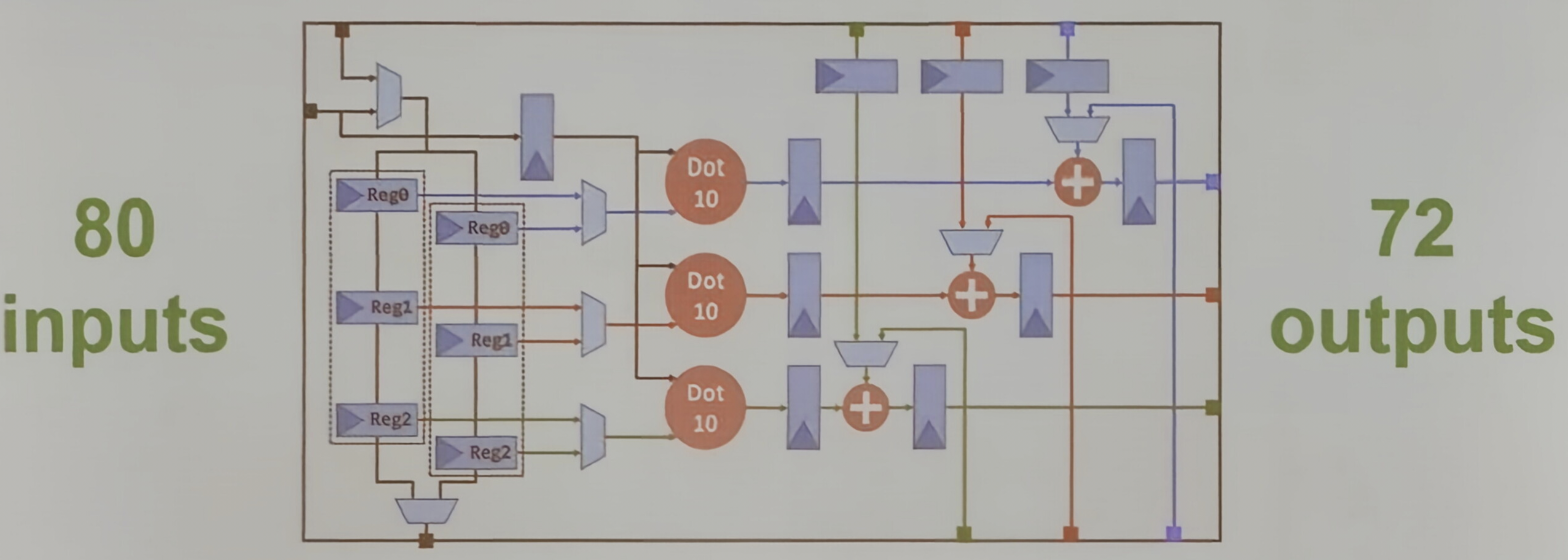
- 80 输入/72 输出:最终配置下,通过乒乓重用链从上一个块加载数据,实现 80 个输入和 72 个输出。
在于 DSP 块相似的面积内。Tensor Block int 8 能够实现 15 倍峰值的 int 8 TOPS(每秒万亿次操作)
设计后端
FPGA 架构研究的挑战核心内容:FPGA 架构创新需要解决两大挑战
- 缺乏代表性应用设计
- 底层电路(面积/功耗/延迟)的精确描述
但是新架构需应用验证,但是应用开发又依赖成熟架构。
例如,AI 加速器设计需特定算子支持,但现有基准测试集(如 MiBench)难以覆盖新兴场景。同时,7 nm 工艺下,互联延迟占比超 60%,传统 SPICE 仿真耗时过长,需要数据驱动的快速评估模型
VTR (veruling-to-Routing)开源框架的出现,通过参数化架构描述文件 (如. Vtr 格式)实现“一次建模,多次验证”的敏捷开发范式
VTR 开源工具链
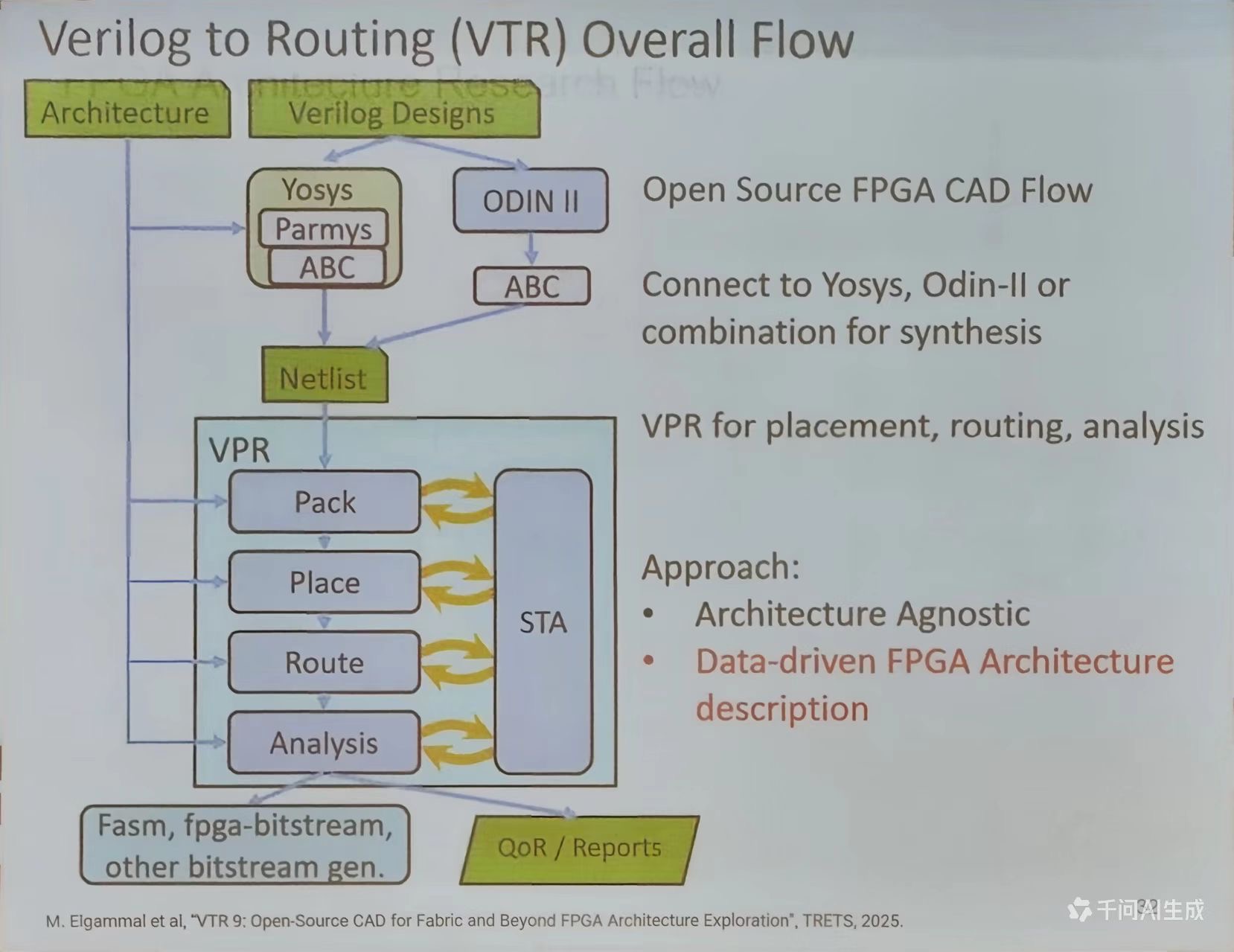
VTR 9 (2025) 通过模块化设计实现架构无关性
- 前端兼容:Yosys 处理复杂 RTL, Odin-II 专攻简单逻辑,混合模式提升 40%综合效率
- 后端创新:VPR 的“Pack-Place-Route”流程引入机器学习驱动的拥塞预测器,布线失败率降低 28%
- 数据驱动:架构描述文件 (Arch XML)支持自定义 LUT 配置 (如 6-LUT+4-LUT 混合)、DSP 精度 fp 32/fp 16)等参数,为 FPGA 定制化提供基础
架构灵活性-Blocks, Block Arrangement, Routing
Architecture Flexibility: Blocks
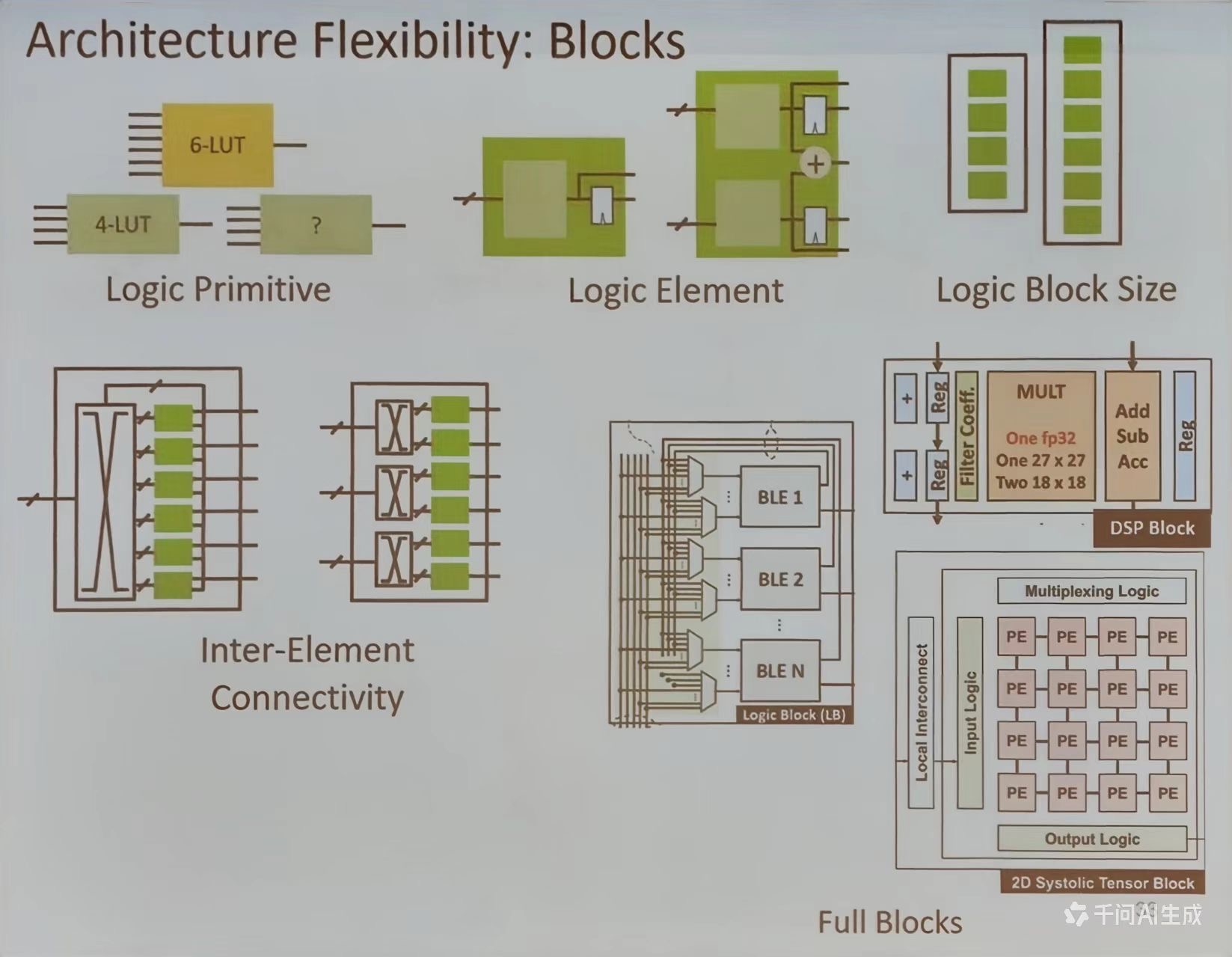
- 逻辑原语(Logic Primitive): 最基础的构建单元,如 6-LUT 和 4-LUT, 用于实现基本的逻辑功能
- 逻辑单元 (Logic Element): 由多个逻辑原语组合而成,具备更复杂的逻辑处理能力
- 逻辑块大小 (Logic Block Size):不同规模的逻辑块,体现模块的可扩展性
- 模块间连接性 (Inter-Element-Connectivity):不同逻辑单元之间的连接方式
- 完整模块 (Full Blocks):包括 DSP 块和 2 D 系统张量块等专用功能模块,这些模块集成了特定的计算功能,如乘法、加法等
只要善用这些元素就可以设计出各种各样的电路,可扩展性极高
Architecture Flexibility: Block Arrangement
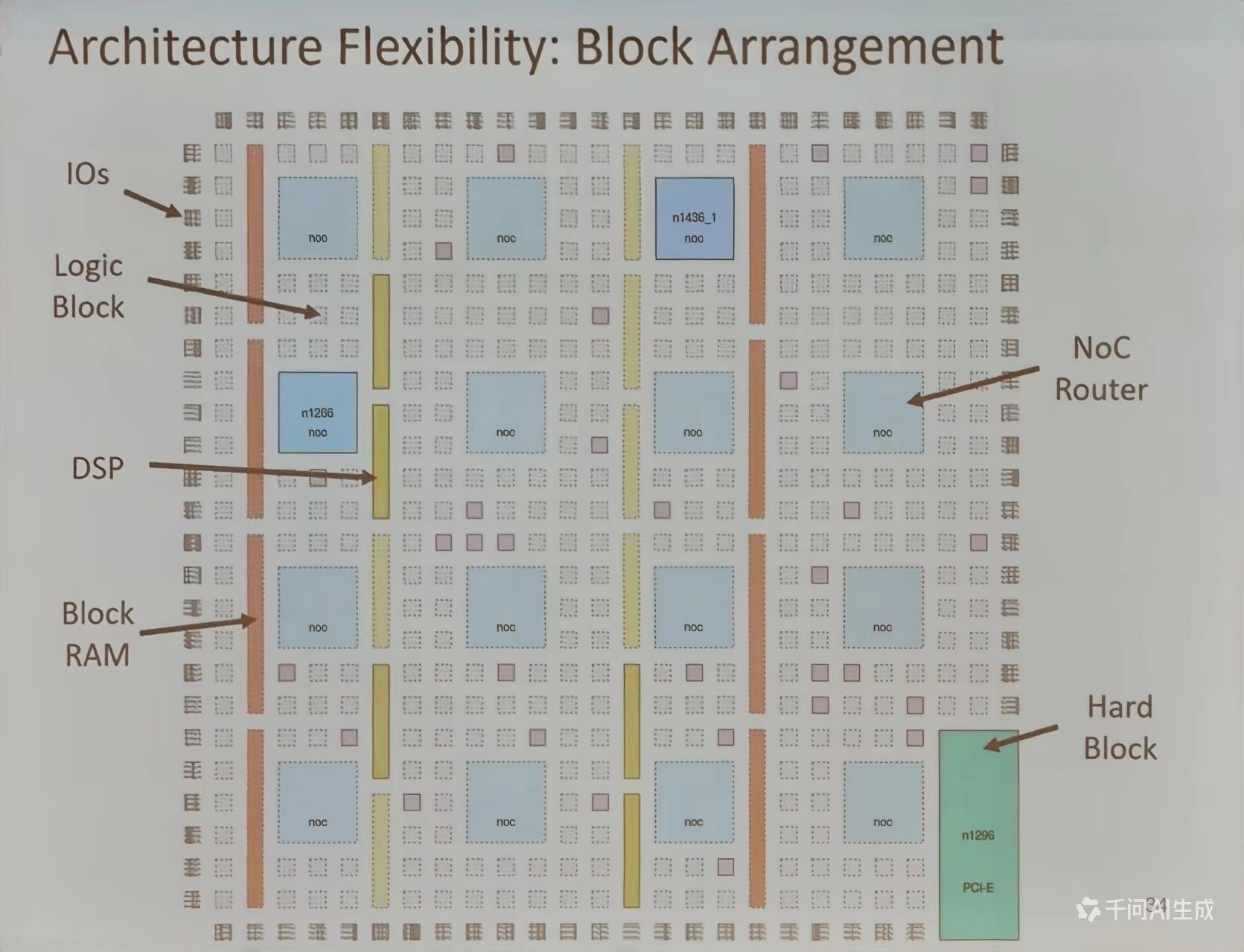
- I/Os: 输入输出接口,位于芯片边缘,负责与外部设备通信
- 逻辑块:主要的逻辑处理单元,分布在芯片内部
- DSP: 数字信号处理模块,用于高效执行数学运算
- Block RAM: 块存储器,提供高速数据存储功能
- NoC Router: 片上网络路由器,用于模块间的高效数据传输
- Hard Block: 硬核模块,如 PCI-E 接口,提供特定的硬件功能
Architecture Flexibility: Routing
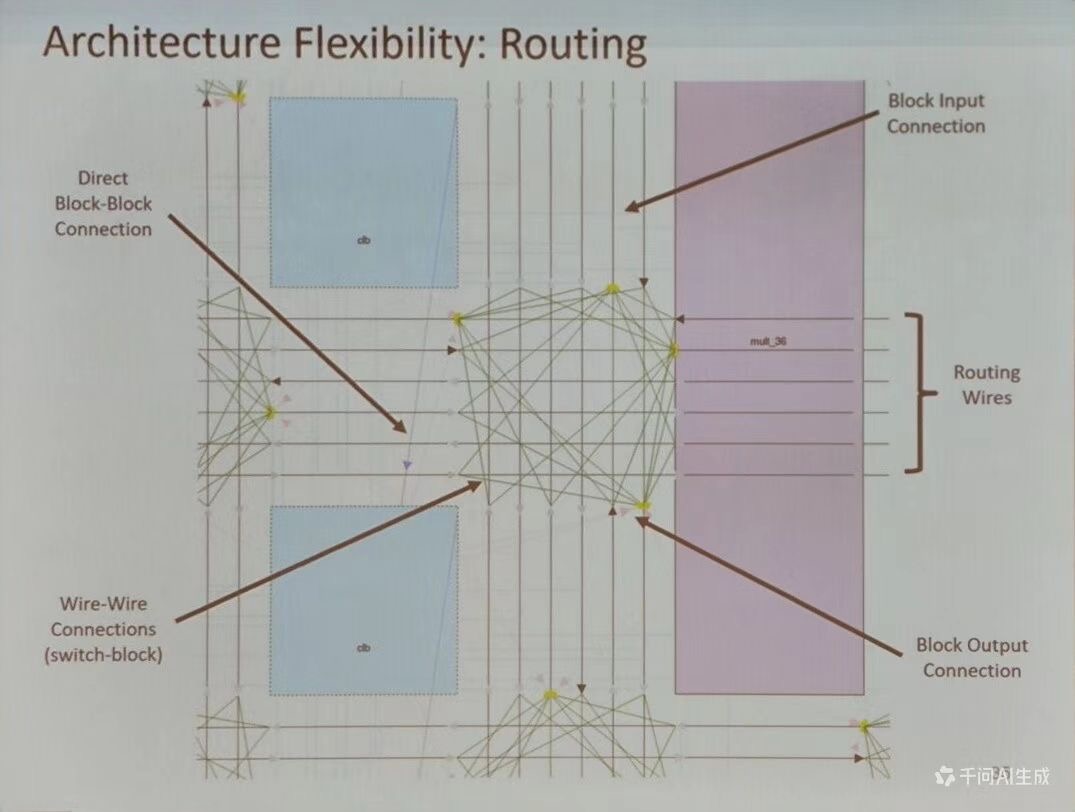
- 直接块间连接 (Direct Block-Block Connection): 模块之间的直接连线,用于快速数据传输
- 线间连接 (Wire-Wire Connection)(switch-block): 通过开关块实现的灵活布线,允许任意连个点之间的连接
- 布线线 (Routing Wires): 遍布芯片的布线资源,支持复杂的数据路径设计
- 块输入/输出连接(Block input/Output Connection):模块与布线资源的接口,确保数据的正确输入和输出
NoC 与 3D 集成技术
芯片强化网络
Srinivasan 团队 (Adaptive Wormhole)提出“Placement Co-Optimization”,将 NoC 路由器与可编程逻辑布线延迟联合建模,关键路径延迟减少 35%
3D 异构
通过硅通孔 (TSV)与微凸块 (ubumps)实现计算-存储堆叠,如 Samsung HBM3-PIM3 将 GDDR6 堆叠与 FPGA 逻辑层,能效提升 4.2 倍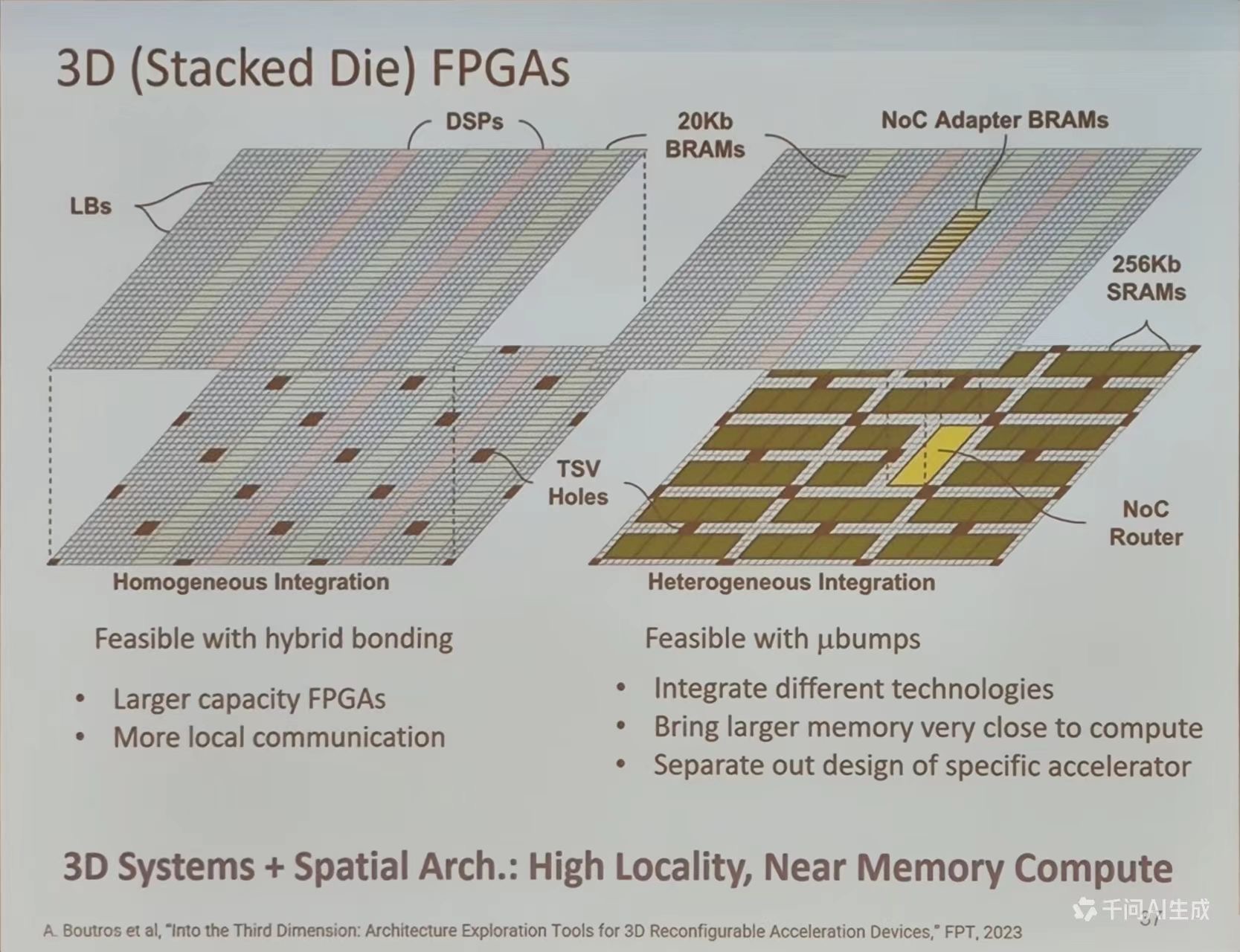
定制化 FPGA 实现
- 开源工具:OpenFPGA 支持从 VTR 架构文件直接生成标准单元布局,NRE (非重复工程成本)降低 90%
- 软核 (Soft Fabric)比全定制方案面积增加 60%,延迟上升 20%,但开发周期从 18 周缩短至 2 周
- Google Edge TPU 的 FP 4 矩阵乘法器,通过专用 LUT 配置实现 8 TOPS/W 的能效突破
吞吐量导向的时空架构 (Throughput-Focused Spatio-Temporal Arch)
晶圆级集成与 Cerebras
传统的 HPC 架构,计算节点集群通过外部网络高延迟互联,众多独立的小芯片通过 PCB 板与片外高延迟内存通信。而 Celebras 晶圆级架构,使十万核心平铺于晶圆,通过片上高带宽 Mesh 网络直接、快速互联,使用单一晶圆巨芯片让计算核心与海量片上 SRAM 集成在一起,访存延时极低。
WSE-3 core架构特点
- 最小化指令和控制开销:采用顺序核心 (In-order core),支持 SIMD (fp 16 和 fp 8),CISC 指令可处理高达 4 D 张量操作数,类似于 DSP 处理器,每个处理器发出一条指令即可保持所有执行单元的忙碌
- 时间灵活性:主线程与 8 个微线程,当主线程等待数据时,可逐周期切换到微线程
- 空间特性:近内存计算,核心的一半是 SRAM,实现数据与计算的紧密集成

近内存计算
Cerebras 的晶圆级引擎是一个单片集成的巨型系统,其核心思路是让计算和存储尽可能近。
- Cerebras WSE-3 (46225 mm^2)集成 2.6 万亿晶体管,相当于 84 颗 GPU 裸片;片上 SRAM 达 44 GB
- 超高的带宽互联:所有核心通过一个二维网格网络网格晶圆上直接互联,实现了极高的带宽 21 PB/s,超越 HBM3 的 0.008 PB/s
解耦计算与存储
- Weight Streaming (权重流):模型参数(权重)存储在专用的外部内存系统 MmeroyX 中,可按需“流式”传输到晶圆芯片上进行计算。
- StreamX 互联架构:将芯片内部的高速 Mesh 网络扩展到多台 CS-2 系统之间,集群规模可达 1.63 亿核心
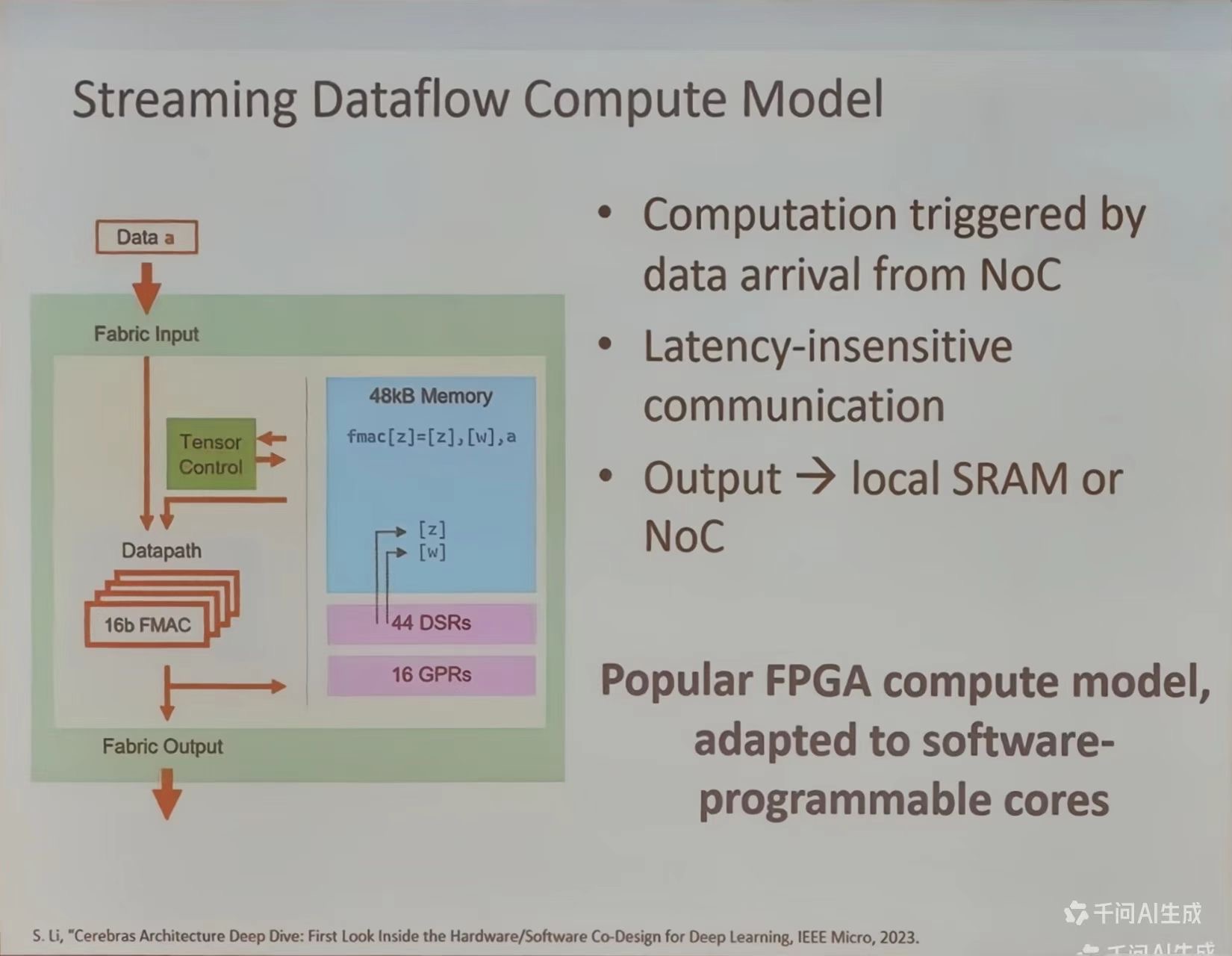
芯片制造
解决良品率、供电、散热三大问题,Cerebras 的解决方案为:
- 冗余设计应对良品率:类似于 Altera FPGA 设计理念,但是细节设计不同,通过冗余链接绕过故障的处理单元 (PE)。在软件上,可以假设一个稍小的完美阵列,无需关心具体的冗余机制
- 垂直供电与水冷散热:采用从晶圆背面垂直分层供电的方式,避免因为距离导致的电压不均。同时,为芯片定制了覆盖了每个计算单元的精密水冷系统,确保散热均匀散热
参考资料
*PPT 及其图示来自 FPT2025讲座——超摩尔与深度学习时代的的空间架构 (Vaughn Betz 教授)